 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-based Embeddings: Attention Values Encode Sentence Semantics Better Than Hidden States
Feb 02, 2026Sentence representations are foundational to many Natural Language Processing (NLP) applications. While recent methods leverage Large Language Models (LLMs) to derive sentence representations, most rely on final-layer hidden states, which are optimized for next-token prediction and thus often fail to capture global, sentence-level semantics. This paper introduces a novel perspective, demonstrating that attention value vectors capture sentence semantics more effectively than hidden states. We propose Value Aggregation (VA), a simple method that pools token values across multiple layers and token indices. In a training-free setting, VA outperforms other LLM-based embeddings, even matches or surpasses the ensemble-based MetaEOL. Furthermore, we demonstrate that when paired with suitable prompts, the layer attention outputs can be interpreted as aligned weighted value vectors. Specifically, the attention scores of the last token function as the weights, while the output projection matrix ($W_O$) aligns these weighted value vectors with the common space of the LLM residual stream. This refined method, termed Aligned Weighted VA (AlignedWVA), achieves state-of-the-art performance among training-free LLM-based embeddings, outperforming the high-cost MetaEOL by a substantial margin. Finally, we highlight the potential of obtaining strong LLM embedding models through fine-tuning Value Aggregation.
Retrospex: Language Agent Meets Offline Reinforcement Learning Critic
May 17, 2025Large Language Models (LLMs) possess extensive knowledge and commonsense reasoning capabilities, making them valuable for creating powerful agents. However, existing LLM agent frameworks have not fully utilized past experiences for improvement. This work introduces a new LLM-based agent framework called Retrospex, which addresses this challenge by analyzing past experiences in depth. Unlike previous approaches, Retrospex does not directly integrate experiences into the LLM's context. Instead, it combines the LLM's action likelihood with action values estimated by a Reinforcement Learning (RL) Critic, which is trained on past experiences through an offline ''retrospection'' process. Additionally, Retrospex employs a dynamic action rescoring mechanism that increases the importance of experience-based values for tasks that require more interaction with the environment. We evaluate Retrospex in ScienceWorld, ALFWorld and Webshop environments, demonstrating its advantages over strong, contemporary baselines.
* 17 pages
Mitigating the Impact of False Negatives in Dense Retrieval with Contrastive Confidence Regularization
Jan 13, 2024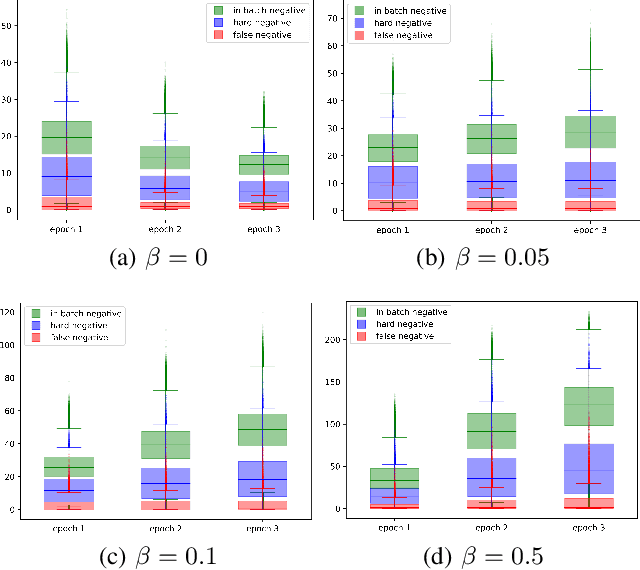
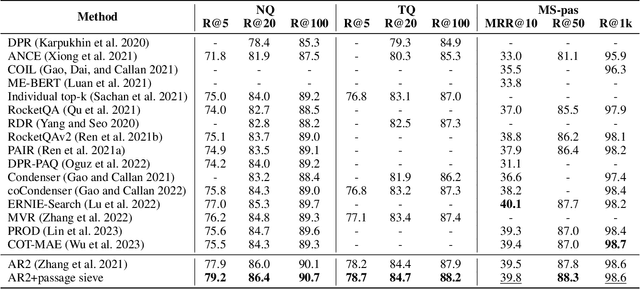
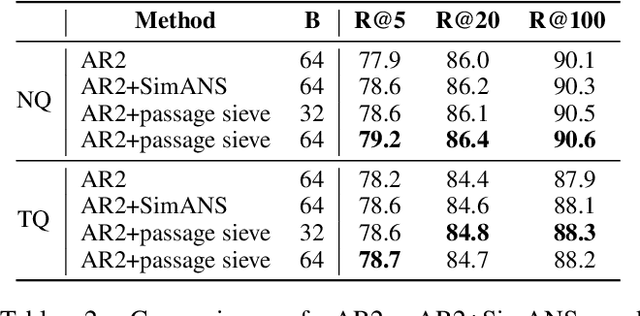
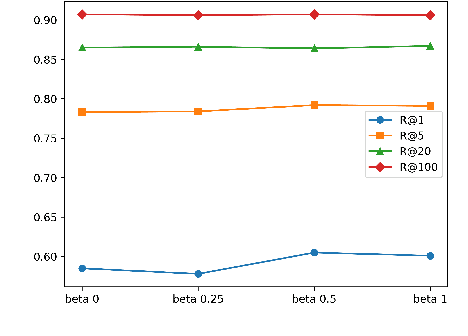
