 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDART: Diffusion-Inspired Speculative Decoding for Fast LLM Inference
Jan 27, 2026Speculative decoding is an effective and lossless approach for accelerating LLM inference. However, existing widely adopted model-based draft designs, such as EAGLE3, improve accuracy at the cost of multi-step autoregressive inference, resulting in high drafting latency and ultimately rendering the drafting stage itself a performance bottleneck. Inspired by diffusion-based large language models (dLLMs), we propose DART, which leverages parallel generation to reduce drafting latency. DART predicts logits for multiple future masked positions in parallel within a single forward pass based on hidden states of the target model, thereby eliminating autoregressive rollouts in the draft model while preserving a lightweight design. Based on these parallel logit predictions, we further introduce an efficient tree pruning algorithm that constructs high-quality draft token trees with N-gram-enforced semantic continuity. DART substantially reduces draft-stage overhead while preserving high draft accuracy, leading to significantly improved end-to-end decoding speed. Experimental results demonstrate that DART achieves a 2.03x--3.44x wall-clock time speedup across multiple datasets, surpassing EAGLE3 by 30% on average and offering a practical speculative decoding framework. Code is released at https://github.com/fvliang/DART.
A Systematic Study of Code Obfuscation Against LLM-based Vulnerability Detection
Dec 18, 2025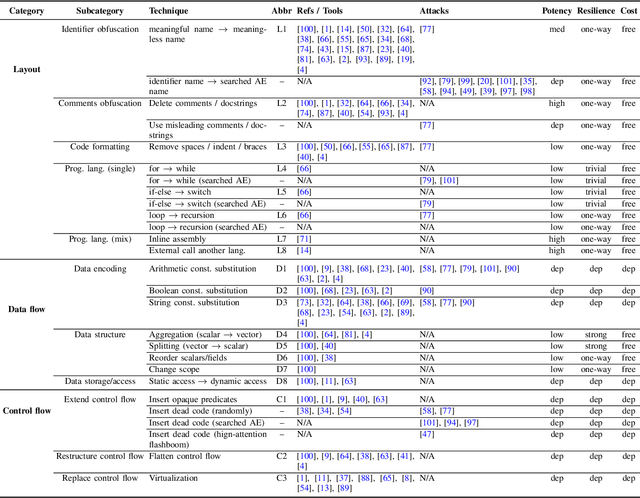
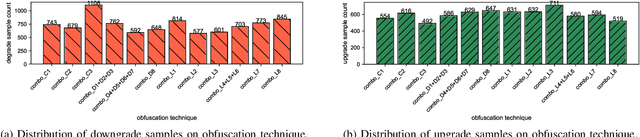

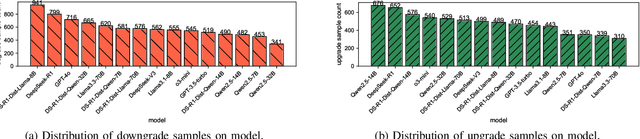
As large language models (LLMs) are increasingly adopted for code vulnerability detection, their reliability and robustness across diverse vulnerability types have become a pressing concern. In traditional adversarial settings, code obfuscation has long been used as a general strategy to bypass auditing tools, preserving exploitability without tampering with the tools themselves. Numerous efforts have explored obfuscation methods and tools, yet their capabilities differ in terms of supported techniques, granularity, and programming languages, making it difficult to systematically assess their impact on LLM-based vulnerability detection. To address this gap, we provide a structured systematization of obfuscation techniques and evaluate them under a unified framework. Specifically, we categorize existing obfuscation methods into three major classes (layout, data flow, and control flow) covering 11 subcategories and 19 concrete techniques. We implement these techniques across four programming languages (Solidity, C, C++, and Python) using a consistent LLM-driven approach, and evaluate their effects on 15 LLMs spanning four model families (DeepSeek, OpenAI, Qwen, and LLaMA), as well as on two coding agents (GitHub Copilot and Codex). Our findings reveal both positive and negative impacts of code obfuscation on LLM-based vulnerability detection, highlighting conditions under which obfuscation leads to performance improvements or degradations. We further analyze these outcomes with respect to vulnerability characteristics, code properties, and model attributes. Finally, we outline several open problems and propose future directions to enhance the robustness of LLMs for real-world vulnerability detection.
