 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
Leveraging Label Semantics and Meta-Label Refinement for Multi-Label Question Classification
Nov 04, 2024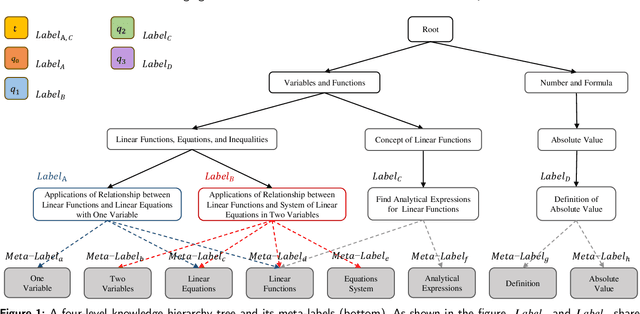
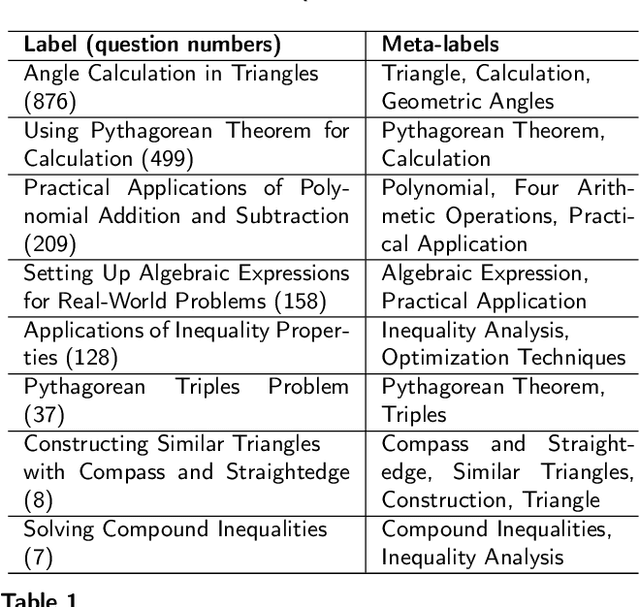

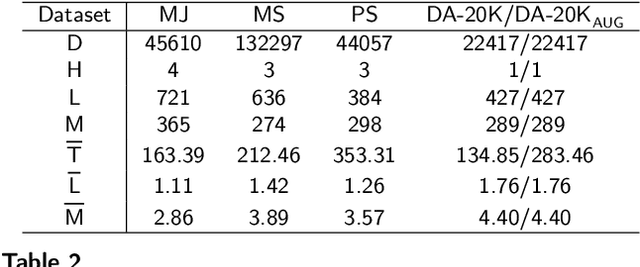
Accurate annotation of educational resources is critical in the rapidly advancing field of online education due to the complexity and volume of content. Existing classification methods face challenges with semantic overlap and distribution imbalance of labels in the multi-label context, which impedes effective personalized learning and resource recommendation. This paper introduces RR2QC, a novel Retrieval Reranking method To multi-label Question Classification by leveraging label semantics and meta-label refinement. Firstly, RR2QC leverages semantic relationships within and across label groups to enhance pre-training strategie in multi-label context. Next, a class center learning task is introduced, integrating label texts into downstream training to ensure questions consistently align with label semantics, retrieving the most relevant label sequences. Finally, this method decomposes labels into meta-labels and trains a meta-label classifier to rerank the retrieved label sequences. In doing so, RR2QC enhances the understanding and prediction capability of long-tail labels by learning from meta-labels frequently appearing in other labels. Addtionally, a Math LLM is used to generate solutions for questions, extracting latent information to further refine the model's insights. Experimental results demonstrate that RR2QC outperforms existing classification methods in Precision@k and F1 scores across multiple educational datasets, establishing it as a potent enhancement for online educational content utilization.
