 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Embeddings: Attention Values Encode Sentence Semantics Better Than Hidden States
Feb 02, 2026Sentence representations are foundational to many Natural Language Processing (NLP) applications. While recent methods leverage Large Language Models (LLMs) to derive sentence representations, most rely on final-layer hidden states, which are optimized for next-token prediction and thus often fail to capture global, sentence-level semantics. This paper introduces a novel perspective, demonstrating that attention value vectors capture sentence semantics more effectively than hidden states. We propose Value Aggregation (VA), a simple method that pools token values across multiple layers and token indices. In a training-free setting, VA outperforms other LLM-based embeddings, even matches or surpasses the ensemble-based MetaEOL. Furthermore, we demonstrate that when paired with suitable prompts, the layer attention outputs can be interpreted as aligned weighted value vectors. Specifically, the attention scores of the last token function as the weights, while the output projection matrix ($W_O$) aligns these weighted value vectors with the common space of the LLM residual stream. This refined method, termed Aligned Weighted VA (AlignedWVA), achieves state-of-the-art performance among training-free LLM-based embeddings, outperforming the high-cost MetaEOL by a substantial margin. Finally, we highlight the potential of obtaining strong LLM embedding models through fine-tuning Value Aggregation.
LLMs Meet Isolation Kernel: Lightweight, Learning-free Binary Embeddings for Fast Retrieval
Jan 14, 2026Large language models (LLMs) have recently enabled remarkable progress in text representation. However, their embeddings are typically high-dimensional, leading to substantial storage and retrieval overhead. Although recent approaches such as Matryoshka Representation Learning (MRL) and Contrastive Sparse Representation (CSR) alleviate these issues to some extent, they still suffer from retrieval accuracy degradation. This paper proposes \emph{Isolation Kernel Embedding} or IKE, a learning-free method that transforms an LLM embedding into a binary embedding using Isolation Kernel (IK). IKE is an ensemble of diverse (random) partitions, enabling robust estimation of ideal kernel in the LLM embedding space, thus reducing retrieval accuracy loss as the ensemble grows. Lightweight and based on binary encoding, it offers low memory footprint and fast bitwise computation, lowering retrieval latency. Experiments on multiple text retrieval datasets demonstrate that IKE offers up to 16.7x faster retrieval and 16x lower memory usage than LLM embeddings, while maintaining comparable or better accuracy. Compared to CSR and other compression methods, IKE consistently achieves the best balance between retrieval efficiency and effectiveness.
Retrospex: Language Agent Meets Offline Reinforcement Learning Critic
May 17, 2025Large Language Models (LLMs) possess extensive knowledge and commonsense reasoning capabilities, making them valuable for creating powerful agents. However, existing LLM agent frameworks have not fully utilized past experiences for improvement. This work introduces a new LLM-based agent framework called Retrospex, which addresses this challenge by analyzing past experiences in depth. Unlike previous approaches, Retrospex does not directly integrate experiences into the LLM's context. Instead, it combines the LLM's action likelihood with action values estimated by a Reinforcement Learning (RL) Critic, which is trained on past experiences through an offline ''retrospection'' process. Additionally, Retrospex employs a dynamic action rescoring mechanism that increases the importance of experience-based values for tasks that require more interaction with the environment. We evaluate Retrospex in ScienceWorld, ALFWorld and Webshop environments, demonstrating its advantages over strong, contemporary baselines.
* 17 pages
Corporate Fraud Detection in Rich-yet-Noisy Financial Graph
Feb 26, 2025Corporate fraud detection aims to automatically recognize companies that conduct wrongful activities such as fraudulent financial statements or illegal insider trading. Previous learning-based methods fail to effectively integrate rich interactions in the company network. To close this gap, we collect 18-year financial records in China to form three graph datasets with fraud labels. We analyze the characteristics of the financial graphs, highlighting two pronounced issues: (1) information overload: the dominance of (noisy) non-company nodes over company nodes hinders the message-passing process in Graph Convolution Networks (GCN); and (2) hidden fraud: there exists a large percentage of possible undetected violations in the collected data. The hidden fraud problem will introduce noisy labels in the training dataset and compromise fraud detection results. To handle such challenges, we propose a novel graph-based method, namely, Knowledge-enhanced GCN with Robust Two-stage Learning (${\rm KeGCN}_{R}$), which leverages Knowledge Graph Embeddings to mitigate the information overload and effectively learns rich representations. The proposed model adopts a two-stage learning method to enhance robustness against hidden frauds. Extensive experimental results not only confirm the importance of interactions but also show the superiority of ${\rm KeGCN}_{R}$ over a number of strong baselines in terms of fraud detection effectiveness and robustness.
