 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
Feb 17, 2026Reinforcement Learning (RL) has significantly improved large language model reasoning, but existing RL fine-tuning methods rely heavily on heuristic techniques such as entropy regularization and reweighting to maintain stability. In practice, they often experience late-stage performance collapse, leading to degraded reasoning quality and unstable training. We derive that the magnitude of token-wise policy gradients in RL is negatively correlated with token probability and local policy entropy. Building on this result, we prove that training instability is driven by a tiny fraction of tokens, approximately 0.01\%, which we term \emph{spurious tokens}. When such tokens appear in correct responses, they contribute little to the reasoning outcome but inherit the full sequence-level reward, leading to abnormally amplified gradient updates. Motivated by this observation, we propose Spurious-Token-Aware Policy Optimization (STAPO) for large-scale model refining, which selectively masks such updates and renormalizes the loss over valid tokens. Across six mathematical reasoning benchmarks using Qwen 1.7B, 8B, and 14B base models, STAPO consistently demonstrates superior entropy stability and achieves an average performance improvement of 7.13\% over GRPO, 20-Entropy and JustRL.
VeraCT Scan: Retrieval-Augmented Fake News Detection with Justifiable Reasoning
Jun 12, 2024



The proliferation of fake news poses a significant threat not only by disseminating misleading information but also by undermining the very foundations of democracy. The recent advance of generative artificial intelligence has further exacerbated the challenge of distinguishing genuine news from fabricated stories. In response to this challenge, we introduce VeraCT Scan, a novel retrieval-augmented system for fake news detection. This system operates by extracting the core facts from a given piece of news and subsequently conducting an internet-wide search to identify corroborating or conflicting reports. Then sources' credibility is leveraged for information verification. Besides determining the veracity of news, we also provide transparent evidence and reasoning to support its conclusions, resulting in the interpretability and trust in the results. In addition to GPT-4 Turbo, Llama-2 13B is also fine-tuned for news content understanding, information verification, and reasoning. Both implementations have demonstrated state-of-the-art accuracy in the realm of fake news detection.
Integrated Decision and Control for High-Level Automated Vehicles by Mixed Policy Gradient and Its Experiment Verification