RLHF and IIA: Perverse Incentives
Dec 02, 2023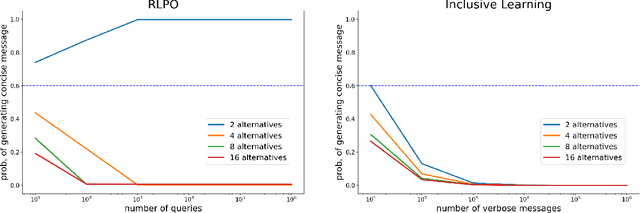
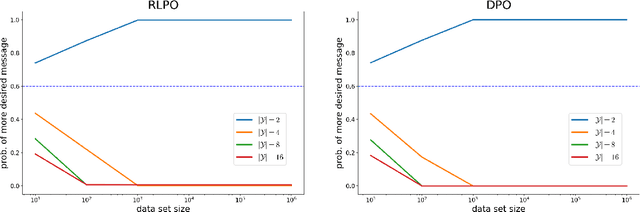
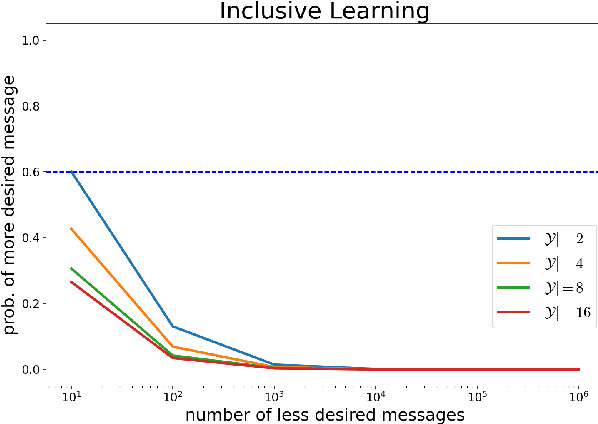
Existing algorithms for reinforcement learning from human feedback (RLHF) can incentivize responses at odds with preferences because they are based on models that assume independence of irrelevant alternatives (IIA). The perverse incentives induced by IIA give rise to egregious behavior when innovating on query formats or learning algorithms.
Fine-Tuning Language Models with Advantage-Induced Policy Alignment
Jun 06, 2023
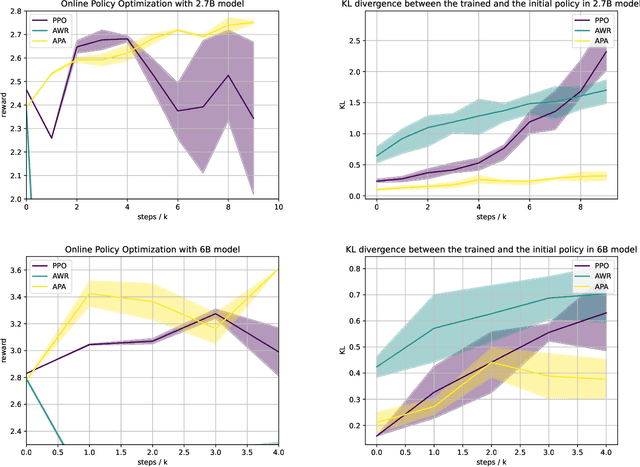
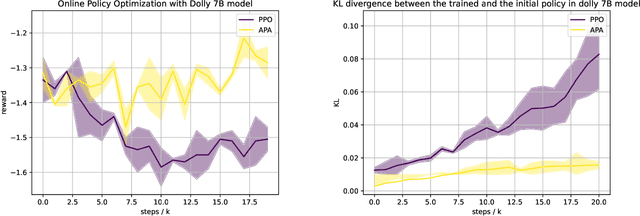
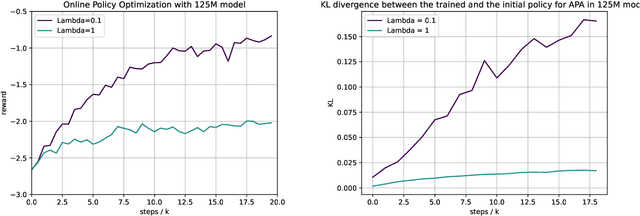
Reinforcement learning from human feedback (RLHF) has emerged as a reliable approach to aligning large language models (LLMs) to human preferences. Among the plethora of RLHF techniques, proximal policy optimization (PPO) is of the most widely used methods. Despite its popularity, however, PPO may suffer from mode collapse, instability, and poor sample efficiency. We show that these issues can be alleviated by a novel algorithm that we refer to as Advantage-Induced Policy Alignment (APA), which leverages a squared error loss function based on the estimated advantages. We demonstrate empirically that APA consistently outperforms PPO in language tasks by a large margin, when a separate reward model is employed as the evaluator. In addition, compared with PPO, APA offers a more stable form of control over the deviation from the model's initial policy, ensuring that the model improves its performance without collapsing to deterministic output. In addition to empirical results, we also provide a theoretical justification supporting the design of our loss function.
