 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Reward Uncertainty to Induce Diverse Behaviour in Reinforcement Learning
Jun 02, 2026Classical reinforcement learning (RL) typically seeks a deterministic policy that maximizes the expected sum of a scalar reward. Yet, modern applications such as language model fine-tuning or scientific discovery demand diversity. Existing remedies such as entropy regularization or diversity bonuses often require fragile trade-offs that sacrifice performance for stochasticity or rely on heuristic metrics that can misalign policy rankings. We argue that diversity is more naturally understood as the rational response to uncertainty in the reward. When the reward function is not perfectly known--as is the case with ambiguous preferences or imperfect reward models--committing to a single action can be sub-optimal. Building on this, we propose a fundamental reformulation of the RL objective by replacing the scalar reward with a distribution over reward functions, and applying a non-linear objective over sets of actions. The result is a framework in which calibrated behavioural diversity emerges naturally, remains controllable through the reward function distribution, and is obtained without sacrificing expected reward. Focusing on the contextual bandit setting, we derive a principled gradient estimator for this objective and prove that our formulation naturally generalizes both vanilla policy gradient and more recently developed action-set approaches. Our empirical results demonstrate that this framework offers a robust and theoretically grounded alternative for complex RL tasks where the traditional formulation of the problem fails to induce the desired breadth of agent behaviour.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
Foundations of Multivariate Distributional Reinforcement Learning
Aug 31, 2024



In reinforcement learning (RL), the consideration of multivariate reward signals has led to fundamental advancements in multi-objective decision-making, transfer learning, and representation learning. This work introduces the first oracle-free and computationally-tractable algorithms for provably convergent multivariate distributional dynamic programming and temporal difference learning. Our convergence rates match the familiar rates in the scalar reward setting, and additionally provide new insights into the fidelity of approximate return distribution representations as a function of the reward dimension. Surprisingly, when the reward dimension is larger than $1$, we show that standard analysis of categorical TD learning fails, which we resolve with a novel projection onto the space of mass-$1$ signed measures. Finally, with the aid of our technical results and simulations, we identify tradeoffs between distribution representations that influence the performance of multivariate distributional RL in practice.
A Unifying Framework for Action-Conditional Self-Predictive Reinforcement Learning
Jun 04, 2024



Learning a good representation is a crucial challenge for Reinforcement Learning (RL) agents. Self-predictive learning provides means to jointly learn a latent representation and dynamics model by bootstrapping from future latent representations (BYOL). Recent work has developed theoretical insights into these algorithms by studying a continuous-time ODE model for self-predictive representation learning under the simplifying assumption that the algorithm depends on a fixed policy (BYOL-$\Pi$); this assumption is at odds with practical instantiations of such algorithms, which explicitly condition their predictions on future actions. In this work, we take a step towards bridging the gap between theory and practice by analyzing an action-conditional self-predictive objective (BYOL-AC) using the ODE framework, characterizing its convergence properties and highlighting important distinctions between the limiting solutions of the BYOL-$\Pi$ and BYOL-AC dynamics. We show how the two representations are related by a variance equation. This connection leads to a novel variance-like action-conditional objective (BYOL-VAR) and its corresponding ODE. We unify the study of all three objectives through two complementary lenses; a model-based perspective, where each objective is shown to be equivalent to a low-rank approximation of certain dynamics, and a model-free perspective, which establishes relationships between the objectives and their respective value, Q-value, and advantage function. Our empirical investigations, encompassing both linear function approximation and Deep RL environments, demonstrates that BYOL-AC is better overall in a variety of different settings.
Human Alignment of Large Language Models through Online Preference Optimisation
Mar 13, 2024



Ensuring alignment of language models' outputs with human preferences is critical to guarantee a useful, safe, and pleasant user experience. Thus, human alignment has been extensively studied recently and several methods such as Reinforcement Learning from Human Feedback (RLHF), Direct Policy Optimisation (DPO) and Sequence Likelihood Calibration (SLiC) have emerged. In this paper, our contribution is two-fold. First, we show the equivalence between two recent alignment methods, namely Identity Policy Optimisation (IPO) and Nash Mirror Descent (Nash-MD). Second, we introduce a generalisation of IPO, named IPO-MD, that leverages the regularised sampling approach proposed by Nash-MD. This equivalence may seem surprising at first sight, since IPO is an offline method whereas Nash-MD is an online method using a preference model. However, this equivalence can be proven when we consider the online version of IPO, that is when both generations are sampled by the online policy and annotated by a trained preference model. Optimising the IPO loss with such a stream of data becomes then equivalent to finding the Nash equilibrium of the preference model through self-play. Building on this equivalence, we introduce the IPO-MD algorithm that generates data with a mixture policy (between the online and reference policy) similarly as the general Nash-MD algorithm. We compare online-IPO and IPO-MD to different online versions of existing losses on preference data such as DPO and SLiC on a summarisation task.
A Distributional Analogue to the Successor Representation
Feb 13, 2024



This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
Near-Minimax-Optimal Distributional Reinforcement Learning with a Generative Model
Feb 12, 2024