SynthDoc: Bilingual Documents Synthesis for Visual Document Understanding
Aug 27, 2024



This paper introduces SynthDoc, a novel synthetic document generation pipeline designed to enhance Visual Document Understanding (VDU) by generating high-quality, diverse datasets that include text, images, tables, and charts. Addressing the challenges of data acquisition and the limitations of existing datasets, SynthDoc leverages publicly available corpora and advanced rendering tools to create a comprehensive and versatile dataset. Our experiments, conducted using the Donut model, demonstrate that models trained with SynthDoc's data achieve superior performance in pre-training read tasks and maintain robustness in downstream tasks, despite language inconsistencies. The release of a benchmark dataset comprising 5,000 image-text pairs not only showcases the pipeline's capabilities but also provides a valuable resource for the VDU community to advance research and development in document image recognition. This work significantly contributes to the field by offering a scalable solution to data scarcity and by validating the efficacy of end-to-end models in parsing complex, real-world documents.
Mixed Preference Optimization: Reinforcement Learning with Data Selection and Better Reference Model
Mar 28, 2024Large Language Models (LLMs) have become increasingly popular due to their ability to process and generate natural language. However, as they are trained on massive datasets of text, LLMs can inherit harmful biases and produce outputs that are not aligned with human values. This paper studies two main approaches to LLM alignment: Reinforcement Learning with Human Feedback (RLHF) and contrastive learning-based methods like Direct Preference Optimization (DPO). By analyzing the stability and robustness of RLHF and DPO, we propose MPO (Mixed Preference Optimization), a novel method that mitigates the weaknesses of both approaches. Specifically, we propose a two-stage training procedure: first train DPO on an easy dataset, and then perform RLHF on a difficult set with DPO model being the reference model. Here, the easy and difficult sets are constructed by a well-trained reward model that splits response pairs into those with large gaps of reward (easy), and those with small gaps (difficult). The first stage allows us to obtain a relatively optimal policy (LLM) model quickly, whereas the second stage refines LLM with online RLHF, thus mitigating the distribution shift issue associated with DPO. Experiments are conducted on two public alignment datasets, namely HH-RLHF and TLDR, demonstrating the effectiveness of MPO, both in terms of GPT4 and human evaluation.
Mitigating the Impact of False Negatives in Dense Retrieval with Contrastive Confidence Regularization
