 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCracking the Code of Action: a Generative Approach to Affordances for Reinforcement Learning
Apr 24, 2025Agents that can autonomously navigate the web through a graphical user interface (GUI) using a unified action space (e.g., mouse and keyboard actions) can require very large amounts of domain-specific expert demonstrations to achieve good performance. Low sample efficiency is often exacerbated in sparse-reward and large-action-space environments, such as a web GUI, where only a few actions are relevant in any given situation. In this work, we consider the low-data regime, with limited or no access to expert behavior. To enable sample-efficient learning, we explore the effect of constraining the action space through $\textit{intent-based affordances}$ -- i.e., considering in any situation only the subset of actions that achieve a desired outcome. We propose $\textbf{Code as Generative Affordances}$ $(\textbf{$\texttt{CoGA}$})$, a method that leverages pre-trained vision-language models (VLMs) to generate code that determines affordable actions through implicit intent-completion functions and using a fully-automated program generation and verification pipeline. These programs are then used in-the-loop of a reinforcement learning agent to return a set of affordances given a pixel observation. By greatly reducing the number of actions that an agent must consider, we demonstrate on a wide range of tasks in the MiniWob++ benchmark that: $\textbf{1)}$ $\texttt{CoGA}$ is orders of magnitude more sample efficient than its RL agent, $\textbf{2)}$ $\texttt{CoGA}$'s programs can generalize within a family of tasks, and $\textbf{3)}$ $\texttt{CoGA}$ performs better or on par compared with behavior cloning when a small number of expert demonstrations is available.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Code as Reward: Empowering Reinforcement Learning with VLMs
Feb 07, 2024



Pre-trained Vision-Language Models (VLMs) are able to understand visual concepts, describe and decompose complex tasks into sub-tasks, and provide feedback on task completion. In this paper, we aim to leverage these capabilities to support the training of reinforcement learning (RL) agents. In principle, VLMs are well suited for this purpose, as they can naturally analyze image-based observations and provide feedback (reward) on learning progress. However, inference in VLMs is computationally expensive, so querying them frequently to compute rewards would significantly slowdown the training of an RL agent. To address this challenge, we propose a framework named Code as Reward (VLM-CaR). VLM-CaR produces dense reward functions from VLMs through code generation, thereby significantly reducing the computational burden of querying the VLM directly. We show that the dense rewards generated through our approach are very accurate across a diverse set of discrete and continuous environments, and can be more effective in training RL policies than the original sparse environment rewards.
Multi-Environment Pretraining Enables Transfer to Action Limited Datasets
Dec 05, 2022Using massive datasets to train large-scale models has emerged as a dominant approach for broad generalization in natural language and vision applications. In reinforcement learning, however, a key challenge is that available data of sequential decision making is often not annotated with actions - for example, videos of game-play are much more available than sequences of frames paired with their logged game controls. We propose to circumvent this challenge by combining large but sparsely-annotated datasets from a \emph{target} environment of interest with fully-annotated datasets from various other \emph{source} environments. Our method, Action Limited PreTraining (ALPT), leverages the generalization capabilities of inverse dynamics modelling (IDM) to label missing action data in the target environment. We show that utilizing even one additional environment dataset of labelled data during IDM pretraining gives rise to substantial improvements in generating action labels for unannotated sequences. We evaluate our method on benchmark game-playing environments and show that we can significantly improve game performance and generalization capability compared to other approaches, using annotated datasets equivalent to only $12$ minutes of gameplay. Highlighting the power of IDM, we show that these benefits remain even when target and source environments share no common actions.
Policy Gradients Incorporating the Future
Aug 11, 2021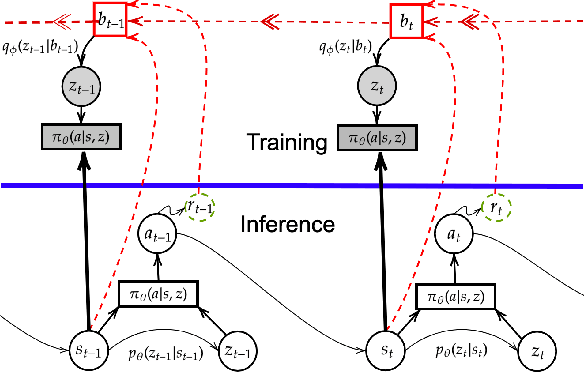


