 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeoIRL: Robust Adversarial Inverse Reinforcement Learning with Temporally Extended Actions
Feb 20, 2020
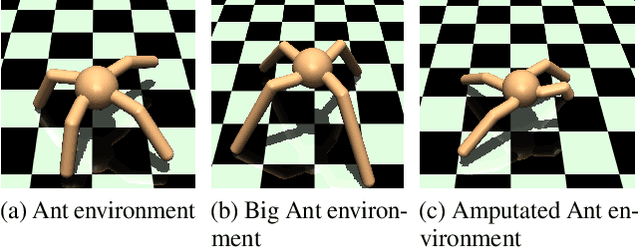

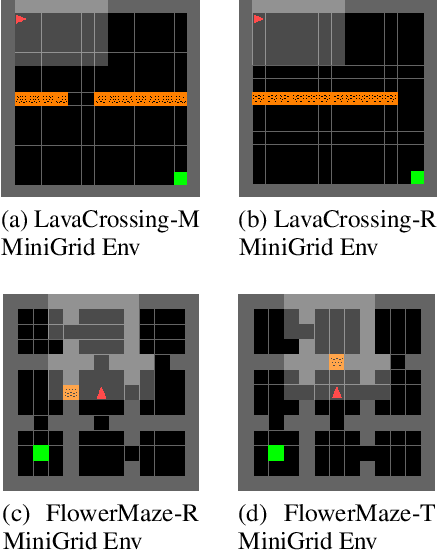
Explicit engineering of reward functions for given environments has been a major hindrance to reinforcement learning methods. While Inverse Reinforcement Learning (IRL) is a solution to recover reward functions from demonstrations only, these learned rewards are generally heavily \textit{entangled} with the dynamics of the environment and therefore not portable or \emph{robust} to changing environments. Modern adversarial methods have yielded some success in reducing reward entanglement in the IRL setting. In this work, we leverage one such method, Adversarial Inverse Reinforcement Learning (AIRL), to propose an algorithm that learns hierarchical disentangled rewards with a policy over options. We show that this method has the ability to learn \emph{generalizable} policies and reward functions in complex transfer learning tasks, while yielding results in continuous control benchmarks that are comparable to those of the state-of-the-art methods.
Option-critic in cooperative multi-agent systems
Jan 06, 2020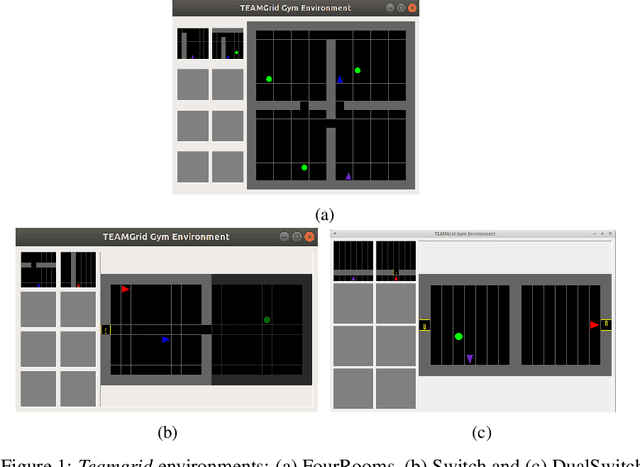
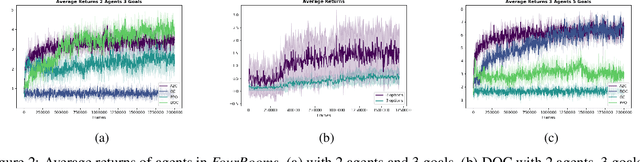
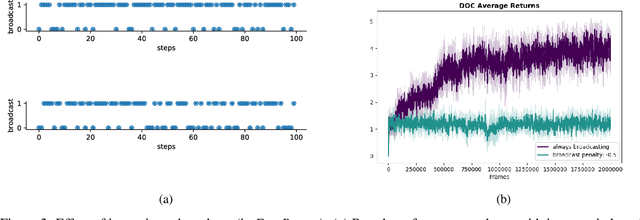
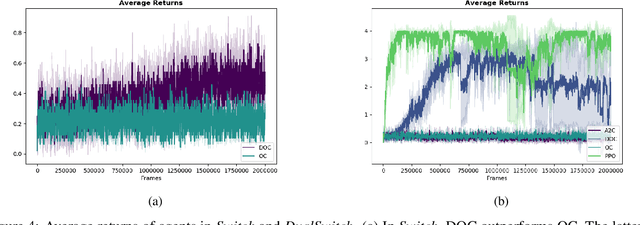
In this paper, we investigate learning temporal abstractions in cooperative multi-agent systems using the options framework (Sutton et al, 1999) and provide a model-free algorithm for this problem. First, we address the planning problem for the decentralized POMDP represented by the multi-agent system, by introducing a common information approach. We use common beliefs and broadcasting to solve an equivalent centralized POMDP problem. Then, we propose the Distributed Option Critic (DOC) algorithm, motivated by the work of Bacon et al (2017) in the single-agent setting. Our approach uses centralized option evaluation and decentralized intra-option improvement. We analyze theoretically the asymptotic convergence of DOC and validate its performance in grid-world environments, where we implement DOC using a deep neural network. Our experiments show that DOC performs competitively with state-of-the-art algorithms and that it is scalable when the number of agents increases.
Avoidance Learning Using Observational Reinforcement Learning
Sep 24, 2019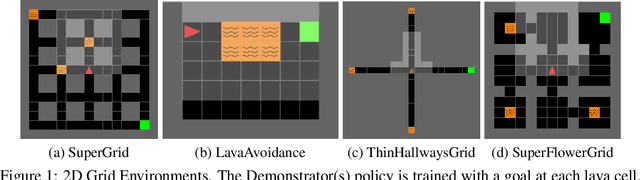
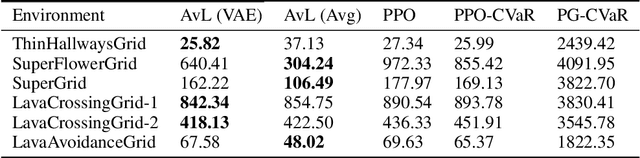


Imitation learning seeks to learn an expert policy from sampled demonstrations. However, in the real world, it is often difficult to find a perfect expert and avoiding dangerous behaviors becomes relevant for safety reasons. We present the idea of \textit{learning to avoid}, an objective opposite to imitation learning in some sense, where an agent learns to avoid a demonstrator policy given an environment. We define avoidance learning as the process of optimizing the agent's reward while avoiding dangerous behaviors given by a demonstrator. In this work we develop a framework of avoidance learning by defining a suitable objective function for these problems which involves the \emph{distance} of state occupancy distributions of the expert and demonstrator policies. We use density estimates for state occupancy measures and use the aforementioned distance as the reward bonus for avoiding the demonstrator. We validate our theory with experiments using a wide range of partially observable environments. Experimental results show that we are able to improve sample efficiency during training compared to state of the art policy optimization and safety methods.