Jan 13, 2024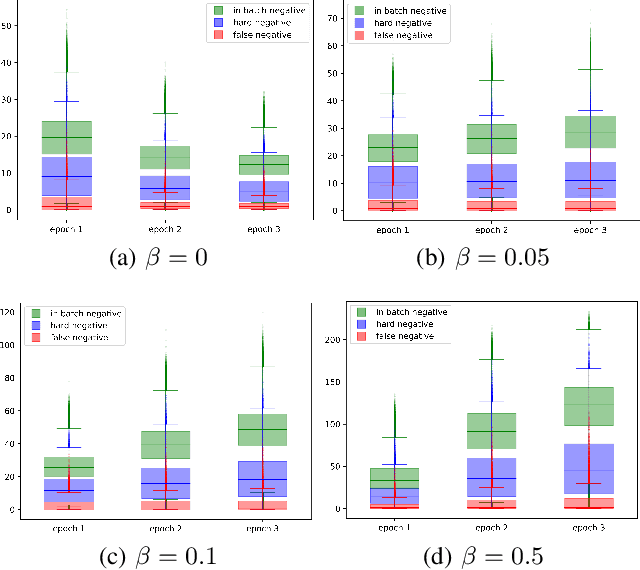
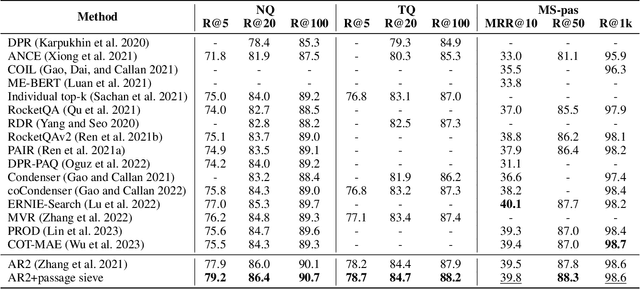
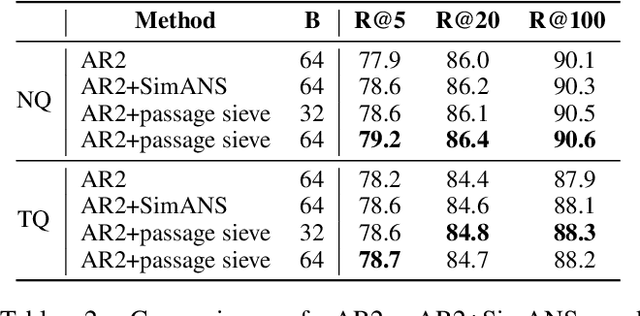
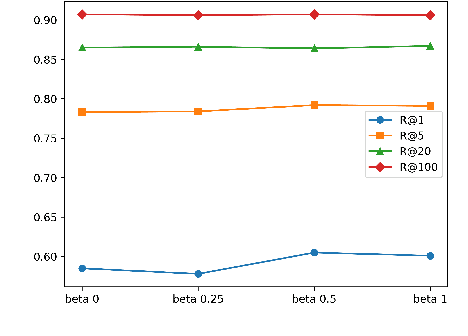
In open-domain Question Answering (QA), dense retrieval is crucial for finding relevant passages for answer generation. Typically, contrastive learning is used to train a retrieval model that maps passages and queries to the same semantic space. The objective is to make similar ones closer and dissimilar ones further apart. However, training such a system is challenging due to the false negative issue, where relevant passages may be missed during data annotation. Hard negative sampling, which is commonly used to improve contrastive learning, can introduce more noise in training. This is because hard negatives are those closer to a given query, and thus more likely to be false negatives. To address this issue, we propose a novel contrastive confidence regularizer for Noise Contrastive Estimation (NCE) loss, a commonly used loss for dense retrieval. Our analysis shows that the regularizer helps dense retrieval models be more robust against false negatives with a theoretical guarantee. Additionally, we propose a model-agnostic method to filter out noisy negative passages in the dataset, improving any downstream dense retrieval models. Through experiments on three datasets, we demonstrate that our method achieves better retrieval performance in comparison to existing state-of-the-art dense retrieval systems.
Long Short-Term Planning for Conversational Recommendation Systems
Oct 23, 2023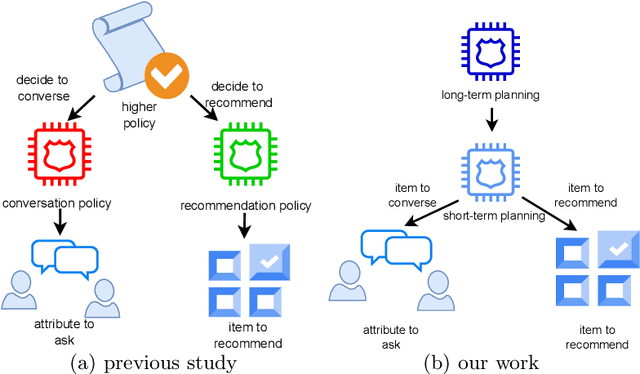

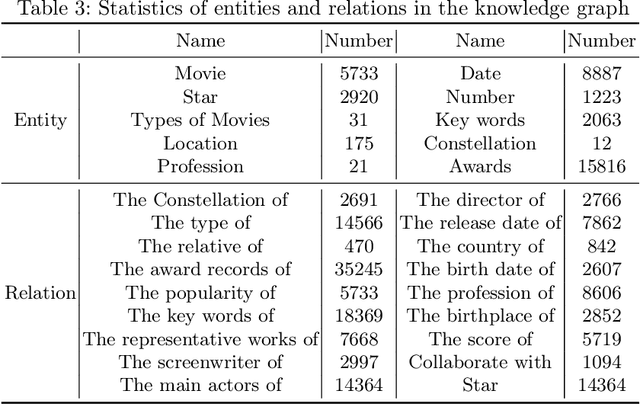
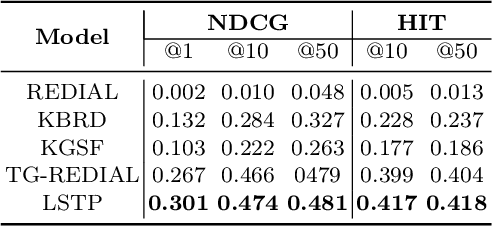
In Conversational Recommendation Systems (CRS), the central question is how the conversational agent can naturally ask for user preferences and provide suitable recommendations. Existing works mainly follow the hierarchical architecture, where a higher policy decides whether to invoke the conversation module (to ask questions) or the recommendation module (to make recommendations). This architecture prevents these two components from fully interacting with each other. In contrast, this paper proposes a novel architecture, the long short-term feedback architecture, to connect these two essential components in CRS. Specifically, the recommendation predicts the long-term recommendation target based on the conversational context and the user history. Driven by the targeted recommendation, the conversational model predicts the next topic or attribute to verify if the user preference matches the target. The balance feedback loop continues until the short-term planner output matches the long-term planner output, that is when the system should make the recommendation.
