 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Preference Optimization: Reinforcement Learning with Data Selection and Better Reference Model
Mar 28, 2024Large Language Models (LLMs) have become increasingly popular due to their ability to process and generate natural language. However, as they are trained on massive datasets of text, LLMs can inherit harmful biases and produce outputs that are not aligned with human values. This paper studies two main approaches to LLM alignment: Reinforcement Learning with Human Feedback (RLHF) and contrastive learning-based methods like Direct Preference Optimization (DPO). By analyzing the stability and robustness of RLHF and DPO, we propose MPO (Mixed Preference Optimization), a novel method that mitigates the weaknesses of both approaches. Specifically, we propose a two-stage training procedure: first train DPO on an easy dataset, and then perform RLHF on a difficult set with DPO model being the reference model. Here, the easy and difficult sets are constructed by a well-trained reward model that splits response pairs into those with large gaps of reward (easy), and those with small gaps (difficult). The first stage allows us to obtain a relatively optimal policy (LLM) model quickly, whereas the second stage refines LLM with online RLHF, thus mitigating the distribution shift issue associated with DPO. Experiments are conducted on two public alignment datasets, namely HH-RLHF and TLDR, demonstrating the effectiveness of MPO, both in terms of GPT4 and human evaluation.
Diversify Question Generation with Retrieval-Augmented Style Transfer
Oct 23, 2023



Given a textual passage and an answer, humans are able to ask questions with various expressions, but this ability is still challenging for most question generation (QG) systems. Existing solutions mainly focus on the internal knowledge within the given passage or the semantic word space for diverse content planning. These methods, however, have not considered the potential of external knowledge for expression diversity. To bridge this gap, we propose RAST, a framework for Retrieval-Augmented Style Transfer, where the objective is to utilize the style of diverse templates for question generation. For training RAST, we develop a novel Reinforcement Learning (RL) based approach that maximizes a weighted combination of diversity reward and consistency reward. Here, the consistency reward is computed by a Question-Answering (QA) model, whereas the diversity reward measures how much the final output mimics the retrieved template. Experimental results show that our method outperforms previous diversity-driven baselines on diversity while being comparable in terms of consistency scores. Our code is available at https://github.com/gouqi666/RAST.
Improving Question Generation with Multi-level Content Planning
Oct 23, 2023

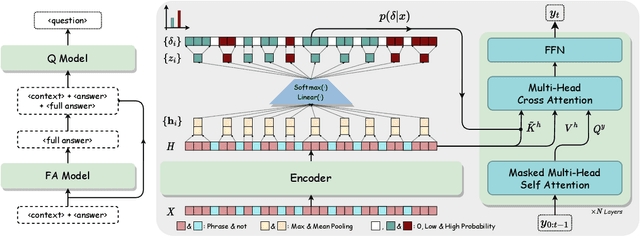

This paper addresses the problem of generating questions from a given context and an answer, specifically focusing on questions that require multi-hop reasoning across an extended context. Previous studies have suggested that key phrase selection is essential for question generation (QG), yet it is still challenging to connect such disjointed phrases into meaningful questions, particularly for long context. To mitigate this issue, we propose MultiFactor, a novel QG framework based on multi-level content planning. Specifically, MultiFactor includes two components: FA-model, which simultaneously selects key phrases and generates full answers, and Q-model which takes the generated full answer as an additional input to generate questions. Here, full answer generation is introduced to connect the short answer with the selected key phrases, thus forming an answer-aware summary to facilitate QG. Both FA-model and Q-model are formalized as simple-yet-effective Phrase-Enhanced Transformers, our joint model for phrase selection and text generation. Experimental results show that our method outperforms strong baselines on two popular QG datasets. Our code is available at https://github.com/zeaver/MultiFactor.
Cross-lingual Data Augmentation for Document-grounded Dialog Systems in Low Resource Languages
May 24, 2023



This paper proposes a framework to address the issue of data scarcity in Document-Grounded Dialogue Systems(DGDS). Our model leverages high-resource languages to enhance the capability of dialogue generation in low-resource languages. Specifically, We present a novel pipeline CLEM (Cross-Lingual Enhanced Model) including adversarial training retrieval (Retriever and Re-ranker), and Fid (fusion-in-decoder) generator. To further leverage high-resource language, we also propose an innovative architecture to conduct alignment across different languages with translated training. Extensive experiment results demonstrate the effectiveness of our model and we achieved 4th place in the DialDoc 2023 Competition. Therefore, CLEM can serve as a solution to resource scarcity in DGDS and provide useful guidance for multi-lingual alignment tasks.