Oct 19, 2022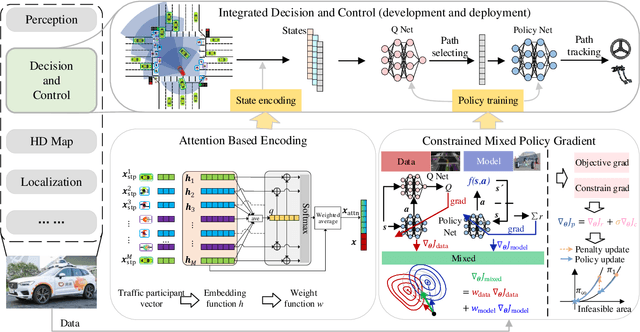
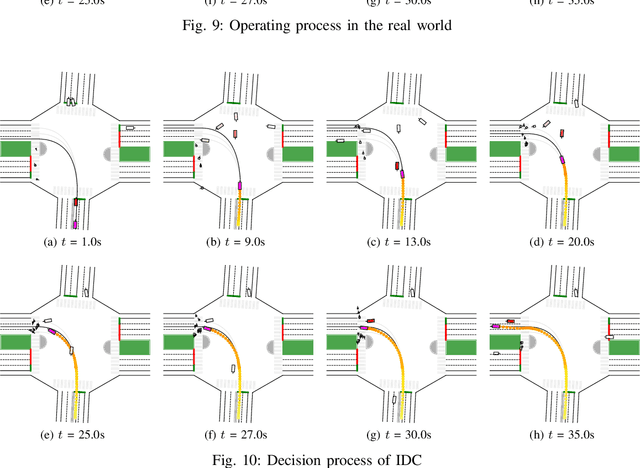
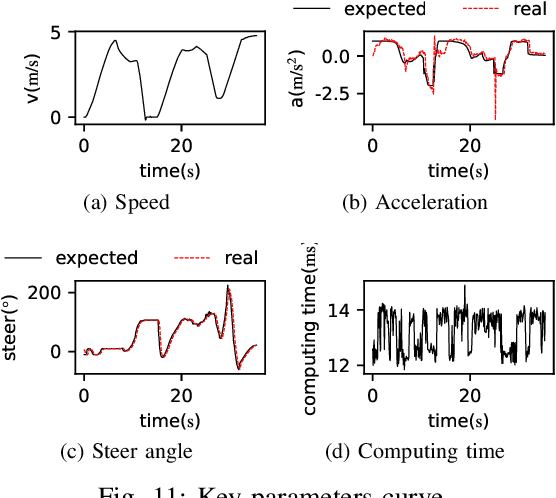
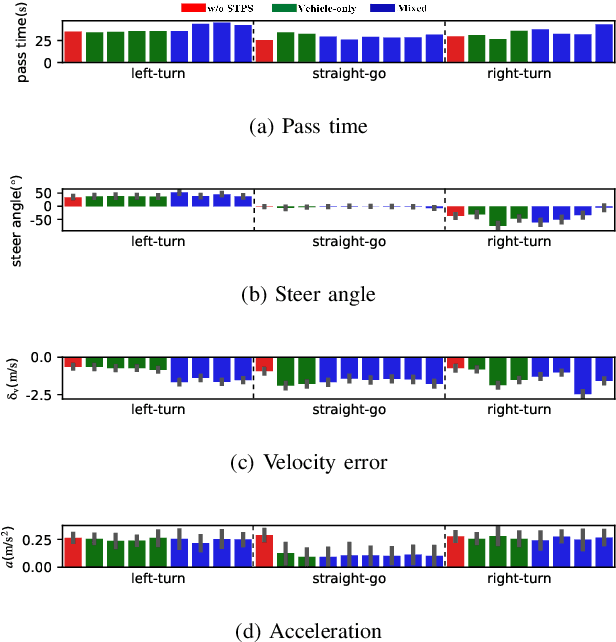
Self-evolution is indispensable to realize full autonomous driving. This paper presents a self-evolving decision-making system based on the Integrated Decision and Control (IDC), an advanced framework built on reinforcement learning (RL). First, an RL algorithm called constrained mixed policy gradient (CMPG) is proposed to consistently upgrade the driving policy of the IDC. It adapts the MPG under the penalty method so that it can solve constrained optimization problems using both the data and model. Second, an attention-based encoding (ABE) method is designed to tackle the state representation issue. It introduces an embedding network for feature extraction and a weighting network for feature fusion, fulfilling order-insensitive encoding and importance distinguishing of road users. Finally, by fusing CMPG and ABE, we develop the first data-driven decision and control system under the IDC architecture, and deploy the system on a fully-functional self-driving vehicle running in daily operation. Experiment results show that boosting by data, the system can achieve better driving ability over model-based methods. It also demonstrates safe, efficient and smart driving behavior in various complex scenes at a signalized intersection with real mixed traffic flow.
PerfectDou: Dominating DouDizhu with Perfect Information Distillation
Apr 05, 2022



As a challenging multi-player card game, DouDizhu has recently drawn much attention for analyzing competition and collaboration in imperfect-information games. In this paper, we propose PerfectDou, a state-of-the-art DouDizhu AI system that dominates the game, in an actor-critic framework with a proposed technique named perfect information distillation. In detail, we adopt a perfect-training-imperfect-execution framework that allows the agents to utilize the global information to guide the training of the policies as if it is a perfect information game and the trained policies can be used to play the imperfect information game during the actual gameplay. To this end, we characterize card and game features for DouDizhu to represent the perfect and imperfect information. To train our system, we adopt proximal policy optimization with generalized advantage estimation in a parallel training paradigm. In experiments we show how and why PerfectDou beats all existing AI programs, and achieves state-of-the-art performance.