In open-domain Question Answering (QA), dense retrieval is crucial for finding relevant passages for answer generation. Typically, contrastive learning is used to train a retrieval model that maps passages and queries to the same semantic space. The objective is to make similar ones closer and dissimilar ones further apart. However, training such a system is challenging due to the false negative issue, where relevant passages may be missed during data annotation. Hard negative sampling, which is commonly used to improve contrastive learning, can introduce more noise in training. This is because hard negatives are those closer to a given query, and thus more likely to be false negatives. To address this issue, we propose a novel contrastive confidence regularizer for Noise Contrastive Estimation (NCE) loss, a commonly used loss for dense retrieval. Our analysis shows that the regularizer helps dense retrieval models be more robust against false negatives with a theoretical guarantee. Additionally, we propose a model-agnostic method to filter out noisy negative passages in the dataset, improving any downstream dense retrieval models. Through experiments on three datasets, we demonstrate that our method achieves better retrieval performance in comparison to existing state-of-the-art dense retrieval systems.
Long Short-Term Planning for Conversational Recommendation Systems
Oct 23, 2023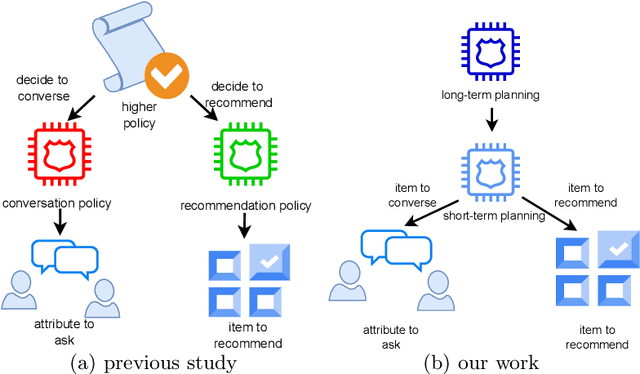

In Conversational Recommendation Systems (CRS), the central question is how the conversational agent can naturally ask for user preferences and provide suitable recommendations. Existing works mainly follow the hierarchical architecture, where a higher policy decides whether to invoke the conversation module (to ask questions) or the recommendation module (to make recommendations). This architecture prevents these two components from fully interacting with each other. In contrast, this paper proposes a novel architecture, the long short-term feedback architecture, to connect these two essential components in CRS. Specifically, the recommendation predicts the long-term recommendation target based on the conversational context and the user history. Driven by the targeted recommendation, the conversational model predicts the next topic or attribute to verify if the user preference matches the target. The balance feedback loop continues until the short-term planner output matches the long-term planner output, that is when the system should make the recommendation.
Coarse-to-Fine Knowledge Selection for Document Grounded Dialogs
Feb 23, 2023

Multi-document grounded dialogue systems (DGDS) belong to a class of conversational agents that answer users' requests by finding supporting knowledge from a collection of documents. Most previous studies aim to improve the knowledge retrieval model or propose more effective ways to incorporate external knowledge into a parametric generation model. These methods, however, focus on retrieving knowledge from mono-granularity language units (e.g. passages, sentences, or spans in documents), which is not enough to effectively and efficiently capture precise knowledge in long documents. This paper proposes Re3G, which aims to optimize both coarse-grained knowledge retrieval and fine-grained knowledge extraction in a unified framework. Specifically, the former efficiently finds relevant passages in a retrieval-and-reranking process, whereas the latter effectively extracts finer-grain spans within those passages to incorporate into a parametric answer generation model (BART, T5). Experiments on DialDoc Shared Task demonstrate the effectiveness of our method.