Shattering the Agent-Environment Interface for Fine-Tuning Inclusive Language Models
May 19, 2023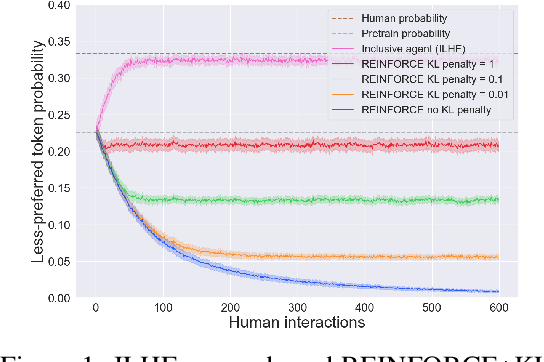
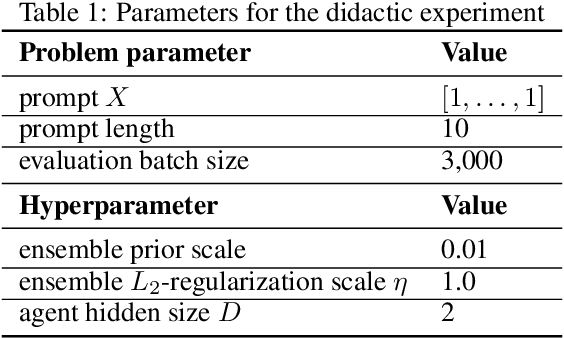
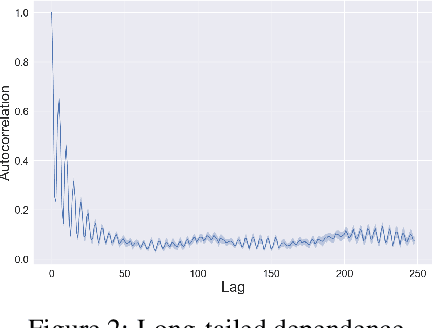

A centerpiece of the ever-popular reinforcement learning from human feedback (RLHF) approach to fine-tuning autoregressive language models is the explicit training of a reward model to emulate human feedback, distinct from the language model itself. This reward model is then coupled with policy-gradient methods to dramatically improve the alignment between language model outputs and desired responses. In this work, we adopt a novel perspective wherein a pre-trained language model is itself simultaneously a policy, reward function, and transition function. An immediate consequence of this is that reward learning and language model fine-tuning can be performed jointly and directly, without requiring any further downstream policy optimization. While this perspective does indeed break the traditional agent-environment interface, we nevertheless maintain that there can be enormous statistical benefits afforded by bringing to bear traditional algorithmic concepts from reinforcement learning. Our experiments demonstrate one concrete instance of this through efficient exploration based on the representation and resolution of epistemic uncertainty. In order to illustrate these ideas in a transparent manner, we restrict attention to a simple didactic data generating process and leave for future work extension to systems of practical scale.
Inclusive Artificial Intelligence
Dec 24, 2022
Prevailing methods for assessing and comparing generative AIs incentivize responses that serve a hypothetical representative individual. Evaluating models in these terms presumes homogeneous preferences across the population and engenders selection of agglomerative AIs, which fail to represent the diverse range of interests across individuals. We propose an alternative evaluation method that instead prioritizes inclusive AIs, which provably retain the requisite knowledge not only for subsequent response customization to particular segments of the population but also for utility-maximizing decisions.
Posterior Sampling for Continuing Environments
Nov 29, 2022We develop an extension of posterior sampling for reinforcement learning (PSRL) that is suited for a continuing agent-environment interface and integrates naturally into agent designs that scale to complex environments. The approach maintains a statistically plausible model of the environment and follows a policy that maximizes expected $\gamma$-discounted return in that model. At each time, with probability $1-\gamma$, the model is replaced by a sample from the posterior distribution over environments. For a suitable schedule of $\gamma$, we establish an $\tilde{O}(\tau S \sqrt{A T})$ bound on the Bayesian regret, where $S$ is the number of environment states, $A$ is the number of actions, and $\tau$ denotes the reward averaging time, which is a bound on the duration required to accurately estimate the average reward of any policy.