Encoding Distributional Soft Actor-Critic for Autonomous Driving in Multi-lane Scenarios
Sep 12, 2021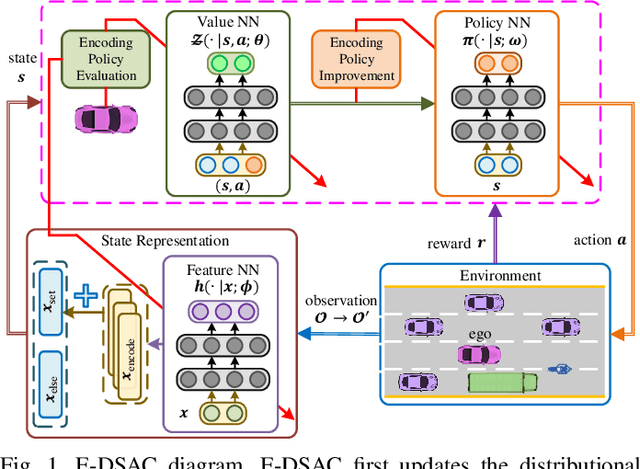
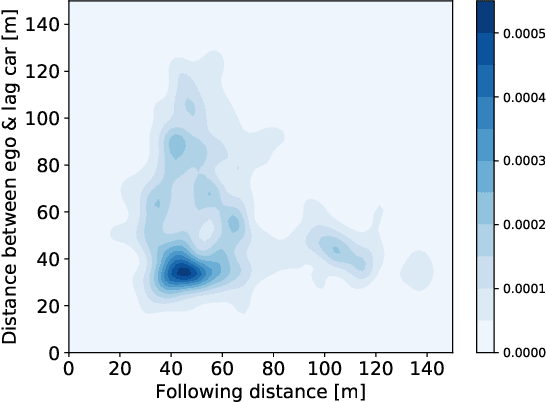
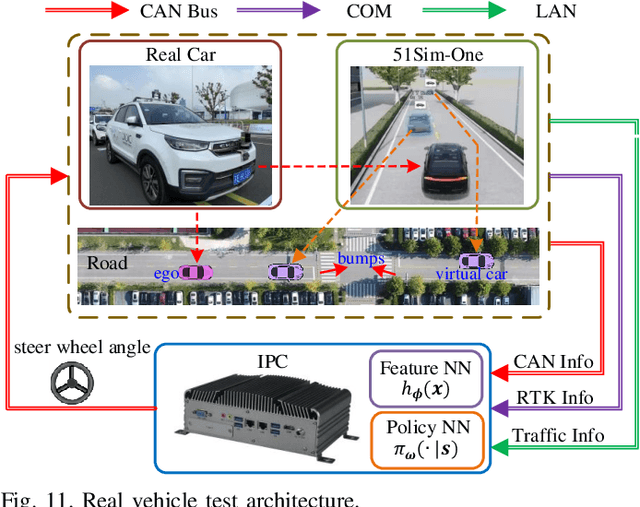
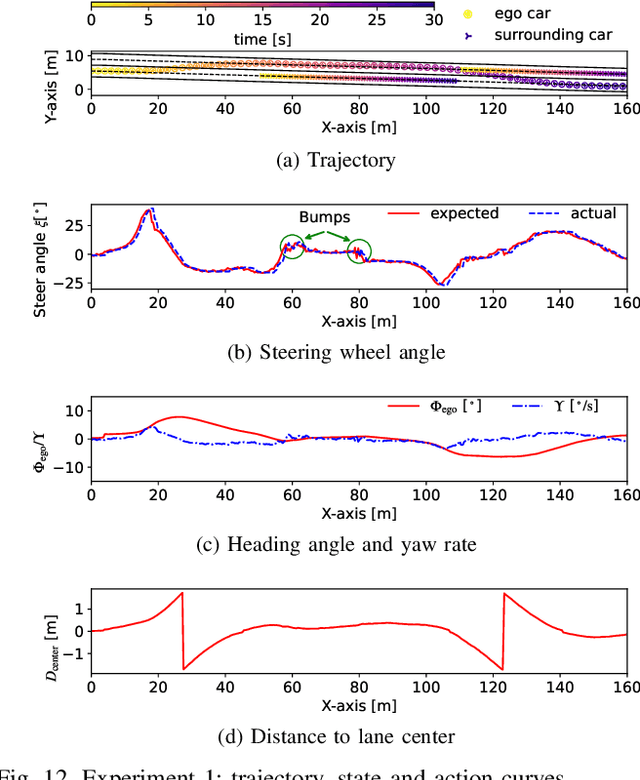
In this paper, we propose a new reinforcement learning (RL) algorithm, called encoding distributional soft actor-critic (E-DSAC), for decision-making in autonomous driving. Unlike existing RL-based decision-making methods, E-DSAC is suitable for situations where the number of surrounding vehicles is variable and eliminates the requirement for manually pre-designed sorting rules, resulting in higher policy performance and generality. We first develop an encoding distributional policy iteration (DPI) framework by embedding a permutation invariant module, which employs a feature neural network (NN) to encode the indicators of each vehicle, in the distributional RL framework. The proposed DPI framework is proved to exhibit important properties in terms of convergence and global optimality. Next, based on the developed encoding DPI framework, we propose the E-DSAC algorithm by adding the gradient-based update rule of the feature NN to the policy evaluation process of the DSAC algorithm. Then, the multi-lane driving task and the corresponding reward function are designed to verify the effectiveness of the proposed algorithm. Results show that the policy learned by E-DSAC can realize efficient, smooth, and relatively safe autonomous driving in the designed scenario. And the final policy performance learned by E-DSAC is about three times that of DSAC. Furthermore, its effectiveness has also been verified in real vehicle experiments.