We propose a new algorithm for model-based distributional reinforcement learning (RL), and prove that it is minimax-optimal for approximating return distributions with a generative model (up to logarithmic factors), resolving an open question of Zhang et al. (2023). Our analysis provides new theoretical results on categorical approaches to distributional RL, and also introduces a new distributional Bellman equation, the stochastic categorical CDF Bellman equation, which we expect to be of independent interest. We also provide an experimental study comparing several model-based distributional RL algorithms, with several takeaways for practitioners.
Generalized Preference Optimization: A Unified Approach to Offline Alignment
Feb 08, 2024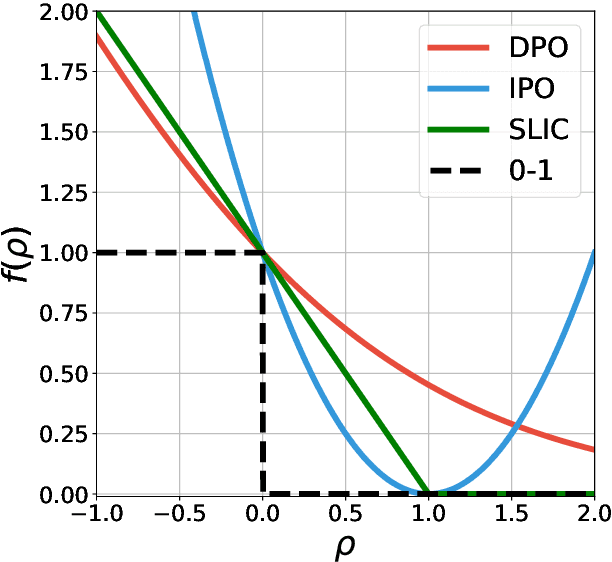
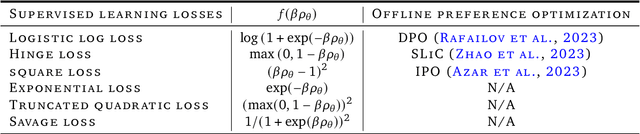
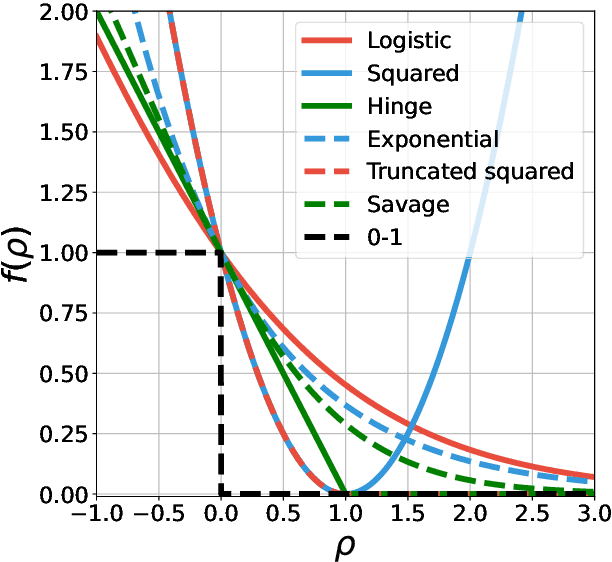
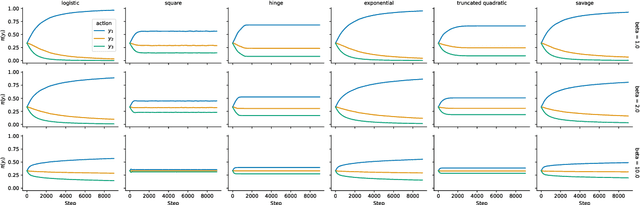
Offline preference optimization allows fine-tuning large models directly from offline data, and has proved effective in recent alignment practices. We propose generalized preference optimization (GPO), a family of offline losses parameterized by a general class of convex functions. GPO enables a unified view over preference optimization, encompassing existing algorithms such as DPO, IPO and SLiC as special cases, while naturally introducing new variants. The GPO framework also sheds light on how offline algorithms enforce regularization, through the design of the convex function that defines the loss. Our analysis and experiments reveal the connections and subtle differences between the offline regularization and the KL divergence regularization intended by the canonical RLHF formulation. In all, our results present new algorithmic toolkits and empirical insights to alignment practitioners.
Off-policy Distributional Q($λ$): Distributional RL without Importance Sampling
Feb 08, 2024We introduce off-policy distributional Q($\lambda$), a new addition to the family of off-policy distributional evaluation algorithms. Off-policy distributional Q($\lambda$) does not apply importance sampling for off-policy learning, which introduces intriguing interactions with signed measures. Such unique properties distributional Q($\lambda$) from other existing alternatives such as distributional Retrace. We characterize the algorithmic properties of distributional Q($\lambda$) and validate theoretical insights with tabular experiments. We show how distributional Q($\lambda$)-C51, a combination of Q($\lambda$) with the C51 agent, exhibits promising results on deep RL benchmarks.