 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows
Apr 13, 2026Existing AI benchmarks lack the fidelity to assess economically meaningful progress on professional workflows. To evaluate frontier AI agents in a high-value, labor-intensive profession, we introduce BankerToolBench (BTB): an open-source benchmark of end-to-end analytical workflows routinely performed by junior investment bankers. To develop an ecologically valid benchmark grounded in representative work environments, we collaborated with 502 investment bankers from leading firms. BTB requires agents to execute senior banker requests by navigating data rooms, using industry tools (market data platform, SEC filings database), and generating multi-file deliverables--including Excel financial models, PowerPoint pitch decks, and PDF/Word reports. Completing a BTB task takes bankers up to 21 hours, underscoring the economic stakes of successfully delegating this work to AI. BTB enables automated evaluation of any LLM or agent, scoring deliverables against 100+ rubric criteria defined by veteran investment bankers to capture stakeholder utility. Testing 9 frontier models, we find that even the best-performing model (GPT-5.4) fails nearly half of the rubric criteria and bankers rate 0% of its outputs as client-ready. Our failure analysis reveals key obstacles (such as breakdowns in cross-artifact consistency) and improvement directions for agentic AI in high-stakes professional workflows.
SciPredict: Can LLMs Predict the Outcomes of Scientific Experiments in Natural Sciences?
Apr 12, 2026Accelerating scientific discovery requires the identification of which experiments would yield the best outcomes before committing resources to costly physical validation. While existing benchmarks evaluate LLMs on scientific knowledge and reasoning, their ability to predict experimental outcomes - a task where AI could significantly exceed human capabilities - remains largely underexplored. We introduce SciPredict, a benchmark comprising 405 tasks derived from recent empirical studies in 33 specialized sub-fields of physics, biology, and chemistry. SciPredict addresses two critical questions: (a) can LLMs predict the outcome of scientific experiments with sufficient accuracy? and (b) can such predictions be reliably used in the scientific research process? Evaluations reveal fundamental limitations on both fronts. Model accuracies are 14-26% and human expert performance is $\approx$20%. Although some frontier models exceed human performance model accuracy is still far below what would enable reliable experimental guidance. Even within the limited performance, models fail to distinguish reliable predictions from unreliable ones, achieving only $\approx$20% accuracy regardless of their confidence or whether they judge outcomes as predictable without physical experimentation. Human experts, in contrast, demonstrate strong calibration: their accuracy increases from $\approx$5% to $\approx$80% as they deem outcomes more predictable without conducting the experiment. SciPredict establishes a rigorous framework demonstrating that superhuman performance in experimental science requires not just better predictions, but better awareness of prediction reliability. For reproducibility all our data and code are provided at https://github.com/scaleapi/scipredict
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Jul 23, 2025
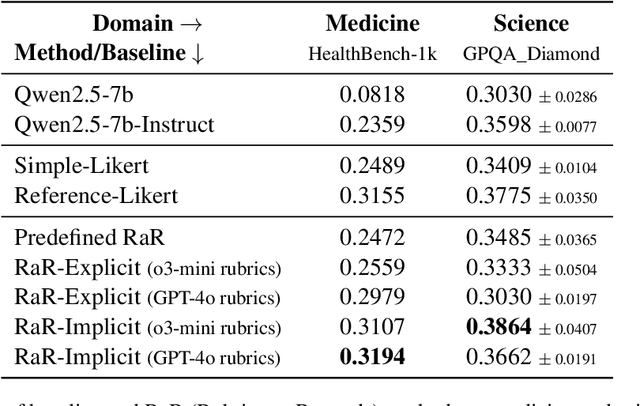
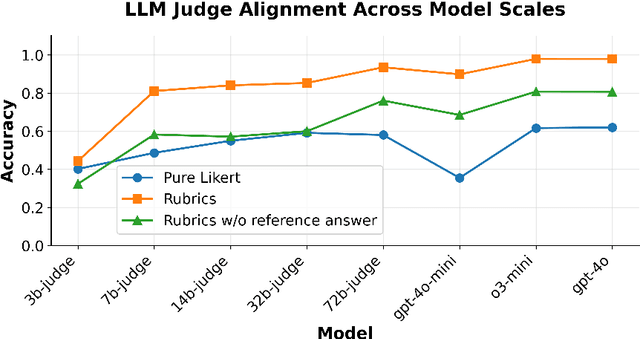
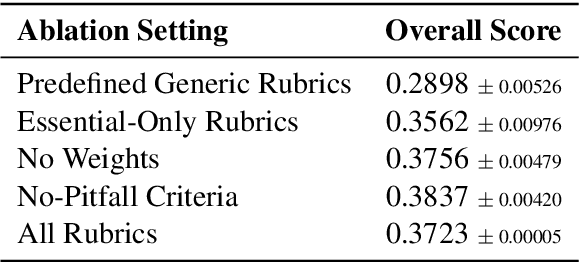
Extending Reinforcement Learning with Verifiable Rewards (RLVR) to real-world tasks often requires balancing objective and subjective evaluation criteria. However, many such tasks lack a single, unambiguous ground truth-making it difficult to define reliable reward signals for post-training language models. While traditional preference-based methods offer a workaround, they rely on opaque reward functions that are difficult to interpret and prone to spurious correlations. We introduce $\textbf{Rubrics as Rewards}$ (RaR), a framework that uses structured, checklist-style rubrics as interpretable reward signals for on-policy training with GRPO. Our best RaR method yields up to a $28\%$ relative improvement on HealthBench-1k compared to simple Likert-based approaches, while matching or surpassing the performance of reward signals derived from expert-written references. By treating rubrics as structured reward signals, we show that RaR enables smaller-scale judge models to better align with human preferences and sustain robust performance across model scales.
QGFN: Controllable Greediness with Action Values
Feb 07, 2024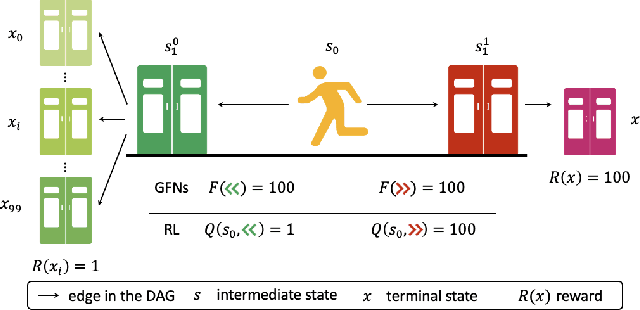

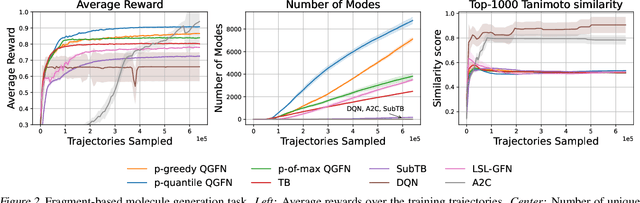
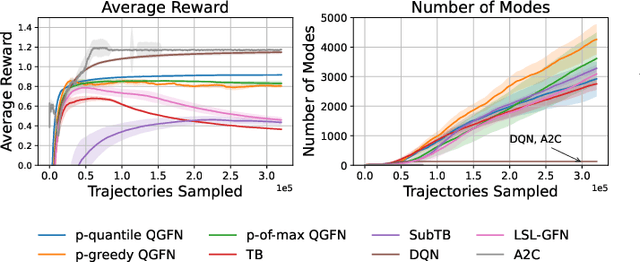
Generative Flow Networks (GFlowNets; GFNs) are a family of reward/energy-based generative methods for combinatorial objects, capable of generating diverse and high-utility samples. However, biasing GFNs towards producing high-utility samples is non-trivial. In this work, we leverage connections between GFNs and reinforcement learning (RL) and propose to combine the GFN policy with an action-value estimate, $Q$, to create greedier sampling policies which can be controlled by a mixing parameter. We show that several variants of the proposed method, QGFN, are able to improve on the number of high-reward samples generated in a variety of tasks without sacrificing diversity.
