 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Superficial Unlearning: Sharpness-Aware Robust Erasure of Hallucinations in Multimodal LLMs
Jan 23, 2026Multimodal LLMs are powerful but prone to object hallucinations, which describe non-existent entities and harm reliability. While recent unlearning methods attempt to mitigate this, we identify a critical flaw: structural fragility. We empirically demonstrate that standard erasure achieves only superficial suppression, trapping the model in sharp minima where hallucinations catastrophically resurge after lightweight relearning. To ensure geometric stability, we propose SARE, which casts unlearning as a targeted min-max optimization problem and uses a Targeted-SAM mechanism to explicitly flatten the loss landscape around hallucinated concepts. By suppressing hallucinations under simulated worst-case parameter perturbations, our framework ensures robust removal stable against weight shifts. Extensive experiments demonstrate that SARE significantly outperforms baselines in erasure efficacy while preserving general generation quality. Crucially, it maintains persistent hallucination suppression against relearning and parameter updates, validating the effectiveness of geometric stabilization.
Your One-Stop Solution for AI-Generated Video Detection
Jan 16, 2026Recent advances in generative modeling can create remarkably realistic synthetic videos, making it increasingly difficult for humans to distinguish them from real ones and necessitating reliable detection methods. However, two key limitations hinder the development of this field. \textbf{From the dataset perspective}, existing datasets are often limited in scale and constructed using outdated or narrowly scoped generative models, making it difficult to capture the diversity and rapid evolution of modern generative techniques. Moreover, the dataset construction process frequently prioritizes quantity over quality, neglecting essential aspects such as semantic diversity, scenario coverage, and technological representativeness. \textbf{From the benchmark perspective}, current benchmarks largely remain at the stage of dataset creation, leaving many fundamental issues and in-depth analysis yet to be systematically explored. Addressing this gap, we propose AIGVDBench, a benchmark designed to be comprehensive and representative, covering \textbf{31} state-of-the-art generation models and over \textbf{440,000} videos. By executing more than \textbf{1,500} evaluations on \textbf{33} existing detectors belonging to four distinct categories. This work presents \textbf{8 in-depth analyses} from multiple perspectives and identifies \textbf{4 novel findings} that offer valuable insights for future research. We hope this work provides a solid foundation for advancing the field of AI-generated video detection. Our benchmark is open-sourced at https://github.com/LongMa-2025/AIGVDBench.
ExpSeek: Self-Triggered Experience Seeking for Web Agents
Jan 13, 2026Experience intervention in web agents emerges as a promising technical paradigm, enhancing agent interaction capabilities by providing valuable insights from accumulated experiences. However, existing methods predominantly inject experience passively as global context before task execution, struggling to adapt to dynamically changing contextual observations during agent-environment interaction. We propose ExpSeek, which shifts experience toward step-level proactive seeking: (1) estimating step-level entropy thresholds to determine intervention timing using the model's intrinsic signals; (2) designing step-level tailor-designed experience content. Experiments on Qwen3-8B and 32B models across four challenging web agent benchmarks demonstrate that ExpSeek achieves absolute improvements of 9.3% and 7.5%, respectively. Our experiments validate the feasibility and advantages of entropy as a self-triggering signal, reveal that even a 4B small-scale experience model can significantly boost the performance of larger agent models.
EvoRoute: Experience-Driven Self-Routing LLM Agent Systems
Jan 06, 2026Complex agentic AI systems, powered by a coordinated ensemble of Large Language Models (LLMs), tool and memory modules, have demonstrated remarkable capabilities on intricate, multi-turn tasks. However, this success is shadowed by prohibitive economic costs and severe latency, exposing a critical, yet underexplored, trade-off. We formalize this challenge as the \textbf{Agent System Trilemma}: the inherent tension among achieving state-of-the-art performance, minimizing monetary cost, and ensuring rapid task completion. To dismantle this trilemma, we introduce EvoRoute, a self-evolving model routing paradigm that transcends static, pre-defined model assignments. Leveraging an ever-expanding knowledge base of prior experience, EvoRoute dynamically selects Pareto-optimal LLM backbones at each step, balancing accuracy, efficiency, and resource use, while continually refining its own selection policy through environment feedback. Experiments on challenging agentic benchmarks such as GAIA and BrowseComp+ demonstrate that EvoRoute, when integrated into off-the-shelf agentic systems, not only sustains or enhances system performance but also reduces execution cost by up to $80\%$ and latency by over $70\%$.
CME-CAD: Heterogeneous Collaborative Multi-Expert Reinforcement Learning for CAD Code Generation
Dec 29, 2025Computer-Aided Design (CAD) is essential in industrial design, but the complexity of traditional CAD modeling and workflows presents significant challenges for automating the generation of high-precision, editable CAD models. Existing methods that reconstruct 3D models from sketches often produce non-editable and approximate models that fall short of meeting the stringent requirements for precision and editability in industrial design. Moreover, the reliance on text or image-based inputs often requires significant manual annotation, limiting their scalability and applicability in industrial settings. To overcome these challenges, we propose the Heterogeneous Collaborative Multi-Expert Reinforcement Learning (CME-CAD) paradigm, a novel training paradigm for CAD code generation. Our approach integrates the complementary strengths of these models, facilitating collaborative learning and improving the model's ability to generate accurate, constraint-compatible, and fully editable CAD models. We introduce a two-stage training process: Multi-Expert Fine-Tuning (MEFT), and Multi-Expert Reinforcement Learning (MERL). Additionally, we present CADExpert, an open-source benchmark consisting of 17,299 instances, including orthographic projections with precise dimension annotations, expert-generated Chain-of-Thought (CoT) processes, executable CADQuery code, and rendered 3D models.
