 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does Self-Prediction help? Understanding Auxiliary Tasks in Reinforcement Learning
Jun 25, 2024We investigate the impact of auxiliary learning tasks such as observation reconstruction and latent self-prediction on the representation learning problem in reinforcement learning. We also study how they interact with distractions and observation functions in the MDP. We provide a theoretical analysis of the learning dynamics of observation reconstruction, latent self-prediction, and TD learning in the presence of distractions and observation functions under linear model assumptions. With this formalization, we are able to explain why latent-self prediction is a helpful \emph{auxiliary task}, while observation reconstruction can provide more useful features when used in isolation. Our empirical analysis shows that the insights obtained from our learning dynamics framework predicts the behavior of these loss functions beyond the linear model assumption in non-linear neural networks. This reinforces the usefulness of the linear model framework not only for theoretical analysis, but also practical benefit for applied problems.
Distributional Model Equivalence for Risk-Sensitive Reinforcement Learning
Jul 04, 2023


We consider the problem of learning models for risk-sensitive reinforcement learning. We theoretically demonstrate that proper value equivalence, a method of learning models which can be used to plan optimally in the risk-neutral setting, is not sufficient to plan optimally in the risk-sensitive setting. We leverage distributional reinforcement learning to introduce two new notions of model equivalence, one which is general and can be used to plan for any risk measure, but is intractable; and a practical variation which allows one to choose which risk measures they may plan optimally for. We demonstrate how our framework can be used to augment any model-free risk-sensitive algorithm, and provide both tabular and large-scale experiments to demonstrate its ability.
MICo: Learning improved representations via sampling-based state similarity for Markov decision processes
Jun 03, 2021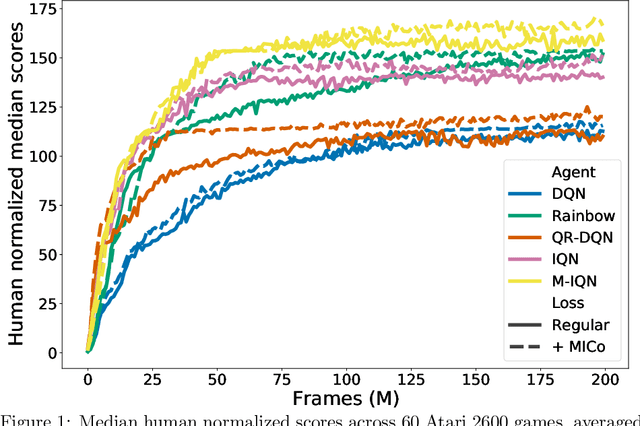
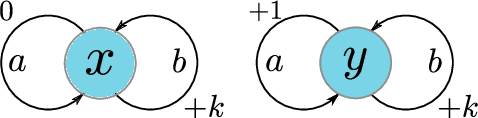
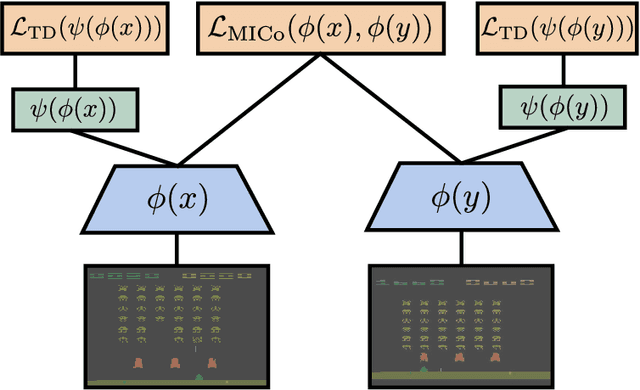
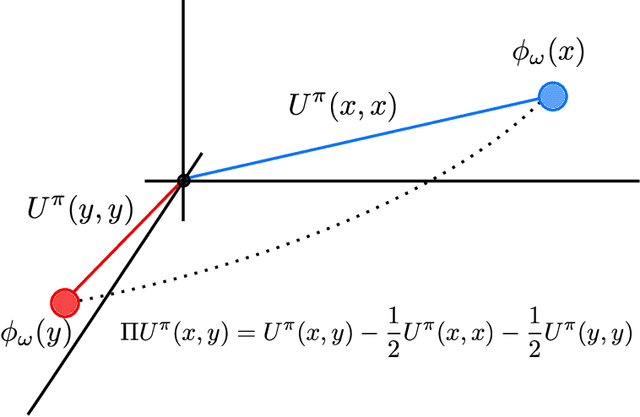
We present a new behavioural distance over the state space of a Markov decision process, and demonstrate the use of this distance as an effective means of shaping the learnt representations of deep reinforcement learning agents. While existing notions of state similarity are typically difficult to learn at scale due to high computational cost and lack of sample-based algorithms, our newly-proposed distance addresses both of these issues. In addition to providing detailed theoretical analysis, we provide empirical evidence that learning this distance alongside the value function yields structured and informative representations, including strong results on the Arcade Learning Environment benchmark.