DGFN: Double Generative Flow Networks
Nov 06, 2023



Deep learning is emerging as an effective tool in drug discovery, with potential applications in both predictive and generative models. Generative Flow Networks (GFlowNets/GFNs) are a recently introduced method recognized for the ability to generate diverse candidates, in particular in small molecule generation tasks. In this work, we introduce double GFlowNets (DGFNs). Drawing inspiration from reinforcement learning and Double Deep Q-Learning, we introduce a target network used to sample trajectories, while updating the main network with these sampled trajectories. Empirical results confirm that DGFNs effectively enhance exploration in sparse reward domains and high-dimensional state spaces, both challenging aspects of de-novo design in drug discovery.
An Empirical Study of the Effectiveness of Using a Replay Buffer on Mode Discovery in GFlowNets
Jul 18, 2023
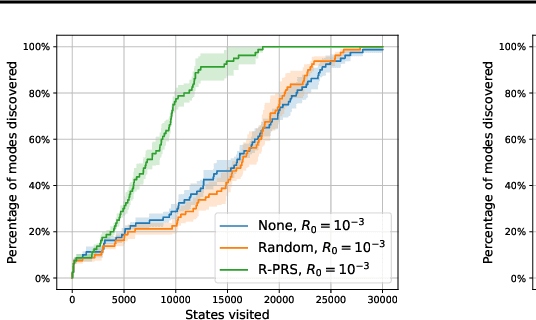


Reinforcement Learning (RL) algorithms aim to learn an optimal policy by iteratively sampling actions to learn how to maximize the total expected return, $R(x)$. GFlowNets are a special class of algorithms designed to generate diverse candidates, $x$, from a discrete set, by learning a policy that approximates the proportional sampling of $R(x)$. GFlowNets exhibit improved mode discovery compared to conventional RL algorithms, which is very useful for applications such as drug discovery and combinatorial search. However, since GFlowNets are a relatively recent class of algorithms, many techniques which are useful in RL have not yet been associated with them. In this paper, we study the utilization of a replay buffer for GFlowNets. We explore empirically various replay buffer sampling techniques and assess the impact on the speed of mode discovery and the quality of the modes discovered. Our experimental results in the Hypergrid toy domain and a molecule synthesis environment demonstrate significant improvements in mode discovery when training with a replay buffer, compared to training only with trajectories generated on-policy.
Bringing the State-of-the-Art to Customers: A Neural Agent Assistant Framework for Customer Service Support
Feb 07, 2023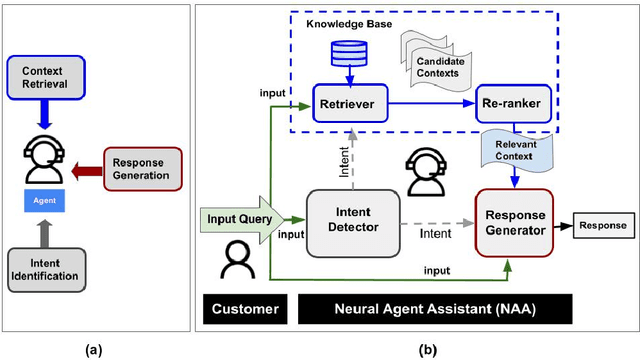
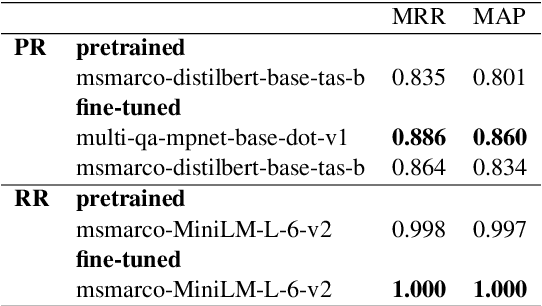
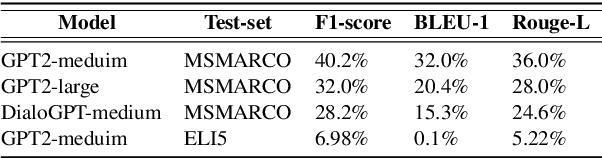
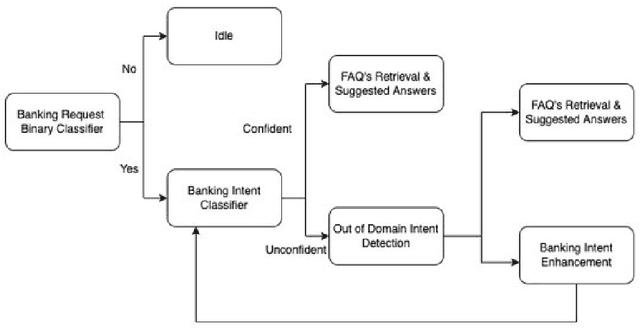
Building Agent Assistants that can help improve customer service support requires inputs from industry users and their customers, as well as knowledge about state-of-the-art Natural Language Processing (NLP) technology. We combine expertise from academia and industry to bridge the gap and build task/domain-specific Neural Agent Assistants (NAA) with three high-level components for: (1) Intent Identification, (2) Context Retrieval, and (3) Response Generation. In this paper, we outline the pipeline of the NAA's core system and also present three case studies in which three industry partners successfully adapt the framework to find solutions to their unique challenges. Our findings suggest that a collaborative process is instrumental in spurring the development of emerging NLP models for Conversational AI tasks in industry. The full reference implementation code and results are available at \url{https://github.com/VectorInstitute/NAA}
