 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimMerge: Learning to Select Merge Operators from Similarity Signals
Jan 14, 2026Model merging enables multiple large language models (LLMs) to be combined into a single model while preserving performance. This makes it a valuable tool in LLM development, offering a competitive alternative to multi-task training. However, merging can be difficult at scale, as successful merging requires choosing the right merge operator, selecting the right models, and merging them in the right order. This often leads researchers to run expensive merge-and-evaluate searches to select the best merge. In this work, we provide an alternative by introducing \simmerge{}, \emph{a predictive merge-selection method} that selects the best merge using inexpensive, task-agnostic similarity signals between models. From a small set of unlabeled probes, we compute functional and structural features and use them to predict the performance of a given 2-way merge. Using these predictions, \simmerge{} selects the best merge operator, the subset of models to merge, and the merge order, eliminating the expensive merge-and-evaluate loop. We demonstrate that we surpass standard merge-operator performance on 2-way merges of 7B-parameter LLMs, and that \simmerge{} generalizes to multi-way merges and 111B-parameter LLM merges without retraining. Additionally, we present a bandit variant that supports adding new tasks, models, and operators on the fly. Our results suggest that learning how to merge is a practical route to scalable model composition when checkpoint catalogs are large and evaluation budgets are tight.
Programming by Backprop: LLMs Acquire Reusable Algorithmic Abstractions During Code Training
Jun 23, 2025Training large language models (LLMs) on source code significantly enhances their general-purpose reasoning abilities, but the mechanisms underlying this generalisation are poorly understood. In this paper, we propose Programming by Backprop (PBB) as a potential driver of this effect - teaching a model to evaluate a program for inputs by training on its source code alone, without ever seeing I/O examples. To explore this idea, we finetune LLMs on two sets of programs representing simple maths problems and algorithms: one with source code and I/O examples (w/ IO), the other with source code only (w/o IO). We find evidence that LLMs have some ability to evaluate w/o IO programs for inputs in a range of experimental settings, and make several observations. Firstly, PBB works significantly better when programs are provided as code rather than semantically equivalent language descriptions. Secondly, LLMs can produce outputs for w/o IO programs directly, by implicitly evaluating the program within the forward pass, and more reliably when stepping through the program in-context via chain-of-thought. We further show that PBB leads to more robust evaluation of programs across inputs than training on I/O pairs drawn from a distribution that mirrors naturally occurring data. Our findings suggest a mechanism for enhanced reasoning through code training: it allows LLMs to internalise reusable algorithmic abstractions. Significant scope remains for future work to enable LLMs to more effectively learn from symbolic procedures, and progress in this direction opens other avenues like model alignment by training on formal constitutional principles.
Calibrated Value-Aware Model Learning with Stochastic Environment Models
May 28, 2025The idea of value-aware model learning, that models should produce accurate value estimates, has gained prominence in model-based reinforcement learning. The MuZero loss, which penalizes a model's value function prediction compared to the ground-truth value function, has been utilized in several prominent empirical works in the literature. However, theoretical investigation into its strengths and weaknesses is limited. In this paper, we analyze the family of value-aware model learning losses, which includes the popular MuZero loss. We show that these losses, as normally used, are uncalibrated surrogate losses, which means that they do not always recover the correct model and value function. Building on this insight, we propose corrections to solve this issue. Furthermore, we investigate the interplay between the loss calibration, latent model architectures, and auxiliary losses that are commonly employed when training MuZero-style agents. We show that while deterministic models can be sufficient to predict accurate values, learning calibrated stochastic models is still advantageous.
Aya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
If You Can't Use Them, Recycle Them: Optimizing Merging at Scale Mitigates Performance Tradeoffs
Dec 05, 2024
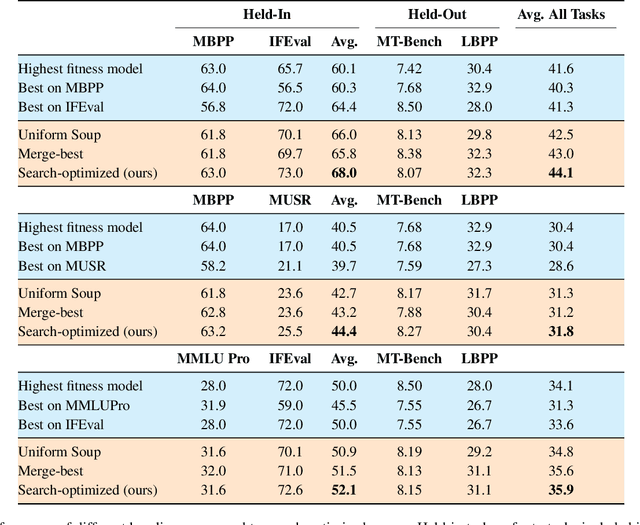
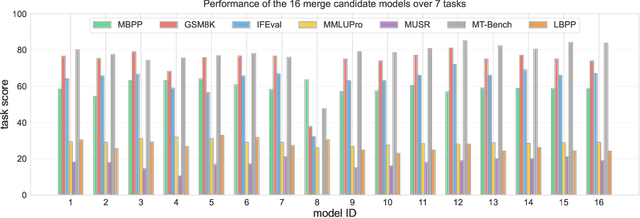
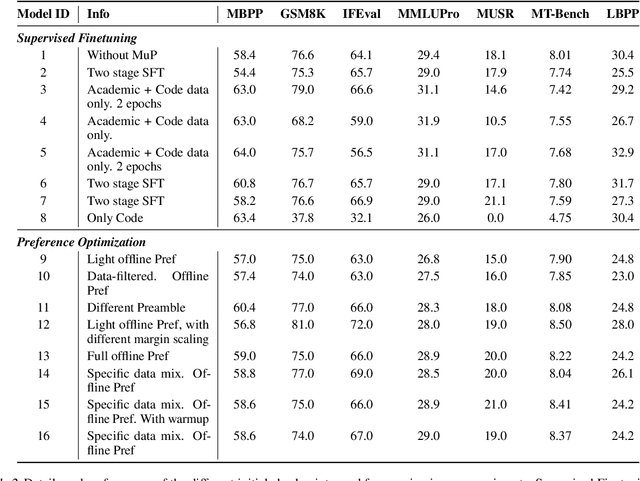