Integrated Decision and Control at Multi-Lane Intersections with Mixed Traffic Flow
Aug 30, 2021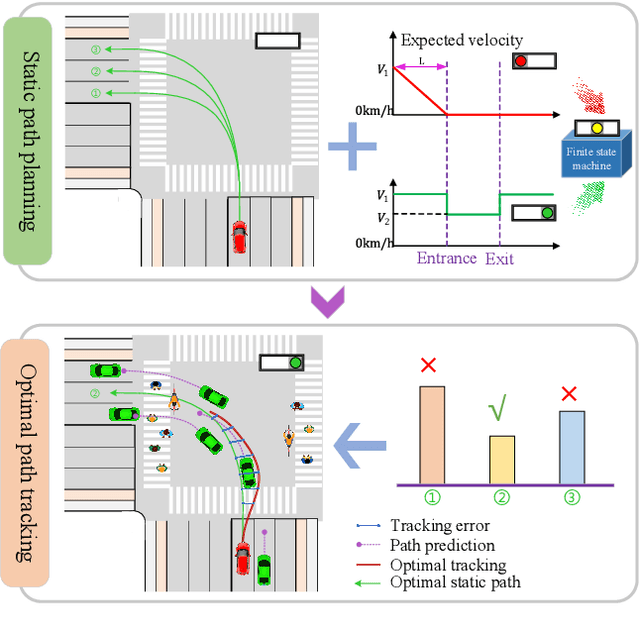
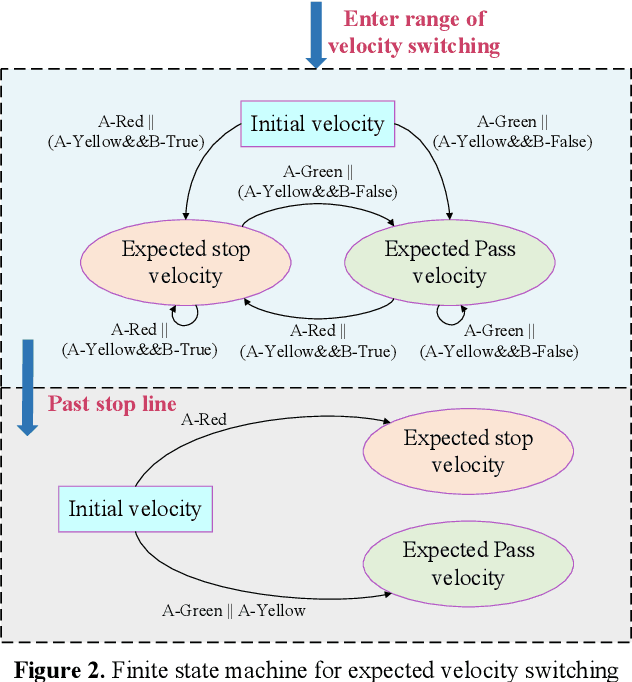
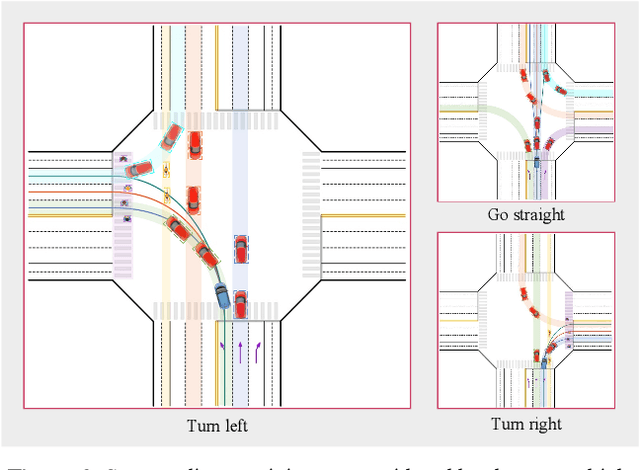
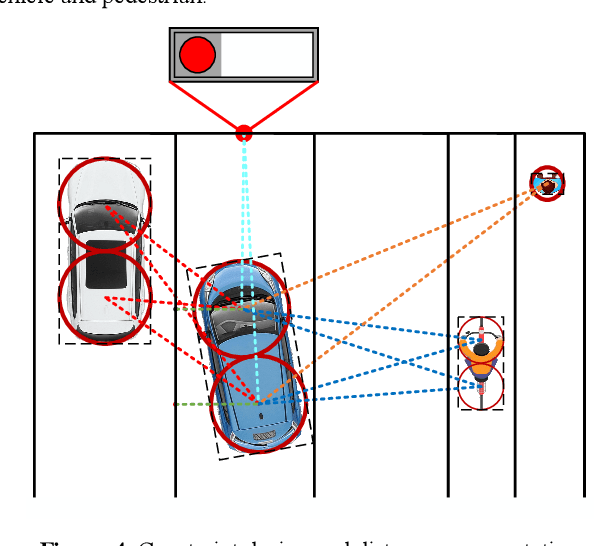
Autonomous driving at intersections is one of the most complicated and accident-prone traffic scenarios, especially with mixed traffic participants such as vehicles, bicycles and pedestrians. The driving policy should make safe decisions to handle the dynamic traffic conditions and meet the requirements of on-board computation. However, most of the current researches focuses on simplified intersections considering only the surrounding vehicles and idealized traffic lights. This paper improves the integrated decision and control framework and develops a learning-based algorithm to deal with complex intersections with mixed traffic flows, which can not only take account of realistic characteristics of traffic lights, but also learn a safe policy under different safety constraints. We first consider different velocity models for green and red lights in the training process and use a finite state machine to handle different modes of light transformation. Then we design different types of distance constraints for vehicles, traffic lights, pedestrians, bicycles respectively and formulize the constrained optimal control problems (OCPs) to be optimized. Finally, reinforcement learning (RL) with value and policy networks is adopted to solve the series of OCPs. In order to verify the safety and efficiency of the proposed method, we design a multi-lane intersection with the existence of large-scale mixed traffic participants and set practical traffic light phases. The simulation results indicate that the trained decision and control policy can well balance safety and tracking performance. Compared with model predictive control (MPC), the computational time is three orders of magnitude lower.
