 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLLM-Creator: Hierarchical LLM-based Personalized Creative Generation
Aug 25, 2025AI-generated content technologies are widely used in content creation. However, current AIGC systems rely heavily on creators' inspiration, rarely generating truly user-personalized content. In real-world applications such as online advertising, a single product may have multiple selling points, with different users focusing on different features. This underscores the significant value of personalized, user-centric creative generation. Effective personalized content generation faces two main challenges: (1) accurately modeling user interests and integrating them into the content generation process while adhering to factual constraints, and (2) ensuring high efficiency and scalability to handle the massive user base in industrial scenarios. Additionally, the scarcity of personalized creative data in practice complicates model training, making data construction another key hurdle. We propose HLLM-Creator, a hierarchical LLM framework for efficient user interest modeling and personalized content generation. During inference, a combination of user clustering and a user-ad-matching-prediction based pruning strategy is employed to significantly enhance generation efficiency and reduce computational overhead, making the approach suitable for large-scale deployment. Moreover, we design a data construction pipeline based on chain-of-thought reasoning, which generates high-quality, user-specific creative titles and ensures factual consistency despite limited personalized data. This pipeline serves as a critical foundation for the effectiveness of our model. Extensive experiments on personalized title generation for Douyin Search Ads show the effectiveness of HLLM-Creator. Online A/B test shows a 0.476% increase on Adss, paving the way for more effective and efficient personalized generation in industrial scenarios. Codes for academic dataset are available at https://github.com/bytedance/HLLM.
Prolonged Reasoning Is Not All You Need: Certainty-Based Adaptive Routing for Efficient LLM/MLLM Reasoning
May 21, 2025



Recent advancements in reasoning have significantly enhanced the capabilities of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) across diverse tasks. However, excessive reliance on chain-of-thought (CoT) reasoning can impair model performance and brings unnecessarily lengthened outputs, reducing efficiency. Our work reveals that prolonged reasoning does not universally improve accuracy and even degrade performance on simpler tasks. To address this, we propose Certainty-based Adaptive Reasoning (CAR), a novel framework that dynamically switches between short answers and long-form reasoning based on the model perplexity. CAR first generates a short answer and evaluates its perplexity, triggering reasoning only when the model exhibits low confidence (i.e., high perplexity). Experiments across diverse multimodal VQA/KIE benchmarks and text reasoning datasets show that CAR outperforms both short-answer and long-form reasoning approaches, striking an optimal balance between accuracy and efficiency.
VeraCT Scan: Retrieval-Augmented Fake News Detection with Justifiable Reasoning
Jun 12, 2024



The proliferation of fake news poses a significant threat not only by disseminating misleading information but also by undermining the very foundations of democracy. The recent advance of generative artificial intelligence has further exacerbated the challenge of distinguishing genuine news from fabricated stories. In response to this challenge, we introduce VeraCT Scan, a novel retrieval-augmented system for fake news detection. This system operates by extracting the core facts from a given piece of news and subsequently conducting an internet-wide search to identify corroborating or conflicting reports. Then sources' credibility is leveraged for information verification. Besides determining the veracity of news, we also provide transparent evidence and reasoning to support its conclusions, resulting in the interpretability and trust in the results. In addition to GPT-4 Turbo, Llama-2 13B is also fine-tuned for news content understanding, information verification, and reasoning. Both implementations have demonstrated state-of-the-art accuracy in the realm of fake news detection.
RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Dec 31, 2023

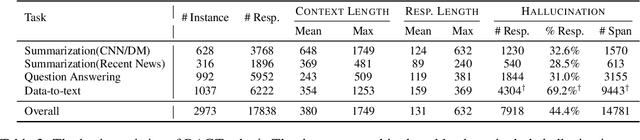

Retrieval-augmented generation (RAG) has become a main technique for alleviating hallucinations in large language models (LLMs). Despite the integration of RAG, LLMs may still present unsupported or contradictory claims to the retrieved contents. In order to develop effective hallucination prevention strategies under RAG, it is important to create benchmark datasets that can measure the extent of hallucination. This paper presents RAGTruth, a corpus tailored for analyzing word-level hallucinations in various domains and tasks within the standard RAG frameworks for LLM applications. RAGTruth comprises nearly 18,000 naturally generated responses from diverse LLMs using RAG. These responses have undergone meticulous manual annotations at both the individual cases and word levels, incorporating evaluations of hallucination intensity. We not only benchmark hallucination frequencies across different LLMs, but also critically assess the effectiveness of several existing hallucination detection methodologies. Furthermore, we show that using a high-quality dataset such as RAGTruth, it is possible to finetune a relatively small LLM and achieve a competitive level of performance in hallucination detection when compared to the existing prompt-based approaches using state-of-the-art large language models such as GPT-4.