 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal and Rotational Calibration for Event-Centric Multi-Sensor Systems
Aug 18, 2025Event cameras generate asynchronous signals in response to pixel-level brightness changes, offering a sensing paradigm with theoretically microsecond-scale latency that can significantly enhance the performance of multi-sensor systems. Extrinsic calibration is a critical prerequisite for effective sensor fusion; however, the configuration that involves event cameras remains an understudied topic. In this paper, we propose a motion-based temporal and rotational calibration framework tailored for event-centric multi-sensor systems, eliminating the need for dedicated calibration targets. Our method uses as input the rotational motion estimates obtained from event cameras and other heterogeneous sensors, respectively. Different from conventional approaches that rely on event-to-frame conversion, our method efficiently estimates angular velocity from normal flow observations, which are derived from the spatio-temporal profile of event data. The overall calibration pipeline adopts a two-step approach: it first initializes the temporal offset and rotational extrinsics by exploiting kinematic correlations in the spirit of Canonical Correlation Analysis (CCA), and then refines both temporal and rotational parameters through a joint non-linear optimization using a continuous-time parametrization in SO(3). Extensive evaluations on both publicly available and self-collected datasets validate that the proposed method achieves calibration accuracy comparable to target-based methods, while exhibiting superior stability over purely CCA-based methods, and highlighting its precision, robustness and flexibility. To facilitate future research, our implementation will be made open-source. Code: https://github.com/NAIL-HNU/EvMultiCalib.
ESVO2: Direct Visual-Inertial Odometry with Stereo Event Cameras
Oct 12, 2024



Event-based visual odometry is a specific branch of visual Simultaneous Localization and Mapping (SLAM) techniques, which aims at solving tracking and mapping sub-problems in parallel by exploiting the special working principles of neuromorphic (ie, event-based) cameras. Due to the motion-dependent nature of event data, explicit data association ie, feature matching under large-baseline view-point changes is hardly established, making direct methods a more rational choice. However, state-of-the-art direct methods are limited by the high computational complexity of the mapping sub-problem and the degeneracy of camera pose tracking in certain degrees of freedom (DoF) in rotation. In this paper, we resolve these issues by building an event-based stereo visual-inertial odometry system on top of our previous direct pipeline Event-based Stereo Visual Odometry. Specifically, to speed up the mapping operation, we propose an efficient strategy for sampling contour points according to the local dynamics of events. The mapping performance is also improved in terms of structure completeness and local smoothness by merging the temporal stereo and static stereo results. To circumvent the degeneracy of camera pose tracking in recovering the pitch and yaw components of general six-DoF motion, we introduce IMU measurements as motion priors via pre-integration. To this end, a compact back-end is proposed for continuously updating the IMU bias and predicting the linear velocity, enabling an accurate motion prediction for camera pose tracking. The resulting system scales well with modern high-resolution event cameras and leads to better global positioning accuracy in large-scale outdoor environments. Extensive evaluations on five publicly available datasets featuring different resolutions and scenarios justify the superior performance of the proposed system against five state-of-the-art methods.
RLHF and IIA: Perverse Incentives
Dec 02, 2023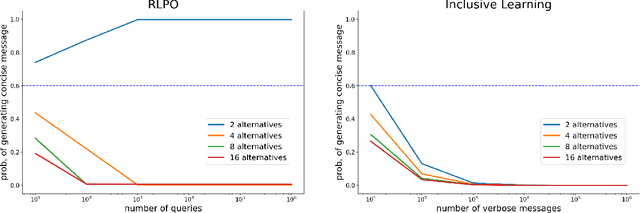
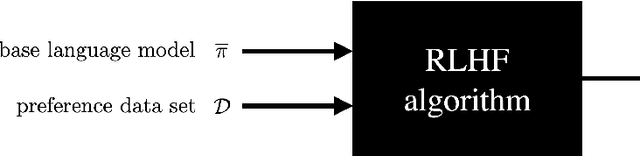
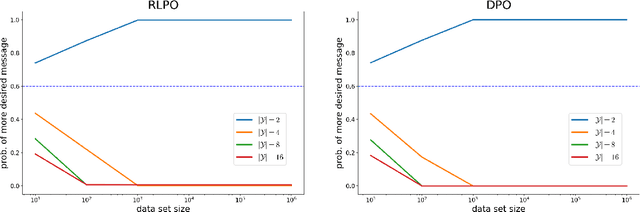
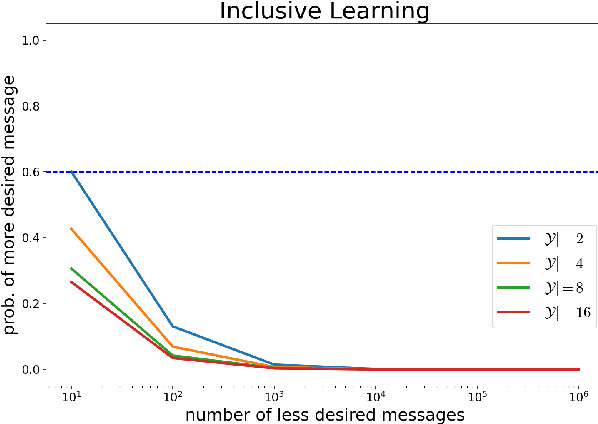
Existing algorithms for reinforcement learning from human feedback (RLHF) can incentivize responses at odds with preferences because they are based on models that assume independence of irrelevant alternatives (IIA). The perverse incentives induced by IIA give rise to egregious behavior when innovating on query formats or learning algorithms.
