 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Nov 10, 2025Deep Research (DR) is an emerging agent application that leverages large language models (LLMs) to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.
Remote Labor Index: Measuring AI Automation of Remote Work
Oct 30, 2025AIs have made rapid progress on research-oriented benchmarks of knowledge and reasoning, but it remains unclear how these gains translate into economic value and automation. To measure this, we introduce the Remote Labor Index (RLI), a broadly multi-sector benchmark comprising real-world, economically valuable projects designed to evaluate end-to-end agent performance in practical settings. AI agents perform near the floor on RLI, with the highest-performing agent achieving an automation rate of 2.5%. These results help ground discussions of AI automation in empirical evidence, setting a common basis for tracking AI impacts and enabling stakeholders to proactively navigate AI-driven labor automation.
On the Challenges of using Reinforcement Learning in Precision Drug Dosing: Delay and Prolongedness of Action Effects
Jan 02, 2023Drug dosing is an important application of AI, which can be formulated as a Reinforcement Learning (RL) problem. In this paper, we identify two major challenges of using RL for drug dosing: delayed and prolonged effects of administering medications, which break the Markov assumption of the RL framework. We focus on prolongedness and define PAE-POMDP (Prolonged Action Effect-Partially Observable Markov Decision Process), a subclass of POMDPs in which the Markov assumption does not hold specifically due to prolonged effects of actions. Motivated by the pharmacology literature, we propose a simple and effective approach to converting drug dosing PAE-POMDPs into MDPs, enabling the use of the existing RL algorithms to solve such problems. We validate the proposed approach on a toy task, and a challenging glucose control task, for which we devise a clinically-inspired reward function. Our results demonstrate that: (1) the proposed method to restore the Markov assumption leads to significant improvements over a vanilla baseline; (2) the approach is competitive with recurrent policies which may inherently capture the prolonged effect of actions; (3) it is remarkably more time and memory efficient than the recurrent baseline and hence more suitable for real-time dosing control systems; and (4) it exhibits favorable qualitative behavior in our policy analysis.
Towards Safe Mechanical Ventilation Treatment Using Deep Offline Reinforcement Learning
Oct 05, 2022Mechanical ventilation is a key form of life support for patients with pulmonary impairment. Healthcare workers are required to continuously adjust ventilator settings for each patient, a challenging and time consuming task. Hence, it would be beneficial to develop an automated decision support tool to optimize ventilation treatment. We present DeepVent, a Conservative Q-Learning (CQL) based offline Deep Reinforcement Learning (DRL) agent that learns to predict the optimal ventilator parameters for a patient to promote 90 day survival. We design a clinically relevant intermediate reward that encourages continuous improvement of the patient vitals as well as addresses the challenge of sparse reward in RL. We find that DeepVent recommends ventilation parameters within safe ranges, as outlined in recent clinical trials. The CQL algorithm offers additional safety by mitigating the overestimation of the value estimates of out-of-distribution states/actions. We evaluate our agent using Fitted Q Evaluation (FQE) and demonstrate that it outperforms physicians from the MIMIC-III dataset.
Active MR k-space Sampling with Reinforcement Learning
Jul 20, 2020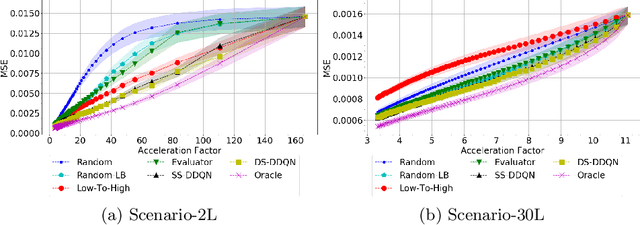
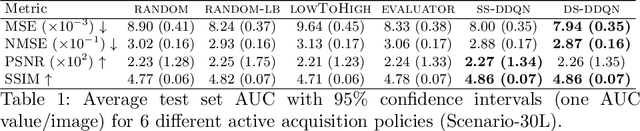
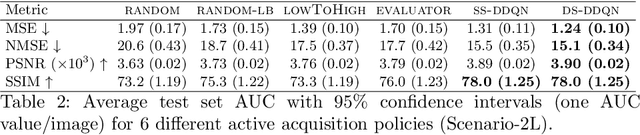
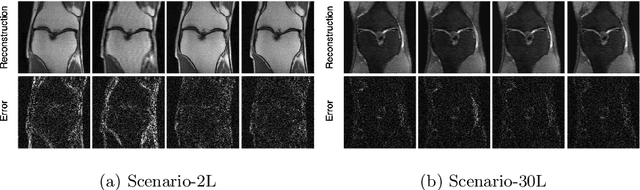
Deep learning approaches have recently shown great promise in accelerating magnetic resonance image (MRI) acquisition. The majority of existing work have focused on designing better reconstruction models given a pre-determined acquisition trajectory, ignoring the question of trajectory optimization. In this paper, we focus on learning acquisition trajectories given a fixed image reconstruction model. We formulate the problem as a sequential decision process and propose the use of reinforcement learning to solve it. Experiments on a large scale public MRI dataset of knees show that our proposed models significantly outperform the state-of-the-art in active MRI acquisition, over a large range of acceleration factors.
