 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Graph Search for Goal-Conditioned Reinforcement Learning
Oct 08, 2025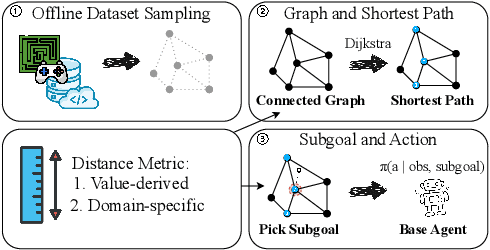

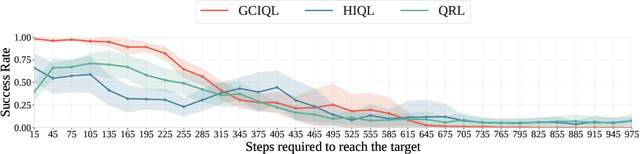

Offline goal-conditioned reinforcement learning (GCRL) trains policies that reach user-specified goals at test time, providing a simple, unsupervised, domain-agnostic way to extract diverse behaviors from unlabeled, reward-free datasets. Nonetheless, long-horizon decision making remains difficult for GCRL agents due to temporal credit assignment and error accumulation, and the offline setting amplifies these effects. To alleviate this issue, we introduce Test-Time Graph Search (TTGS), a lightweight planning approach to solve the GCRL task. TTGS accepts any state-space distance or cost signal, builds a weighted graph over dataset states, and performs fast search to assemble a sequence of subgoals that a frozen policy executes. When the base learner is value-based, the distance is derived directly from the learned goal-conditioned value function, so no handcrafted metric is needed. TTGS requires no changes to training, no additional supervision, no online interaction, and no privileged information, and it runs entirely at inference. On the OGBench benchmark, TTGS improves success rates of multiple base learners on challenging locomotion tasks, demonstrating the benefit of simple metric-guided test-time planning for offline GCRL.
Calibrated Value-Aware Model Learning with Stochastic Environment Models
May 28, 2025The idea of value-aware model learning, that models should produce accurate value estimates, has gained prominence in model-based reinforcement learning. The MuZero loss, which penalizes a model's value function prediction compared to the ground-truth value function, has been utilized in several prominent empirical works in the literature. However, theoretical investigation into its strengths and weaknesses is limited. In this paper, we analyze the family of value-aware model learning losses, which includes the popular MuZero loss. We show that these losses, as normally used, are uncalibrated surrogate losses, which means that they do not always recover the correct model and value function. Building on this insight, we propose corrections to solve this issue. Furthermore, we investigate the interplay between the loss calibration, latent model architectures, and auxiliary losses that are commonly employed when training MuZero-style agents. We show that while deterministic models can be sufficient to predict accurate values, learning calibrated stochastic models is still advantageous.
Temporal-Difference Learning Using Distributed Error Signals
Nov 06, 2024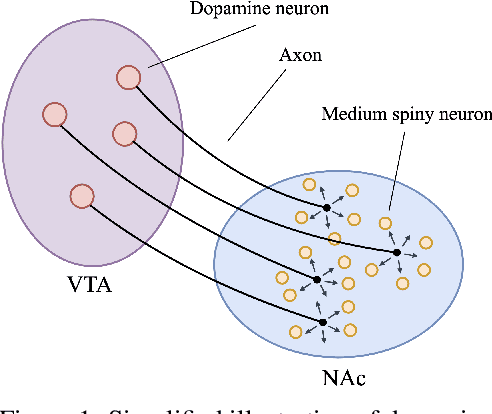
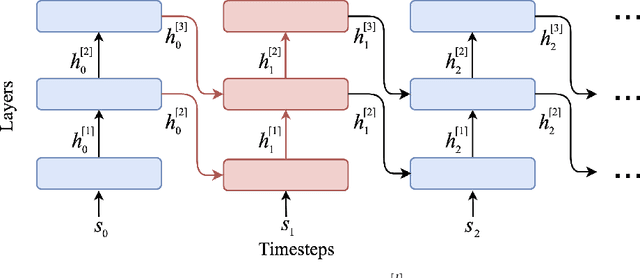