A unified interpretable intelligent learning diagnosis framework for smart education
Jul 07, 2022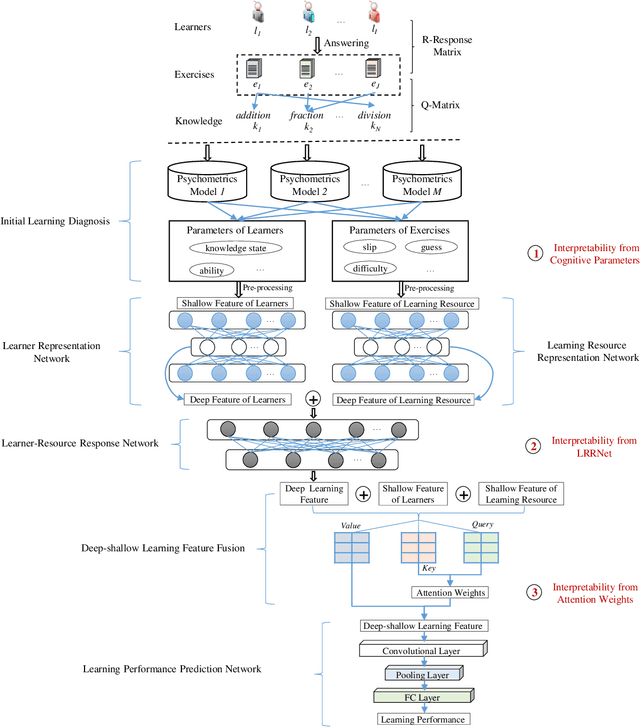
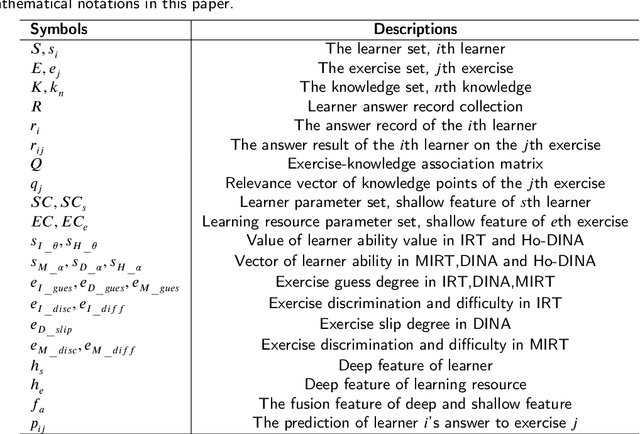

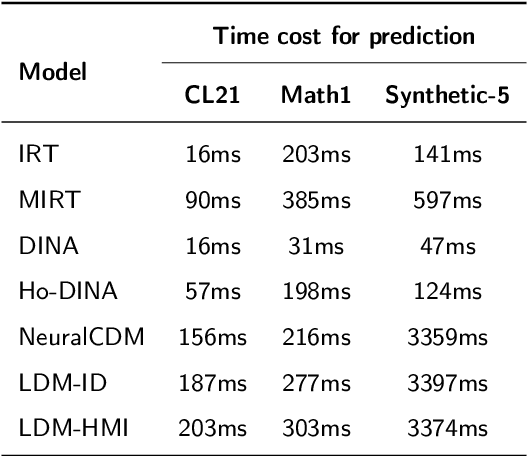
Intelligent learning diagnosis is a critical engine of smart education, which aims to estimate learners' current knowledge mastery status and predict their future learning performance. The significant challenge with traditional learning diagnosis methods is the inability to balance diagnostic accuracy and interpretability. To settle the above problem, the proposed unified interpretable intelligent learning diagnosis framework, which benefits from the powerful representation learning ability of deep learning and the interpretability of psychometric, achieves good performance of learning prediction and provides interpretability from three aspects: cognitive parameters, learner-resource response network, and weights of self-attention mechanism. Within the proposed framework, this paper proposes a two-channel learning diagnosis mechanism LDM-ID as well as a three-channel learning diagnosis mechanism LDM-HMI. Experiments on two real-world datasets and a simulation dataset show that our method has higher accuracy in predicting learners' performances compared with the state-of-the-art models, and can provide valuable educational interpretabilities for applications such as precise learning resource recommendation and personalized learning tutoring in smart education.
Simple Agent, Complex Environment: Efficient Reinforcement Learning with Agent State
Mar 08, 2021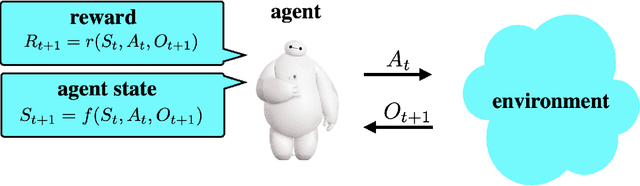
We design a simple reinforcement learning agent that, with a specification only of agent state dynamics and a reward function, can operate with some degree of competence in any environment. The agent maintains only visitation counts and value estimates for each agent-state-action pair. The value function is updated incrementally in response to temporal differences and optimistic boosts that encourage exploration. The agent executes actions that are greedy with respect to this value function. We establish a regret bound demonstrating convergence to near-optimal per-period performance, where the time taken to achieve near-optimality is polynomial in the number of agent states and actions, as well as the reward mixing time of the best policy within the reference policy class, which is comprised of those that depend on history only through agent state. Notably, there is no further dependence on the number of environment states or mixing times associated with other policies or statistics of history. Our result sheds light on the potential benefits of (deep) representation learning, which has demonstrated the capability to extract compact and relevant features from high-dimensional interaction histories.