 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting SLO and Goodput Metrics in LLM Serving
Oct 18, 2024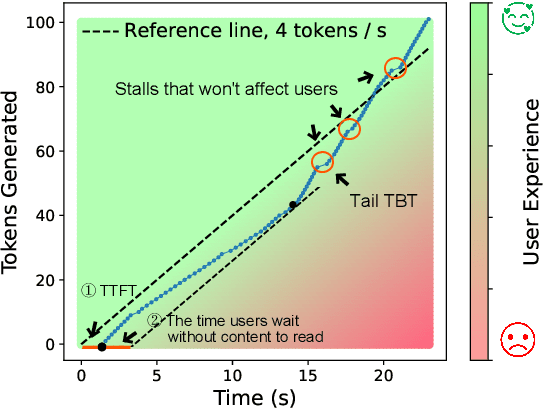

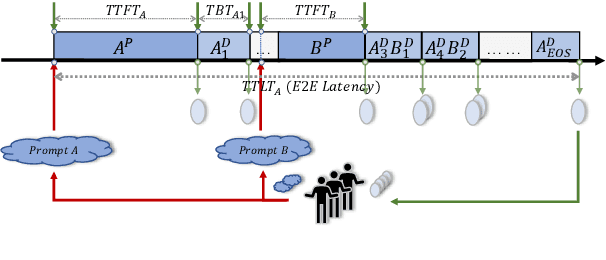
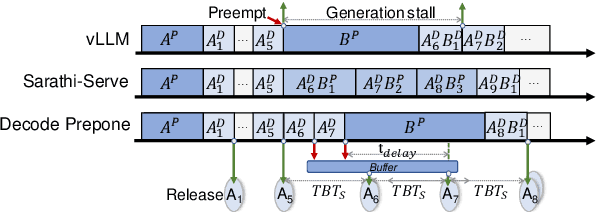
Large language models (LLMs) have achieved remarkable performance and are widely deployed in various applications, while the serving of LLM inference has raised concerns about user experience and serving throughput. Accordingly, service level objectives (SLOs) and goodput-the number of requests that meet SLOs per second-are introduced to evaluate the performance of LLM serving. However, existing metrics fail to capture the nature of user experience. We observe two ridiculous phenomena in existing metrics: 1) delaying token delivery can smooth the tail time between tokens (tail TBT) of a request and 2) dropping the request that fails to meet the SLOs midway can improve goodput. In this paper, we revisit SLO and goodput metrics in LLM serving and propose a unified metric framework smooth goodput including SLOs and goodput to reflect the nature of user experience in LLM serving. The framework can adapt to specific goals of different tasks by setting parameters. We re-evaluate the performance of different LLM serving systems under multiple workloads based on this unified framework and provide possible directions for future optimization of existing strategies. We hope that this framework can provide a unified standard for evaluating LLM serving and foster researches in the field of LLM serving optimization to move in a cohesive direction.
Diversify Question Generation with Retrieval-Augmented Style Transfer
Oct 23, 2023



Given a textual passage and an answer, humans are able to ask questions with various expressions, but this ability is still challenging for most question generation (QG) systems. Existing solutions mainly focus on the internal knowledge within the given passage or the semantic word space for diverse content planning. These methods, however, have not considered the potential of external knowledge for expression diversity. To bridge this gap, we propose RAST, a framework for Retrieval-Augmented Style Transfer, where the objective is to utilize the style of diverse templates for question generation. For training RAST, we develop a novel Reinforcement Learning (RL) based approach that maximizes a weighted combination of diversity reward and consistency reward. Here, the consistency reward is computed by a Question-Answering (QA) model, whereas the diversity reward measures how much the final output mimics the retrieved template. Experimental results show that our method outperforms previous diversity-driven baselines on diversity while being comparable in terms of consistency scores. Our code is available at https://github.com/gouqi666/RAST.