Reasoning about the future -- understanding how decisions in the present time affect outcomes in the future -- is one of the central challenges for reinforcement learning (RL), especially in highly-stochastic or partially observable environments. While predicting the future directly is hard, in this work we introduce a method that allows an agent to "look into the future" without explicitly predicting it. Namely, we propose to allow an agent, during its training on past experience, to observe what \emph{actually} happened in the future at that time, while enforcing an information bottleneck to avoid the agent overly relying on this privileged information. This gives our agent the opportunity to utilize rich and useful information about the future trajectory dynamics in addition to the present. Our method, Policy Gradients Incorporating the Future (PGIF), is easy to implement and versatile, being applicable to virtually any policy gradient algorithm. We apply our proposed method to a number of off-the-shelf RL algorithms and show that PGIF is able to achieve higher reward faster in a variety of online and offline RL domains, as well as sparse-reward and partially observable environments.
oIRL: Robust Adversarial Inverse Reinforcement Learning with Temporally Extended Actions
Feb 20, 2020

Explicit engineering of reward functions for given environments has been a major hindrance to reinforcement learning methods. While Inverse Reinforcement Learning (IRL) is a solution to recover reward functions from demonstrations only, these learned rewards are generally heavily \textit{entangled} with the dynamics of the environment and therefore not portable or \emph{robust} to changing environments. Modern adversarial methods have yielded some success in reducing reward entanglement in the IRL setting. In this work, we leverage one such method, Adversarial Inverse Reinforcement Learning (AIRL), to propose an algorithm that learns hierarchical disentangled rewards with a policy over options. We show that this method has the ability to learn \emph{generalizable} policies and reward functions in complex transfer learning tasks, while yielding results in continuous control benchmarks that are comparable to those of the state-of-the-art methods.
Avoidance Learning Using Observational Reinforcement Learning
Sep 24, 2019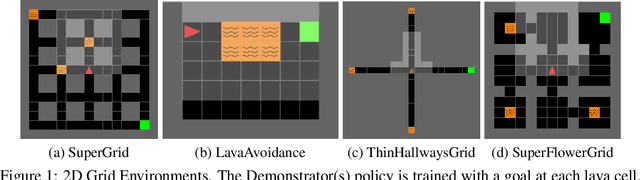