Model-based Chance-Constrained Reinforcement Learning via Separated Proportional-Integral Lagrangian
Aug 26, 2021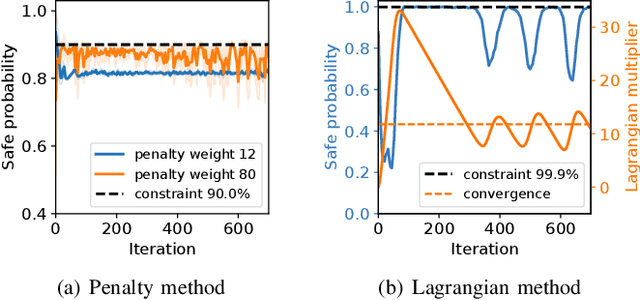
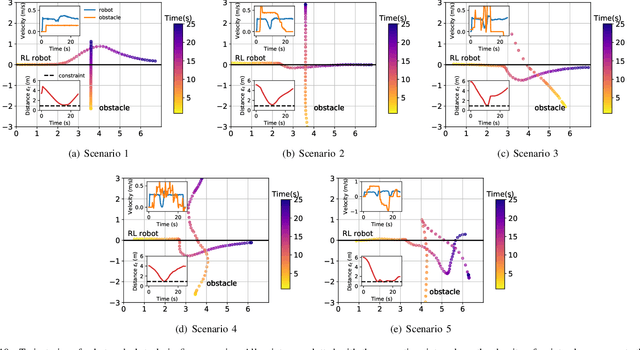
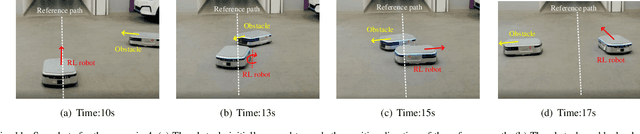

Safety is essential for reinforcement learning (RL) applied in the real world. Adding chance constraints (or probabilistic constraints) is a suitable way to enhance RL safety under uncertainty. Existing chance-constrained RL methods like the penalty methods and the Lagrangian methods either exhibit periodic oscillations or learn an over-conservative or unsafe policy. In this paper, we address these shortcomings by proposing a separated proportional-integral Lagrangian (SPIL) algorithm. We first review the constrained policy optimization process from a feedback control perspective, which regards the penalty weight as the control input and the safe probability as the control output. Based on this, the penalty method is formulated as a proportional controller, and the Lagrangian method is formulated as an integral controller. We then unify them and present a proportional-integral Lagrangian method to get both their merits, with an integral separation technique to limit the integral value in a reasonable range. To accelerate training, the gradient of safe probability is computed in a model-based manner. We demonstrate our method can reduce the oscillations and conservatism of RL policy in a car-following simulation. To prove its practicality, we also apply our method to a real-world mobile robot navigation task, where our robot successfully avoids a moving obstacle with highly uncertain or even aggressive behaviors.
Feasible Actor-Critic: Constrained Reinforcement Learning for Ensuring Statewise Safety
May 28, 2021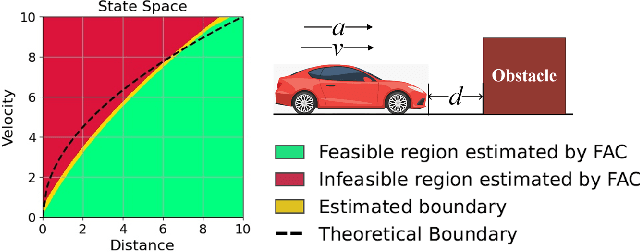


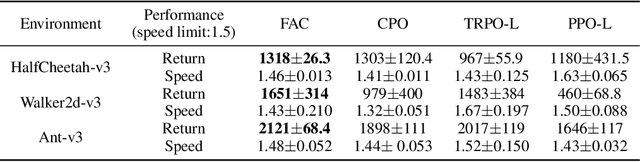
The safety constraints commonly used by existing safe reinforcement learning (RL) methods are defined only on expectation of initial states, but allow each certain state to be unsafe, which is unsatisfying for real-world safety-critical tasks. In this paper, we introduce the feasible actor-critic (FAC) algorithm, which is the first model-free constrained RL method that considers statewise safety, e.g, safety for each initial state. We claim that some states are inherently unsafe no matter what policy we choose, while for other states there exist policies ensuring safety, where we say such states and policies are feasible. By constructing a statewise Lagrange function available on RL sampling and adopting an additional neural network to approximate the statewise Lagrange multiplier, we manage to obtain the optimal feasible policy which ensures safety for each feasible state and the safest possible policy for infeasible states. Furthermore, the trained multiplier net can indicate whether a given state is feasible or not through the statewise complementary slackness condition. We provide theoretical guarantees that FAC outperforms previous expectation-based constrained RL methods in terms of both constraint satisfaction and reward optimization. Experimental results on both robot locomotive tasks and safe exploration tasks verify the safety enhancement and feasibility interpretation of the proposed method.