Model merging has shown great promise at combining expert models, but the benefit of merging is unclear when merging ``generalist'' models trained on many tasks. We explore merging in the context of large ($\sim100$B) models, by \textit{recycling} checkpoints that exhibit tradeoffs among different tasks. Such checkpoints are often created in the process of developing a frontier model, and many suboptimal ones are usually discarded. Given a pool of model checkpoints obtained from different training runs (e.g., different stages, objectives, hyperparameters, and data mixtures), which naturally show tradeoffs across different language capabilities (e.g., instruction following vs. code generation), we investigate whether merging can recycle such suboptimal models into a Pareto-optimal one. Our optimization algorithm tunes the weight of each checkpoint in a linear combination, resulting in a Pareto-optimal models that outperforms both individual models and merge-based baselines. Further analysis shows that good merges tend to include almost all checkpoints with with non-zero weights, indicating that even seemingly bad initial checkpoints can contribute to good final merges.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Mix Data or Merge Models? Optimizing for Diverse Multi-Task Learning
Oct 14, 2024



Large Language Models (LLMs) have been adopted and deployed worldwide for a broad variety of applications. However, ensuring their safe use remains a significant challenge. Preference training and safety measures often overfit to harms prevalent in Western-centric datasets, and safety protocols frequently fail to extend to multilingual settings. In this work, we explore model merging in a diverse multi-task setting, combining safety and general-purpose tasks within a multilingual context. Each language introduces unique and varied learning challenges across tasks. We find that objective-based merging is more effective than mixing data, with improvements of up to 8% and 10% in general performance and safety respectively. We also find that language-based merging is highly effective -- by merging monolingually fine-tuned models, we achieve a 4% increase in general performance and 7% reduction in harm across all languages on top of the data mixtures method using the same available data. Overall, our comprehensive study of merging approaches provides a useful framework for building strong and safe multilingual models.
RLHF Can Speak Many Languages: Unlocking Multilingual Preference Optimization for LLMs
Jul 02, 2024Preference optimization techniques have become a standard final stage for training state-of-art large language models (LLMs). However, despite widespread adoption, the vast majority of work to-date has focused on first-class citizen languages like English and Chinese. This captures a small fraction of the languages in the world, but also makes it unclear which aspects of current state-of-the-art research transfer to a multilingual setting. In this work, we perform an exhaustive study to achieve a new state-of-the-art in aligning multilingual LLMs. We introduce a novel, scalable method for generating high-quality multilingual feedback data to balance data coverage. We establish the benefits of cross-lingual transfer and increased dataset size in preference training. Our preference-trained model achieves a 54.4% win-rate against Aya 23 8B, the current state-of-the-art multilingual LLM in its parameter class, and a 69.5% win-rate or higher against widely used models like Gemma-1.1-7B-it, Llama-3-8B-Instruct, Mistral-7B-Instruct-v0.3. As a result of our study, we expand the frontier of alignment techniques to 23 languages covering half of the world's population.
Averaging log-likelihoods in direct alignment
Jun 27, 2024



To better align Large Language Models (LLMs) with human judgment, Reinforcement Learning from Human Feedback (RLHF) learns a reward model and then optimizes it using regularized RL. Recently, direct alignment methods were introduced to learn such a fine-tuned model directly from a preference dataset without computing a proxy reward function. These methods are built upon contrastive losses involving the log-likelihood of (dis)preferred completions according to the trained model. However, completions have various lengths, and the log-likelihood is not length-invariant. On the other side, the cross-entropy loss used in supervised training is length-invariant, as batches are typically averaged token-wise. To reconcile these approaches, we introduce a principled approach for making direct alignment length-invariant. Formally, we introduce a new averaging operator, to be composed with the optimality operator giving the best policy for the underlying RL problem. It translates into averaging the log-likelihood within the loss. We empirically study the effect of such averaging, observing a trade-off between the length of generations and their scores.