The LLM Already Knows: Estimating LLM-Perceived Question Difficulty via Hidden Representations
Sep 16, 2025Estimating the difficulty of input questions as perceived by large language models (LLMs) is essential for accurate performance evaluation and adaptive inference. Existing methods typically rely on repeated response sampling, auxiliary models, or fine-tuning the target model itself, which may incur substantial computational costs or compromise generality. In this paper, we propose a novel approach for difficulty estimation that leverages only the hidden representations produced by the target LLM. We model the token-level generation process as a Markov chain and define a value function to estimate the expected output quality given any hidden state. This allows for efficient and accurate difficulty estimation based solely on the initial hidden state, without generating any output tokens. Extensive experiments across both textual and multimodal tasks demonstrate that our method consistently outperforms existing baselines in difficulty estimation. Moreover, we apply our difficulty estimates to guide adaptive reasoning strategies, including Self-Consistency, Best-of-N, and Self-Refine, achieving higher inference efficiency with fewer generated tokens.
Deep Visual Odometry for Stereo Event Cameras
Sep 10, 2025Event-based cameras are bio-inspired sensors with pixels that independently and asynchronously respond to brightness changes at microsecond resolution, offering the potential to handle state estimation tasks involving motion blur and high dynamic range (HDR) illumination conditions. However, the versatility of event-based visual odometry (VO) relying on handcrafted data association (either direct or indirect methods) is still unreliable, especially in field robot applications under low-light HDR conditions, where the dynamic range can be enormous and the signal-to-noise ratio is spatially-and-temporally varying. Leveraging deep neural networks offers new possibilities for overcoming these challenges. In this paper, we propose a learning-based stereo event visual odometry. Building upon Deep Event Visual Odometry (DEVO), our system (called Stereo-DEVO) introduces a novel and efficient static-stereo association strategy for sparse depth estimation with almost no additional computational burden. By integrating it into a tightly coupled bundle adjustment (BA) optimization scheme, and benefiting from the recurrent network's ability to perform accurate optical flow estimation through voxel-based event representations to establish reliable patch associations, our system achieves high-precision pose estimation in metric scale. In contrast to the offline performance of DEVO, our system can process event data of \zs{Video Graphics Array} (VGA) resolution in real time. Extensive evaluations on multiple public real-world datasets and self-collected data justify our system's versatility, demonstrating superior performance compared to state-of-the-art event-based VO methods. More importantly, our system achieves stable pose estimation even in large-scale nighttime HDR scenarios.
On Evaluating the Poisoning Robustness of Federated Learning under Local Differential Privacy
Sep 05, 2025Federated learning (FL) combined with local differential privacy (LDP) enables privacy-preserving model training across decentralized data sources. However, the decentralized data-management paradigm leaves LDPFL vulnerable to participants with malicious intent. The robustness of LDPFL protocols, particularly against model poisoning attacks (MPA), where adversaries inject malicious updates to disrupt global model convergence, remains insufficiently studied. In this paper, we propose a novel and extensible model poisoning attack framework tailored for LDPFL settings. Our approach is driven by the objective of maximizing the global training loss while adhering to local privacy constraints. To counter robust aggregation mechanisms such as Multi-Krum and trimmed mean, we develop adaptive attacks that embed carefully crafted constraints into a reverse training process, enabling evasion of these defenses. We evaluate our framework across three representative LDPFL protocols, three benchmark datasets, and two types of deep neural networks. Additionally, we investigate the influence of data heterogeneity and privacy budgets on attack effectiveness. Experimental results demonstrate that our adaptive attacks can significantly degrade the performance of the global model, revealing critical vulnerabilities and highlighting the need for more robust LDPFL defense strategies against MPA. Our code is available at https://github.com/ZiJW/LDPFL-Attack
LLM-based Human-like Traffic Simulation for Self-driving Tests
Aug 23, 2025Ensuring realistic traffic dynamics is a prerequisite for simulation platforms to evaluate the reliability of self-driving systems before deployment in the real world. Because most road users are human drivers, reproducing their diverse behaviors within simulators is vital. Existing solutions, however, typically rely on either handcrafted heuristics or narrow data-driven models, which capture only fragments of real driving behaviors and offer limited driving style diversity and interpretability. To address this gap, we introduce HDSim, an HD traffic generation framework that combines cognitive theory with large language model (LLM) assistance to produce scalable and realistic traffic scenarios within simulation platforms. The framework advances the state of the art in two ways: (i) it introduces a hierarchical driver model that represents diverse driving style traits, and (ii) it develops a Perception-Mediated Behavior Influence strategy, where LLMs guide perception to indirectly shape driver actions. Experiments reveal that embedding HDSim into simulation improves detection of safety-critical failures in self-driving systems by up to 68% and yields realism-consistent accident interpretability.