AMap: Distilling Future Priors for Ahead-Aware Online HD Map Construction
Dec 22, 2025



Online High-Definition (HD) map construction is pivotal for autonomous driving. While recent approaches leverage historical temporal fusion to improve performance, we identify a critical safety flaw in this paradigm: it is inherently ``spatially backward-looking." These methods predominantly enhance map reconstruction in traversed areas, offering minimal improvement for the unseen road ahead. Crucially, our analysis of downstream planning tasks reveals a severe asymmetry: while rearward perception errors are often tolerable, inaccuracies in the forward region directly precipitate hazardous driving maneuvers. To bridge this safety gap, we propose AMap, a novel framework for Ahead-aware online HD Mapping. We pioneer a ``distill-from-future" paradigm, where a teacher model with privileged access to future temporal contexts guides a lightweight student model restricted to the current frame. This process implicitly compresses prospective knowledge into the student model, endowing it with ``look-ahead" capabilities at zero inference-time cost. Technically, we introduce a Multi-Level BEV Distillation strategy with spatial masking and an Asymmetric Query Adaptation module to effectively transfer future-aware representations to the student's static queries. Extensive experiments on the nuScenes and Argoverse 2 benchmark demonstrate that AMap significantly enhances current-frame perception. Most notably, it outperforms state-of-the-art temporal models in critical forward regions while maintaining the efficiency of single current frame inference.
SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
Oct 14, 2025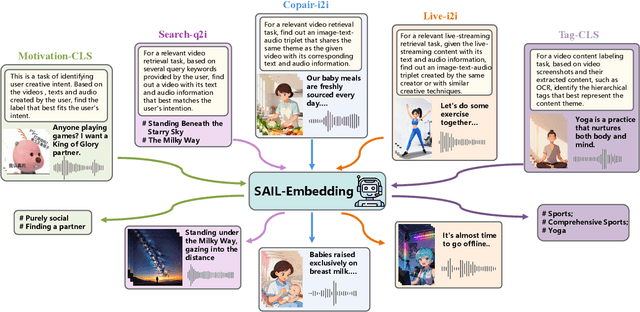

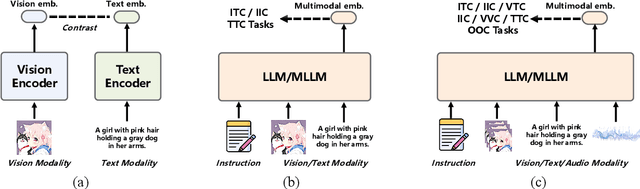
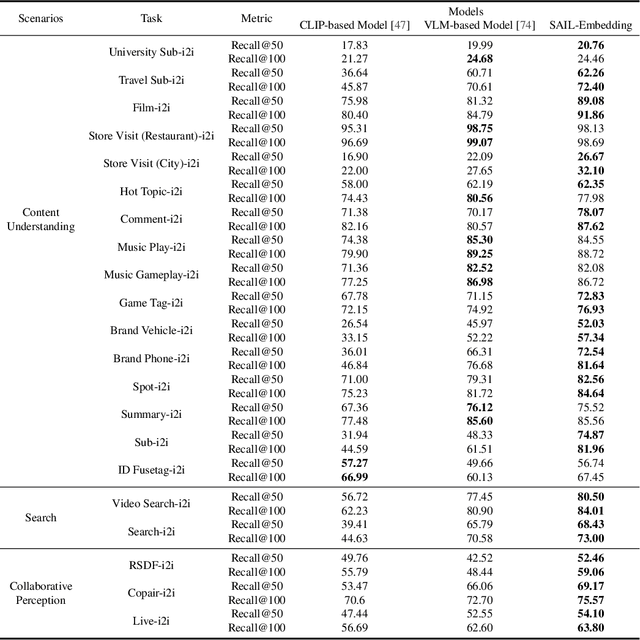
Multimodal embedding models aim to yield informative unified representations that empower diverse cross-modal tasks. Despite promising developments in the evolution from CLIP-based dual-tower architectures to large vision-language models, prior works still face unavoidable challenges in real-world applications and business scenarios, such as the limited modality support, unstable training mechanisms, and industrial domain gaps. In this work, we introduce SAIL-Embedding, an omni-modal embedding foundation model that addresses these issues through tailored training strategies and architectural design. In the optimization procedure, we propose a multi-stage training scheme to boost the multifaceted effectiveness of representation learning. Specifically, the content-aware progressive training aims to enhance the model's adaptability to diverse downstream tasks and master enriched cross-modal proficiency. The collaboration-aware recommendation enhancement training further adapts multimodal representations for recommendation scenarios by distilling knowledge from sequence-to-item and ID-to-item embeddings while mining user historical interests. Concurrently, we develop the stochastic specialization and dataset-driven pattern matching to strengthen model training flexibility and generalizability. Experimental results show that SAIL-Embedding achieves SOTA performance compared to other methods in different retrieval tasks. In online experiments across various real-world scenarios integrated with our model, we observe a significant increase in Lifetime (LT), which is a crucial indicator for the recommendation experience. For instance, the model delivers the 7-day LT gain of +0.158% and the 14-day LT gain of +0.144% in the Douyin-Selected scenario. For the Douyin feed rank model, the match features produced by SAIL-Embedding yield a +0.08% AUC gain.
