 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Jan 22, 2026Recent video generation models demonstrate remarkable ability to capture complex physical interactions and scene evolution over time. To leverage their spatiotemporal priors, robotics works have adapted video models for policy learning but introduce complexity by requiring multiple stages of post-training and new architectural components for action generation. In this work, we introduce Cosmos Policy, a simple approach for adapting a large pretrained video model (Cosmos-Predict2) into an effective robot policy through a single stage of post-training on the robot demonstration data collected on the target platform, with no architectural modifications. Cosmos Policy learns to directly generate robot actions encoded as latent frames within the video model's latent diffusion process, harnessing the model's pretrained priors and core learning algorithm to capture complex action distributions. Additionally, Cosmos Policy generates future state images and values (expected cumulative rewards), which are similarly encoded as latent frames, enabling test-time planning of action trajectories with higher likelihood of success. In our evaluations, Cosmos Policy achieves state-of-the-art performance on the LIBERO and RoboCasa simulation benchmarks (98.5% and 67.1% average success rates, respectively) and the highest average score in challenging real-world bimanual manipulation tasks, outperforming strong diffusion policies trained from scratch, video model-based policies, and state-of-the-art vision-language-action models fine-tuned on the same robot demonstrations. Furthermore, given policy rollout data, Cosmos Policy can learn from experience to refine its world model and value function and leverage model-based planning to achieve even higher success rates in challenging tasks. We release code, models, and training data at https://research.nvidia.com/labs/dir/cosmos-policy/
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Edify Image: High-Quality Image Generation with Pixel Space Laplacian Diffusion Models
Nov 11, 2024We introduce Edify Image, a family of diffusion models capable of generating photorealistic image content with pixel-perfect accuracy. Edify Image utilizes cascaded pixel-space diffusion models trained using a novel Laplacian diffusion process, in which image signals at different frequency bands are attenuated at varying rates. Edify Image supports a wide range of applications, including text-to-image synthesis, 4K upsampling, ControlNets, 360 HDR panorama generation, and finetuning for image customization.