Chordless Structure: A Pathway to Simple and Expressive GNNs
May 25, 2025Researchers have proposed various methods of incorporating more structured information into the design of Graph Neural Networks (GNNs) to enhance their expressiveness. However, these methods are either computationally expensive or lacking in provable expressiveness. In this paper, we observe that the chords increase the complexity of the graph structure while contributing little useful information in many cases. In contrast, chordless structures are more efficient and effective for representing the graph. Therefore, when leveraging the information of cycles, we choose to omit the chords. Accordingly, we propose a Chordless Structure-based Graph Neural Network (CSGNN) and prove that its expressiveness is strictly more powerful than the k-hop GNN (KPGNN) with polynomial complexity. Experimental results on real-world datasets demonstrate that CSGNN outperforms existing GNNs across various graph tasks while incurring lower computational costs and achieving better performance than the GNNs of 3-WL expressiveness.
FlashForge: Ultra-Efficient Prefix-Aware Attention for LLM Decoding
May 23, 2025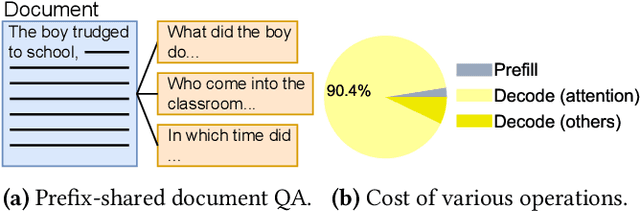
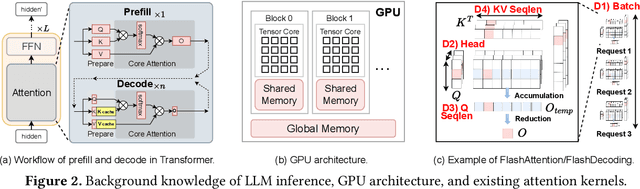
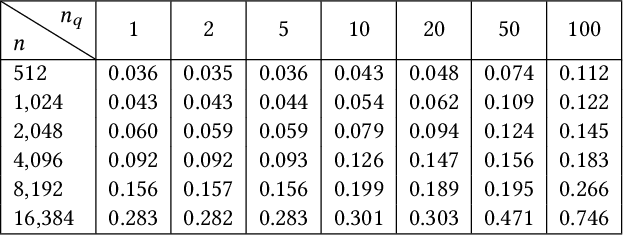
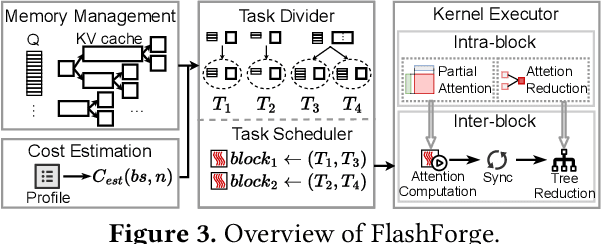
Prefix-sharing among multiple prompts presents opportunities to combine the operations of the shared prefix, while attention computation in the decode stage, which becomes a critical bottleneck with increasing context lengths, is a memory-intensive process requiring heavy memory access on the key-value (KV) cache of the prefixes. Therefore, in this paper, we explore the potential of prefix-sharing in the attention computation of the decode stage. However, the tree structure of the prefix-sharing mechanism presents significant challenges for attention computation in efficiently processing shared KV cache access patterns while managing complex dependencies and balancing irregular workloads. To address the above challenges, we propose a dedicated attention kernel to combine the memory access of shared prefixes in the decoding stage, namely FlashForge. FlashForge delivers two key innovations: a novel shared-prefix attention kernel that optimizes memory hierarchy and exploits both intra-block and inter-block parallelism, and a comprehensive workload balancing mechanism that efficiently estimates cost, divides tasks, and schedules execution. Experimental results show that FlashForge achieves an average 1.9x speedup and 120.9x memory access reduction compared to the state-of-the-art FlashDecoding kernel regarding attention computation in the decode stage and 3.8x end-to-end time per output token compared to the vLLM.