Event-based Visual Inertial Velometer
Nov 30, 2023Neuromorphic event-based cameras are bio-inspired visual sensors with asynchronous pixels and extremely high temporal resolution. Such favorable properties make them an excellent choice for solving state estimation tasks under aggressive ego motion. However, failures of camera pose tracking are frequently witnessed in state-of-the-art event-based visual odometry systems when the local map cannot be updated in time. One of the biggest roadblocks for this specific field is the absence of efficient and robust methods for data association without imposing any assumption on the environment. This problem seems, however, unlikely to be addressed as in standard vision due to the motion-dependent observability of event data. Therefore, we propose a mapping-free design for event-based visual-inertial state estimation in this paper. Instead of estimating the position of the event camera, we find that recovering the instantaneous linear velocity is more consistent with the differential working principle of event cameras. The proposed event-based visual-inertial velometer leverages a continuous-time formulation that incrementally fuses the heterogeneous measurements from a stereo event camera and an inertial measurement unit. Experiments on the synthetic dataset demonstrate that the proposed method can recover instantaneous linear velocity in metric scale with low latency.
Approximate Thompson Sampling via Epistemic Neural Networks
Feb 18, 2023



Thompson sampling (TS) is a popular heuristic for action selection, but it requires sampling from a posterior distribution. Unfortunately, this can become computationally intractable in complex environments, such as those modeled using neural networks. Approximate posterior samples can produce effective actions, but only if they reasonably approximate joint predictive distributions of outputs across inputs. Notably, accuracy of marginal predictive distributions does not suffice. Epistemic neural networks (ENNs) are designed to produce accurate joint predictive distributions. We compare a range of ENNs through computational experiments that assess their performance in approximating TS across bandit and reinforcement learning environments. The results indicate that ENNs serve this purpose well and illustrate how the quality of joint predictive distributions drives performance. Further, we demonstrate that the \textit{epinet} -- a small additive network that estimates uncertainty -- matches the performance of large ensembles at orders of magnitude lower computational cost. This enables effective application of TS with computation that scales gracefully to complex environments.