A computational problem in biological reward-based learning is how credit assignment is performed in the nucleus accumbens (NAc). Much research suggests that NAc dopamine encodes temporal-difference (TD) errors for learning value predictions. However, dopamine is synchronously distributed in regionally homogeneous concentrations, which does not support explicit credit assignment (like used by backpropagation). It is unclear whether distributed errors alone are sufficient for synapses to make coordinated updates to learn complex, nonlinear reward-based learning tasks. We design a new deep Q-learning algorithm, Artificial Dopamine, to computationally demonstrate that synchronously distributed, per-layer TD errors may be sufficient to learn surprisingly complex RL tasks. We empirically evaluate our algorithm on MinAtar, the DeepMind Control Suite, and classic control tasks, and show it often achieves comparable performance to deep RL algorithms that use backpropagation.
When does Self-Prediction help? Understanding Auxiliary Tasks in Reinforcement Learning
Jun 25, 2024We investigate the impact of auxiliary learning tasks such as observation reconstruction and latent self-prediction on the representation learning problem in reinforcement learning. We also study how they interact with distractions and observation functions in the MDP. We provide a theoretical analysis of the learning dynamics of observation reconstruction, latent self-prediction, and TD learning in the presence of distractions and observation functions under linear model assumptions. With this formalization, we are able to explain why latent-self prediction is a helpful \emph{auxiliary task}, while observation reconstruction can provide more useful features when used in isolation. Our empirical analysis shows that the insights obtained from our learning dynamics framework predicts the behavior of these loss functions beyond the linear model assumption in non-linear neural networks. This reinforces the usefulness of the linear model framework not only for theoretical analysis, but also practical benefit for applied problems.
Dissecting Deep RL with High Update Ratios: Combatting Value Overestimation and Divergence
Mar 09, 2024We show that deep reinforcement learning can maintain its ability to learn without resetting network parameters in settings where the number of gradient updates greatly exceeds the number of environment samples. Under such large update-to-data ratios, a recent study by Nikishin et al. (2022) suggested the emergence of a primacy bias, in which agents overfit early interactions and downplay later experience, impairing their ability to learn. In this work, we dissect the phenomena underlying the primacy bias. We inspect the early stages of training that ought to cause the failure to learn and find that a fundamental challenge is a long-standing acquaintance: value overestimation. Overinflated Q-values are found not only on out-of-distribution but also in-distribution data and can be traced to unseen action prediction propelled by optimizer momentum. We employ a simple unit-ball normalization that enables learning under large update ratios, show its efficacy on the widely used dm_control suite, and obtain strong performance on the challenging dog tasks, competitive with model-based approaches. Our results question, in parts, the prior explanation for sub-optimal learning due to overfitting on early data.
Queer In AI: A Case Study in Community-Led Participatory AI
Apr 10, 2023We present Queer in AI as a case study for community-led participatory design in AI. We examine how participatory design and intersectional tenets started and shaped this community's programs over the years. We discuss different challenges that emerged in the process, look at ways this organization has fallen short of operationalizing participatory and intersectional principles, and then assess the organization's impact. Queer in AI provides important lessons and insights for practitioners and theorists of participatory methods broadly through its rejection of hierarchy in favor of decentralization, success at building aid and programs by and for the queer community, and effort to change actors and institutions outside of the queer community. Finally, we theorize how communities like Queer in AI contribute to the participatory design in AI more broadly by fostering cultures of participation in AI, welcoming and empowering marginalized participants, critiquing poor or exploitative participatory practices, and bringing participation to institutions outside of individual research projects. Queer in AI's work serves as a case study of grassroots activism and participatory methods within AI, demonstrating the potential of community-led participatory methods and intersectional praxis, while also providing challenges, case studies, and nuanced insights to researchers developing and using participatory methods.
Value Gradient weighted Model-Based Reinforcement Learning
Apr 04, 2022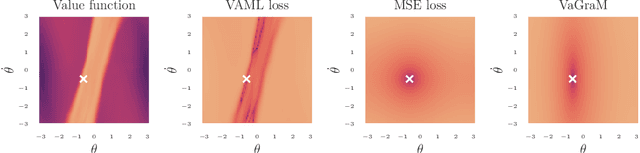


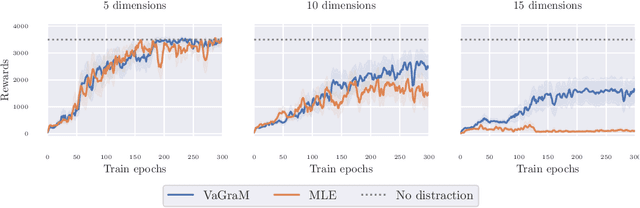
Model-based reinforcement learning (MBRL) is a sample efficient technique to obtain control policies, yet unavoidable modeling errors often lead performance deterioration. The model in MBRL is often solely fitted to reconstruct dynamics, state observations in particular, while the impact of model error on the policy is not captured by the training objective. This leads to a mismatch between the intended goal of MBRL, enabling good policy and value learning, and the target of the loss function employed in practice, future state prediction. Naive intuition would suggest that value-aware model learning would fix this problem and, indeed, several solutions to this objective mismatch problem have been proposed based on theoretical analysis. However, they tend to be inferior in practice to commonly used maximum likelihood (MLE) based approaches. In this paper we propose the Value-gradient weighted Model Learning (VaGraM), a novel method for value-aware model learning which improves the performance of MBRL in challenging settings, such as small model capacity and the presence of distracting state dimensions. We analyze both MLE and value-aware approaches and demonstrate how they fail to account for exploration and the behavior of function approximation when learning value-aware models and highlight the additional goals that must be met to stabilize optimization in the deep learning setting. We verify our analysis by showing that our loss function is able to achieve high returns on the Mujoco benchmark suite while being more robust than maximum likelihood based approaches.
Structured Object-Aware Physics Prediction for Video Modeling and Planning
Oct 06, 2019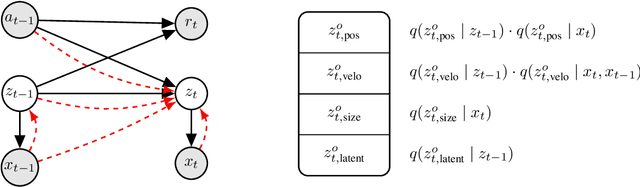



When humans observe a physical system, they can easily locate objects, understand their interactions, and anticipate future behavior, even in settings with complicated and previously unseen interactions. For computers, however, learning such models from videos in an unsupervised fashion is an unsolved research problem. In this paper, we present STOVE, a novel state-space model for videos, which explicitly reasons about objects and their positions, velocities, and interactions. It is constructed by combining an image model and a dynamics model in compositional manner and improves on previous work by reusing the dynamics model for inference, accelerating and regularizing training. STOVE predicts videos with convincing physical behavior over hundreds of timesteps, outperforms previous unsupervised models, and even approaches the performance of supervised baselines. We further demonstrate the strength of our model as a simulator for sample efficient model-based control in a task with heavily interacting objects.