OpenVLA: An Open-Source Vision-Language-Action Model
Jun 13, 2024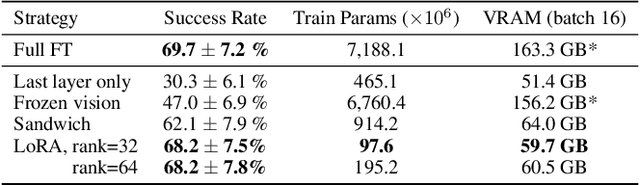
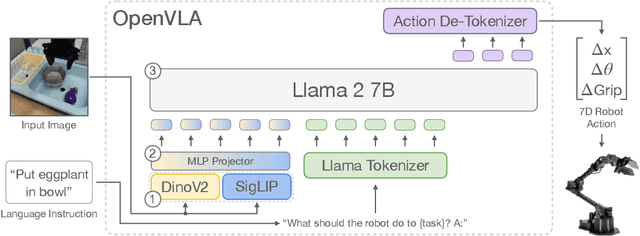
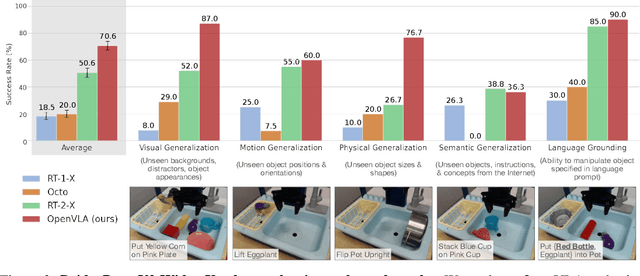
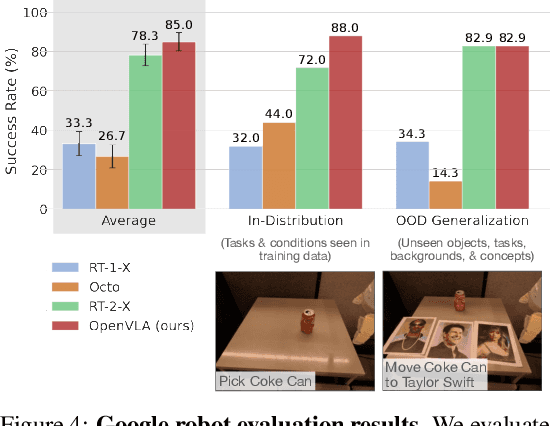
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
RLHF and IIA: Perverse Incentives
Dec 02, 2023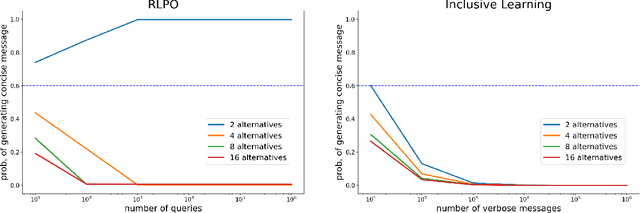
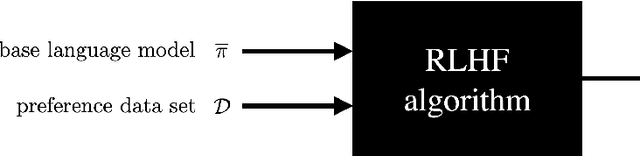
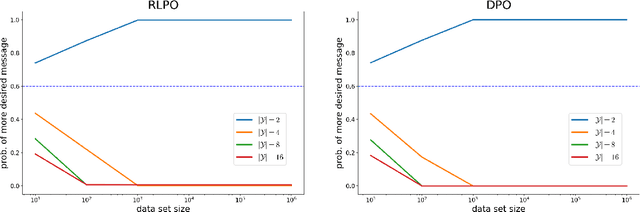
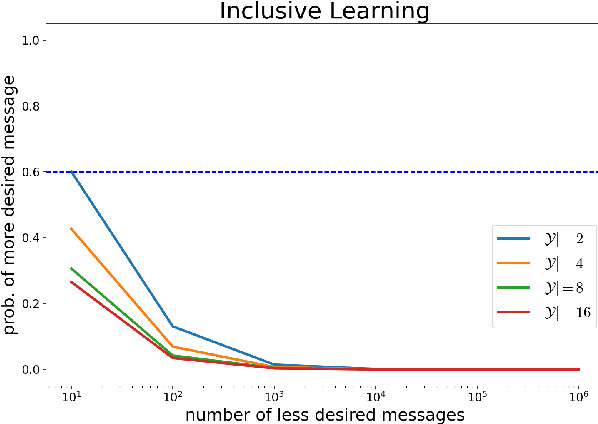
Existing algorithms for reinforcement learning from human feedback (RLHF) can incentivize responses at odds with preferences because they are based on models that assume independence of irrelevant alternatives (IIA). The perverse incentives induced by IIA give rise to egregious behavior when innovating on query formats or learning algorithms.
Semi-supervised Learning for Quantification of Pulmonary Edema in Chest X-Ray Images
Apr 10, 2019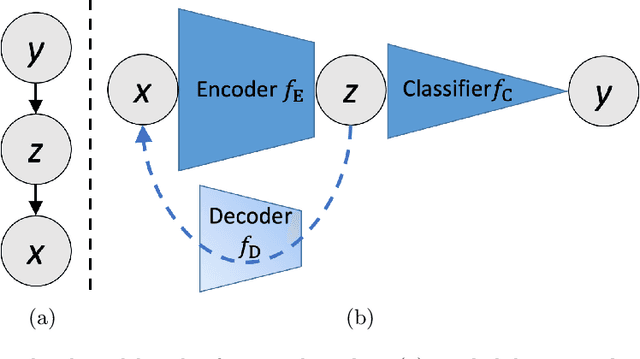
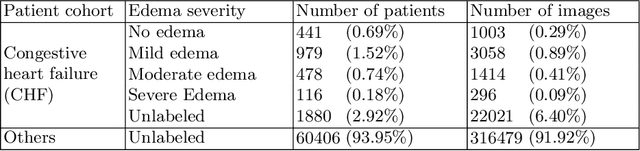
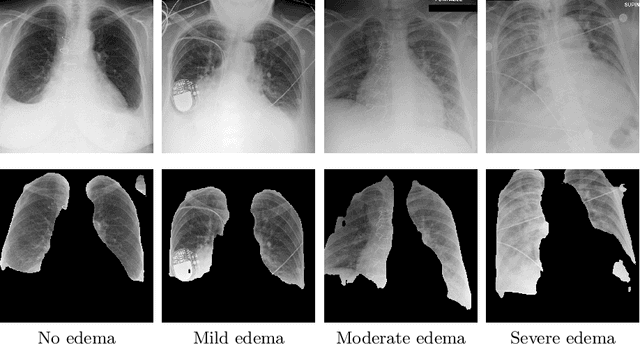
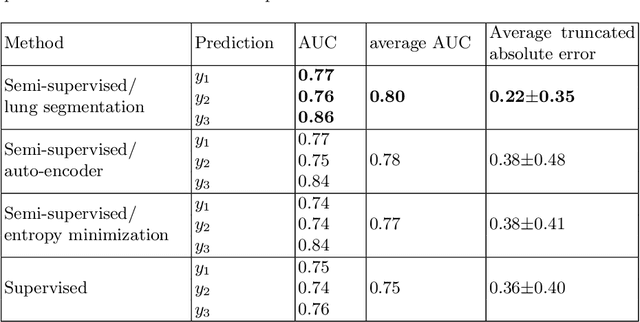
We propose and demonstrate machine learning algorithms to assess the severity of pulmonary edema in chest x-ray images of congestive heart failure patients. Accurate assessment of pulmonary edema in heart failure is critical when making treatment and disposition decisions. Our work is grounded in a large-scale clinical dataset of over 300,000 x-ray images with associated radiology reports. While edema severity labels can be extracted unambiguously from a small fraction of the radiology reports, accurate annotation is challenging in most cases. To take advantage of the unlabeled images, we develop a Bayesian model that includes a variational auto-encoder for learning a latent representation from the entire image set trained jointly with a regressor that employs this representation for predicting pulmonary edema severity. Our experimental results suggest that modeling the distribution of images jointly with the limited labels improves the accuracy of pulmonary edema scoring compared to a strictly supervised approach. To the best of our knowledge, this is the first attempt to employ machine learning algorithms to automatically and quantitatively assess the severity of pulmonary edema in chest x-ray images.