Robustness of Epinets against Distributional Shifts
Jul 01, 2022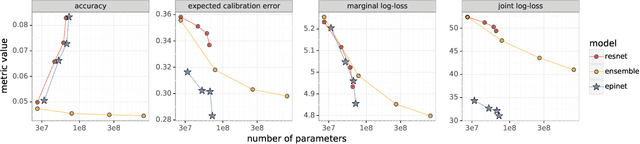
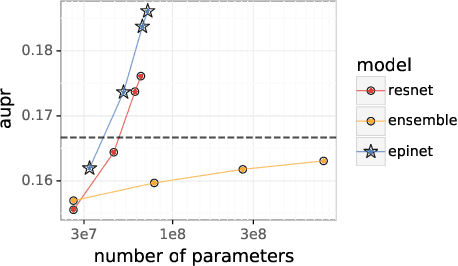
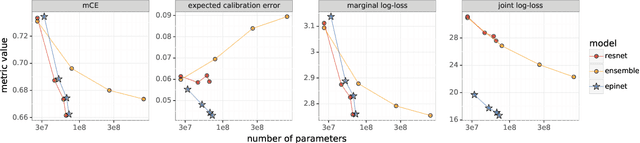
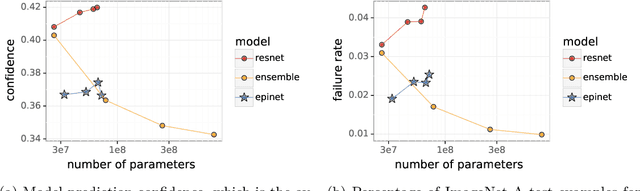
Recent work introduced the epinet as a new approach to uncertainty modeling in deep learning. An epinet is a small neural network added to traditional neural networks, which, together, can produce predictive distributions. In particular, using an epinet can greatly improve the quality of joint predictions across multiple inputs, a measure of how well a neural network knows what it does not know. In this paper, we examine whether epinets can offer similar advantages under distributional shifts. We find that, across ImageNet-A/O/C, epinets generally improve robustness metrics. Moreover, these improvements are more significant than those afforded by even very large ensembles at orders of magnitude lower computational costs. However, these improvements are relatively small compared to the outstanding issues in distributionally-robust deep learning. Epinets may be a useful tool in the toolbox, but they are far from the complete solution.
Ensembles for Uncertainty Estimation: Benefits of Prior Functions and Bootstrapping
Jun 08, 2022
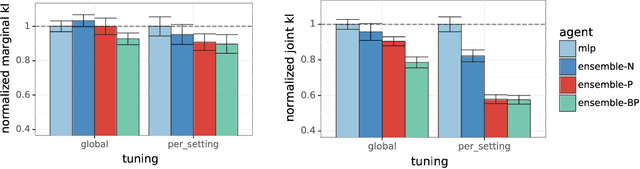


In machine learning, an agent needs to estimate uncertainty to efficiently explore and adapt and to make effective decisions. A common approach to uncertainty estimation maintains an ensemble of models. In recent years, several approaches have been proposed for training ensembles, and conflicting views prevail with regards to the importance of various ingredients of these approaches. In this paper, we aim to address the benefits of two ingredients -- prior functions and bootstrapping -- which have come into question. We show that prior functions can significantly improve an ensemble agent's joint predictions across inputs and that bootstrapping affords additional benefits if the signal-to-noise ratio varies across inputs. Our claims are justified by both theoretical and experimental results.
An Analysis of Ensemble Sampling
Mar 02, 2022Ensemble sampling serves as a practical approximation to Thompson sampling when maintaining an exact posterior distribution over model parameters is computationally intractable. In this paper, we establish a Bayesian regret bound that ensures desirable behavior when ensemble sampling is applied to the linear bandit problem. This represents the first rigorous regret analysis of ensemble sampling and is made possible by leveraging information-theoretic concepts and novel analytic techniques that may prove useful beyond the scope of this paper.