Divide-and-Conquer: Dual-Hierarchical Optimization for Semantic 4D Gaussian Spatting
Mar 25, 2025Semantic 4D Gaussians can be used for reconstructing and understanding dynamic scenes, with temporal variations than static scenes. Directly applying static methods to understand dynamic scenes will fail to capture the temporal features. Few works focus on dynamic scene understanding based on Gaussian Splatting, since once the same update strategy is employed for both dynamic and static parts, regardless of the distinction and interaction between Gaussians, significant artifacts and noise appear. We propose Dual-Hierarchical Optimization (DHO), which consists of Hierarchical Gaussian Flow and Hierarchical Gaussian Guidance in a divide-and-conquer manner. The former implements effective division of static and dynamic rendering and features. The latter helps to mitigate the issue of dynamic foreground rendering distortion in textured complex scenes. Extensive experiments show that our method consistently outperforms the baselines on both synthetic and real-world datasets, and supports various downstream tasks. Project Page: https://sweety-yan.github.io/DHO.
DriveEditor: A Unified 3D Information-Guided Framework for Controllable Object Editing in Driving Scenes
Dec 27, 2024
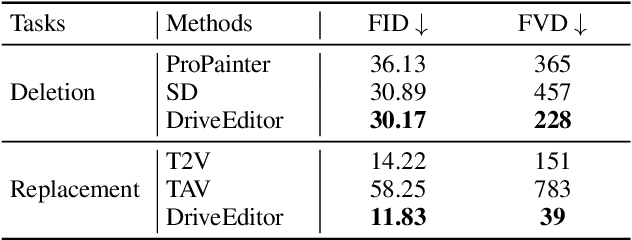
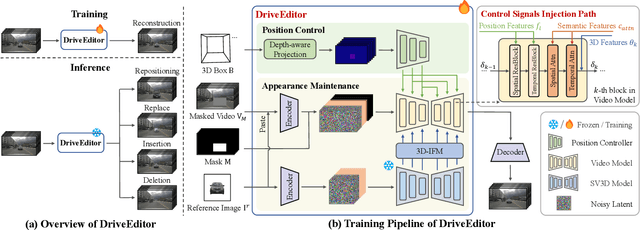
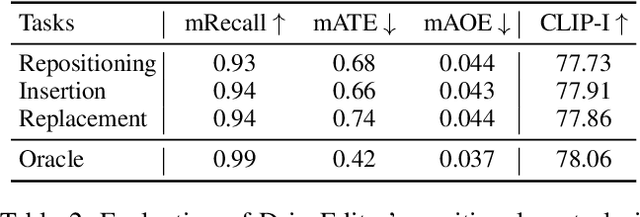
Vision-centric autonomous driving systems require diverse data for robust training and evaluation, which can be augmented by manipulating object positions and appearances within existing scene captures. While recent advancements in diffusion models have shown promise in video editing, their application to object manipulation in driving scenarios remains challenging due to imprecise positional control and difficulties in preserving high-fidelity object appearances. To address these challenges in position and appearance control, we introduce DriveEditor, a diffusion-based framework for object editing in driving videos. DriveEditor offers a unified framework for comprehensive object editing operations, including repositioning, replacement, deletion, and insertion. These diverse manipulations are all achieved through a shared set of varying inputs, processed by identical position control and appearance maintenance modules. The position control module projects the given 3D bounding box while preserving depth information and hierarchically injects it into the diffusion process, enabling precise control over object position and orientation. The appearance maintenance module preserves consistent attributes with a single reference image by employing a three-tiered approach: low-level detail preservation, high-level semantic maintenance, and the integration of 3D priors from a novel view synthesis model. Extensive qualitative and quantitative evaluations on the nuScenes dataset demonstrate DriveEditor's exceptional fidelity and controllability in generating diverse driving scene edits, as well as its remarkable ability to facilitate downstream tasks.