Option-critic in cooperative multi-agent systems
Jan 06, 2020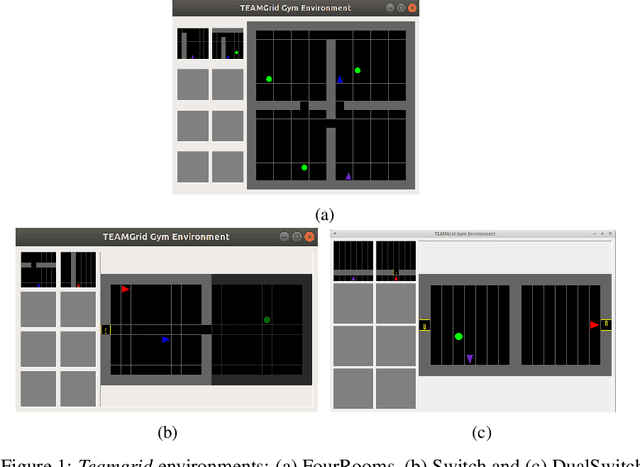
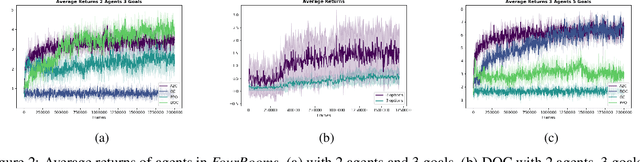
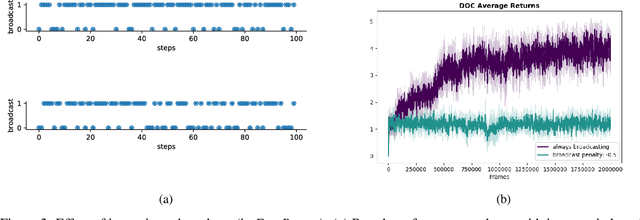
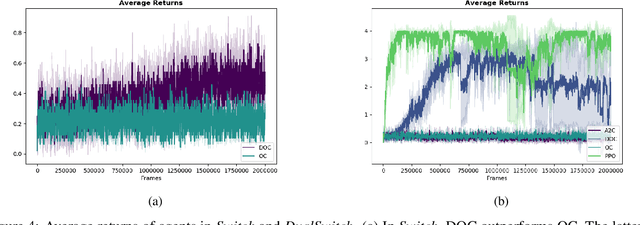
In this paper, we investigate learning temporal abstractions in cooperative multi-agent systems using the options framework (Sutton et al, 1999) and provide a model-free algorithm for this problem. First, we address the planning problem for the decentralized POMDP represented by the multi-agent system, by introducing a common information approach. We use common beliefs and broadcasting to solve an equivalent centralized POMDP problem. Then, we propose the Distributed Option Critic (DOC) algorithm, motivated by the work of Bacon et al (2017) in the single-agent setting. Our approach uses centralized option evaluation and decentralized intra-option improvement. We analyze theoretically the asymptotic convergence of DOC and validate its performance in grid-world environments, where we implement DOC using a deep neural network. Our experiments show that DOC performs competitively with state-of-the-art algorithms and that it is scalable when the number of agents increases.