Towards Safe Mechanical Ventilation Treatment Using Deep Offline Reinforcement Learning
Oct 05, 2022Mechanical ventilation is a key form of life support for patients with pulmonary impairment. Healthcare workers are required to continuously adjust ventilator settings for each patient, a challenging and time consuming task. Hence, it would be beneficial to develop an automated decision support tool to optimize ventilation treatment. We present DeepVent, a Conservative Q-Learning (CQL) based offline Deep Reinforcement Learning (DRL) agent that learns to predict the optimal ventilator parameters for a patient to promote 90 day survival. We design a clinically relevant intermediate reward that encourages continuous improvement of the patient vitals as well as addresses the challenge of sparse reward in RL. We find that DeepVent recommends ventilation parameters within safe ranges, as outlined in recent clinical trials. The CQL algorithm offers additional safety by mitigating the overestimation of the value estimates of out-of-distribution states/actions. We evaluate our agent using Fitted Q Evaluation (FQE) and demonstrate that it outperforms physicians from the MIMIC-III dataset.
Policy Gradients Incorporating the Future
Aug 11, 2021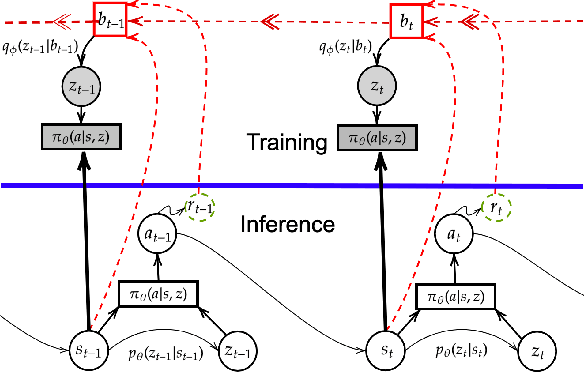


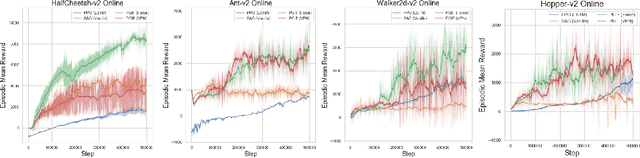
Reasoning about the future -- understanding how decisions in the present time affect outcomes in the future -- is one of the central challenges for reinforcement learning (RL), especially in highly-stochastic or partially observable environments. While predicting the future directly is hard, in this work we introduce a method that allows an agent to "look into the future" without explicitly predicting it. Namely, we propose to allow an agent, during its training on past experience, to observe what \emph{actually} happened in the future at that time, while enforcing an information bottleneck to avoid the agent overly relying on this privileged information. This gives our agent the opportunity to utilize rich and useful information about the future trajectory dynamics in addition to the present. Our method, Policy Gradients Incorporating the Future (PGIF), is easy to implement and versatile, being applicable to virtually any policy gradient algorithm. We apply our proposed method to a number of off-the-shelf RL algorithms and show that PGIF is able to achieve higher reward faster in a variety of online and offline RL domains, as well as sparse-reward and partially observable environments.