Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLHF and IIA: Perverse Incentives
Paper and Code
Dec 02, 2023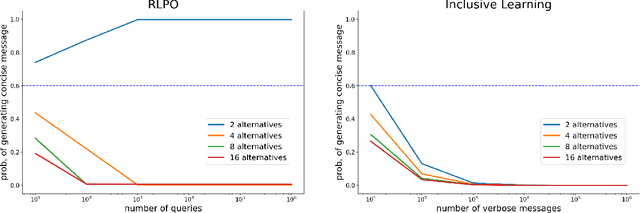
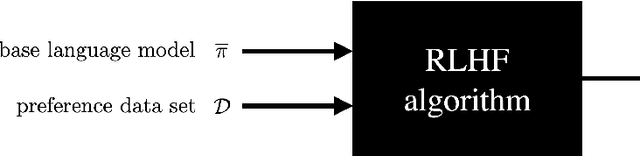
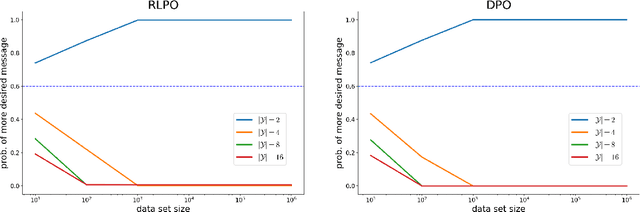
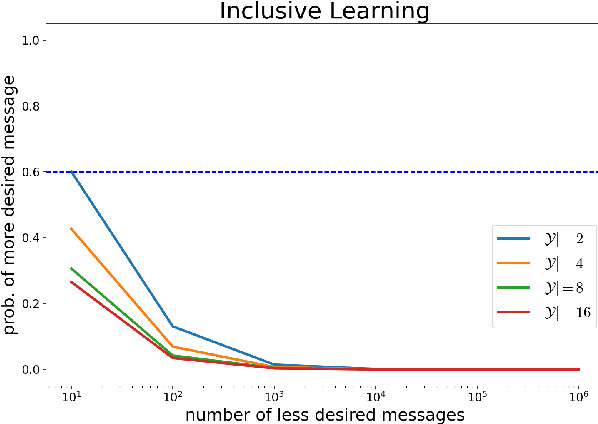
Existing algorithms for reinforcement learning from human feedback (RLHF) can incentivize responses at odds with preferences because they are based on models that assume independence of irrelevant alternatives (IIA). The perverse incentives induced by IIA give rise to egregious behavior when innovating on query formats or learning algorithms.
View paper on