Imitation learning seeks to learn an expert policy from sampled demonstrations. However, in the real world, it is often difficult to find a perfect expert and avoiding dangerous behaviors becomes relevant for safety reasons. We present the idea of \textit{learning to avoid}, an objective opposite to imitation learning in some sense, where an agent learns to avoid a demonstrator policy given an environment. We define avoidance learning as the process of optimizing the agent's reward while avoiding dangerous behaviors given by a demonstrator. In this work we develop a framework of avoidance learning by defining a suitable objective function for these problems which involves the \emph{distance} of state occupancy distributions of the expert and demonstrator policies. We use density estimates for state occupancy measures and use the aforementioned distance as the reward bonus for avoiding the demonstrator. We validate our theory with experiments using a wide range of partially observable environments. Experimental results show that we are able to improve sample efficiency during training compared to state of the art policy optimization and safety methods.
Support vector comparison machines
Dec 20, 2017
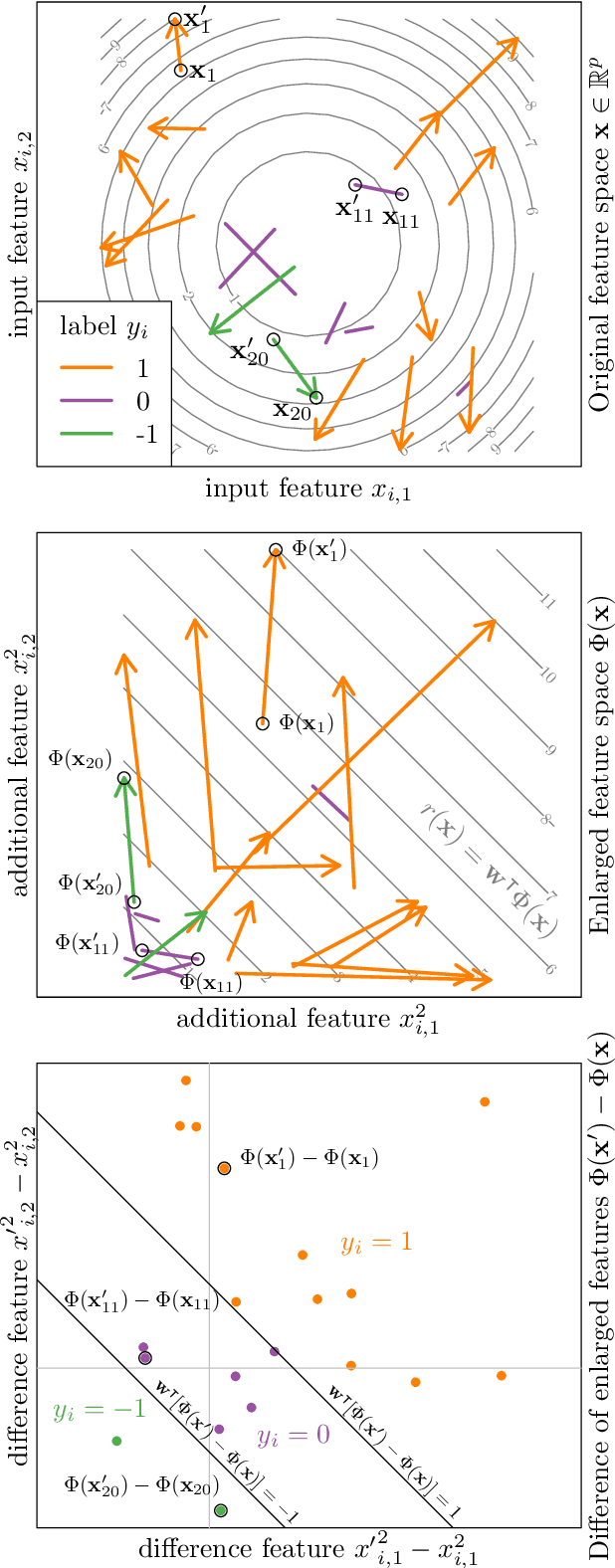
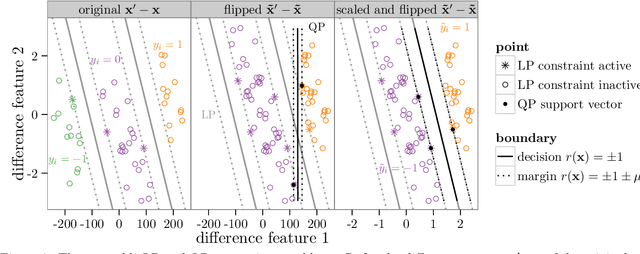

In ranking problems, the goal is to learn a ranking function from labeled pairs of input points. In this paper, we consider the related comparison problem, where the label indicates which element of the pair is better, or if there is no significant difference. We cast the learning problem as a margin maximization, and show that it can be solved by converting it to a standard SVM. We use simulated nonlinear patterns, a real learning to rank sushi data set, and a chess data set to show that our proposed SVMcompare algorithm outperforms SVMrank when there are equality pairs.