Evaluating High-Order Predictive Distributions in Deep Learning
Feb 28, 2022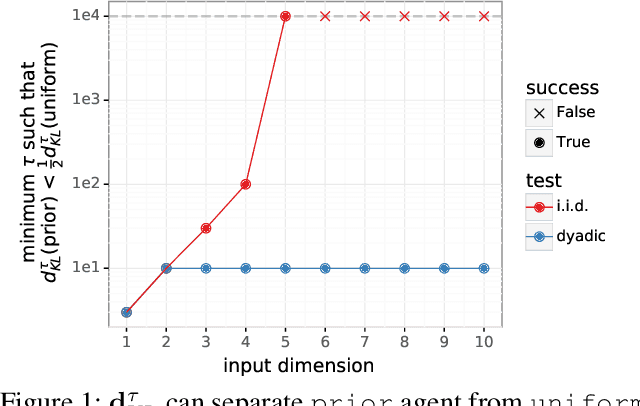
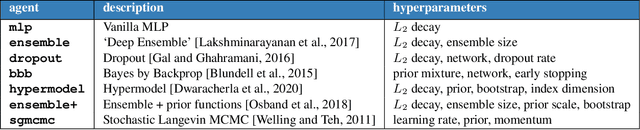
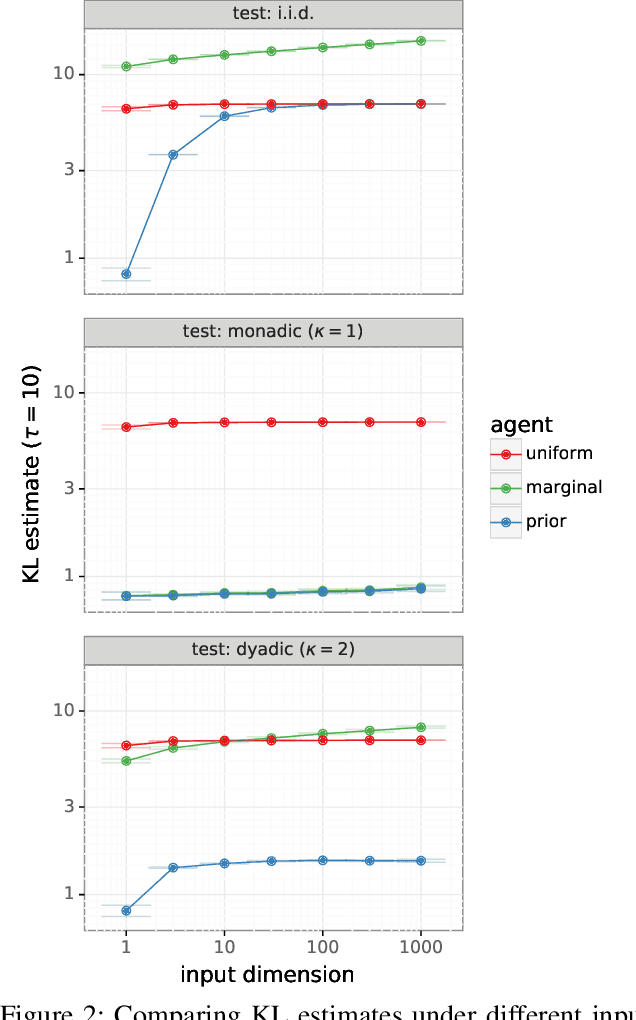
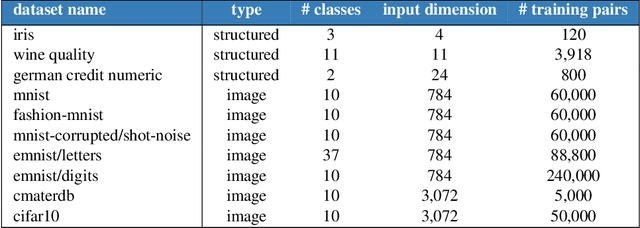
Most work on supervised learning research has focused on marginal predictions. In decision problems, joint predictive distributions are essential for good performance. Previous work has developed methods for assessing low-order predictive distributions with inputs sampled i.i.d. from the testing distribution. With low-dimensional inputs, these methods distinguish agents that effectively estimate uncertainty from those that do not. We establish that the predictive distribution order required for such differentiation increases greatly with input dimension, rendering these methods impractical. To accommodate high-dimensional inputs, we introduce \textit{dyadic sampling}, which focuses on predictive distributions associated with random \textit{pairs} of inputs. We demonstrate that this approach efficiently distinguishes agents in high-dimensional examples involving simple logistic regression as well as complex synthetic and empirical data.
Event-based Motion Segmentation by Cascaded Two-Level Multi-Model Fitting
Nov 05, 2021



Among prerequisites for a synthetic agent to interact with dynamic scenes, the ability to identify independently moving objects is specifically important. From an application perspective, nevertheless, standard cameras may deteriorate remarkably under aggressive motion and challenging illumination conditions. In contrast, event-based cameras, as a category of novel biologically inspired sensors, deliver advantages to deal with these challenges. Its rapid response and asynchronous nature enables it to capture visual stimuli at exactly the same rate of the scene dynamics. In this paper, we present a cascaded two-level multi-model fitting method for identifying independently moving objects (i.e., the motion segmentation problem) with a monocular event camera. The first level leverages tracking of event features and solves the feature clustering problem under a progressive multi-model fitting scheme. Initialized with the resulting motion model instances, the second level further addresses the event clustering problem using a spatio-temporal graph-cut method. This combination leads to efficient and accurate event-wise motion segmentation that cannot be achieved by any of them alone. Experiments demonstrate the effectiveness and versatility of our method in real-world scenes with different motion patterns and an unknown number of independently moving objects.