SAIL-VL2 Technical Report
Sep 18, 2025We introduce SAIL-VL2, an open-suite vision-language foundation model (LVM) for comprehensive multimodal understanding and reasoning. As the successor to SAIL-VL, SAIL-VL2 achieves state-of-the-art performance at the 2B and 8B parameter scales across diverse image and video benchmarks, demonstrating strong capabilities from fine-grained perception to complex reasoning. Its effectiveness is driven by three core innovations. First, a large-scale data curation pipeline with scoring and filtering strategies enhances both quality and distribution across captioning, OCR, QA, and video data, improving training efficiency. Second, a progressive training framework begins with a powerful pre-trained vision encoder (SAIL-ViT), advances through multimodal pre-training, and culminates in a thinking-fusion SFT-RL hybrid paradigm that systematically strengthens model capabilities. Third, architectural advances extend beyond dense LLMs to efficient sparse Mixture-of-Experts (MoE) designs. With these contributions, SAIL-VL2 demonstrates competitive performance across 106 datasets and achieves state-of-the-art results on challenging reasoning benchmarks such as MMMU and MathVista. Furthermore, on the OpenCompass leaderboard, SAIL-VL2-2B ranks first among officially released open-source models under the 4B parameter scale, while serving as an efficient and extensible foundation for the open-source multimodal community.
From Intent to Execution: Multimodal Chain-of-Thought Reinforcement Learning for Precise CAD Code Generation
Aug 13, 2025Computer-Aided Design (CAD) plays a vital role in engineering and manufacturing, yet current CAD workflows require extensive domain expertise and manual modeling effort. Recent advances in large language models (LLMs) have made it possible to generate code from natural language, opening new opportunities for automating parametric 3D modeling. However, directly translating human design intent into executable CAD code remains highly challenging, due to the need for logical reasoning, syntactic correctness, and numerical precision. In this work, we propose CAD-RL, a multimodal Chain-of-Thought (CoT) guided reinforcement learning post training framework for CAD modeling code generation. Our method combines CoT-based Cold Start with goal-driven reinforcement learning post training using three task-specific rewards: executability reward, geometric accuracy reward, and external evaluation reward. To ensure stable policy learning under sparse and high-variance reward conditions, we introduce three targeted optimization strategies: Trust Region Stretch for improved exploration, Precision Token Loss for enhanced dimensions parameter accuracy, and Overlong Filtering to reduce noisy supervision. To support training and benchmarking, we release ExeCAD, a noval dataset comprising 16,540 real-world CAD examples with paired natural language and structured design language descriptions, executable CADQuery scripts, and rendered 3D models. Experiments demonstrate that CAD-RL achieves significant improvements in reasoning quality, output precision, and code executability over existing VLMs.
Interpretable Oracle Bone Script Decipherment through Radical and Pictographic Analysis with LVLMs
Aug 13, 2025As the oldest mature writing system, Oracle Bone Script (OBS) has long posed significant challenges for archaeological decipherment due to its rarity, abstractness, and pictographic diversity. Current deep learning-based methods have made exciting progress on the OBS decipherment task, but existing approaches often ignore the intricate connections between glyphs and the semantics of OBS. This results in limited generalization and interpretability, especially when addressing zero-shot settings and undeciphered OBS. To this end, we propose an interpretable OBS decipherment method based on Large Vision-Language Models, which synergistically combines radical analysis and pictograph-semantic understanding to bridge the gap between glyphs and meanings of OBS. Specifically, we propose a progressive training strategy that guides the model from radical recognition and analysis to pictographic analysis and mutual analysis, thus enabling reasoning from glyph to meaning. We also design a Radical-Pictographic Dual Matching mechanism informed by the analysis results, significantly enhancing the model's zero-shot decipherment performance. To facilitate model training, we propose the Pictographic Decipherment OBS Dataset, which comprises 47,157 Chinese characters annotated with OBS images and pictographic analysis texts. Experimental results on public benchmarks demonstrate that our approach achieves state-of-the-art Top-10 accuracy and superior zero-shot decipherment capabilities. More importantly, our model delivers logical analysis processes, possibly providing archaeologically valuable reference results for undeciphered OBS, and thus has potential applications in digital humanities and historical research. The dataset and code will be released in https://github.com/PKXX1943/PD-OBS.