Improving Question Generation with Multi-level Content Planning
Oct 23, 2023

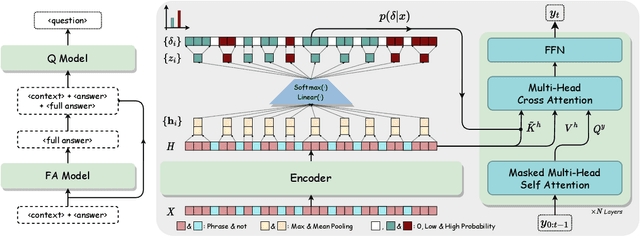

This paper addresses the problem of generating questions from a given context and an answer, specifically focusing on questions that require multi-hop reasoning across an extended context. Previous studies have suggested that key phrase selection is essential for question generation (QG), yet it is still challenging to connect such disjointed phrases into meaningful questions, particularly for long context. To mitigate this issue, we propose MultiFactor, a novel QG framework based on multi-level content planning. Specifically, MultiFactor includes two components: FA-model, which simultaneously selects key phrases and generates full answers, and Q-model which takes the generated full answer as an additional input to generate questions. Here, full answer generation is introduced to connect the short answer with the selected key phrases, thus forming an answer-aware summary to facilitate QG. Both FA-model and Q-model are formalized as simple-yet-effective Phrase-Enhanced Transformers, our joint model for phrase selection and text generation. Experimental results show that our method outperforms strong baselines on two popular QG datasets. Our code is available at https://github.com/zeaver/MultiFactor.
Revisiting the Role of Similarity and Dissimilarity in Best Counter Argument Retrieval
Apr 19, 2023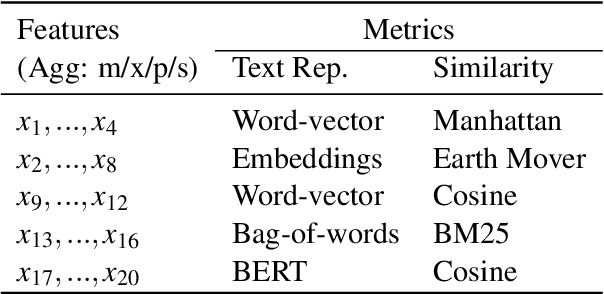
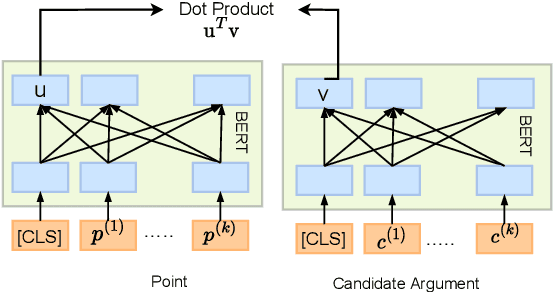
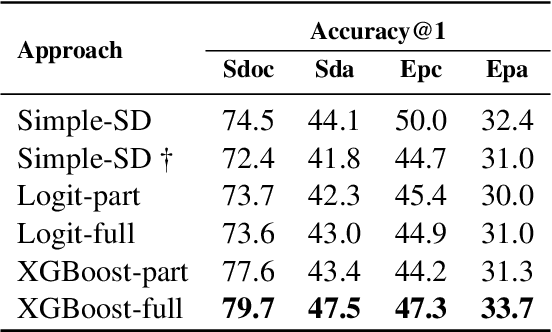
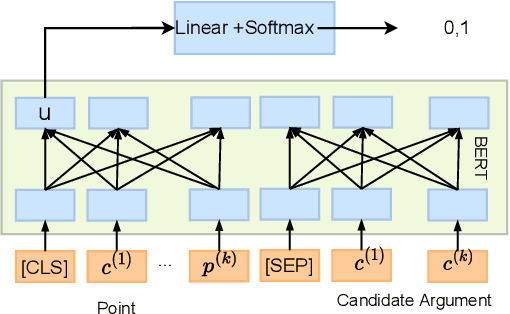
This paper studies the task of best counter-argument retrieval given an input argument. Following the definition that the best counter-argument addresses the same aspects as the input argument while having the opposite stance, we aim to develop an efficient and effective model for scoring counter-arguments based on similarity and dissimilarity metrics. We first conduct an experimental study on the effectiveness of available scoring methods, including traditional Learning-To-Rank (LTR) and recent neural scoring models. We then propose Bipolar-encoder, a novel BERT-based model to learn an optimal representation for simultaneous similarity and dissimilarity. Experimental results show that our proposed method can achieve the accuracy@1 of 49.04\%, which significantly outperforms other baselines by a large margin. When combined with an appropriate caching technique, Bipolar-encoder is comparably efficient at prediction time.