Integrated Decision and Control: Towards Interpretable and Efficient Driving Intelligence
Mar 18, 2021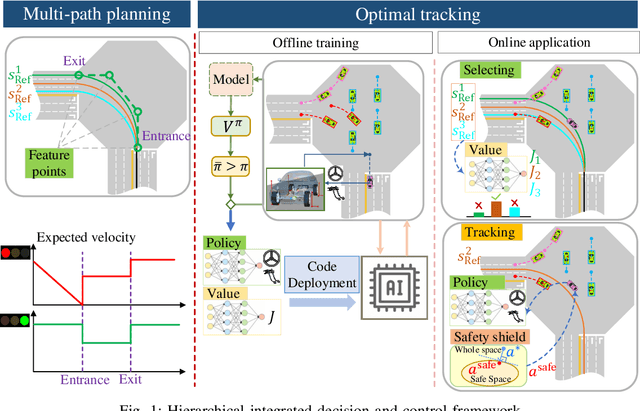
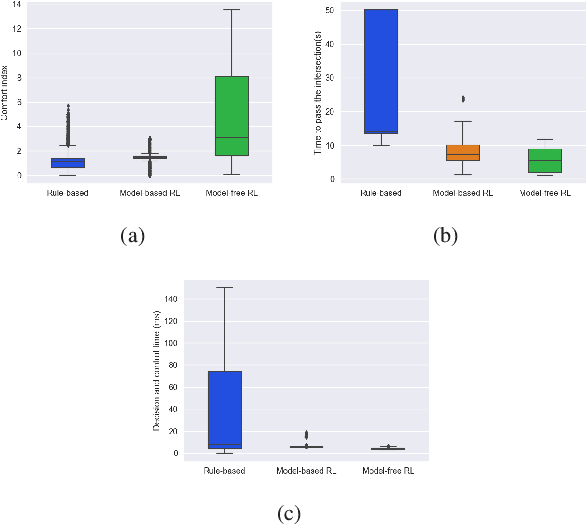
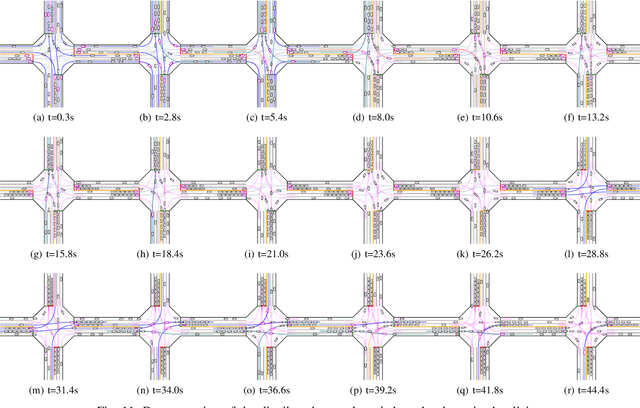
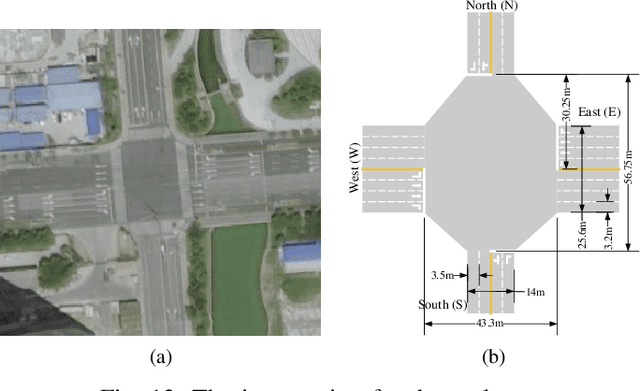
Decision and control are two of the core functionalities of high-level automated vehicles. Current mainstream methods, such as functionality decomposition or end-to-end reinforcement learning (RL), either suffer high time complexity or poor interpretability and limited safety performance in real-world complex autonomous driving tasks. In this paper, we present an interpretable and efficient decision and control framework for automated vehicles, which decomposes the driving task into multi-path planning and optimal tracking that are structured hierarchically. First, the multi-path planning is to generate several paths only considering static constraints. Then, the optimal tracking is designed to track the optimal path while considering the dynamic obstacles. To that end, in theory, we formulate a constrained optimal control problem (OCP) for each candidate path, optimize them separately and choose the one with the best tracking performance to follow. More importantly, we propose a model-based reinforcement learning (RL) algorithm, which is served as an approximate constrained OCP solver, to unload the heavy computation by the paradigm of offline training and online application. Specifically, the OCPs for all paths are considered together to construct a multi-task RL problem and then solved offline by our algorithm into value and policy networks, for real-time online path selecting and tracking respectively. We verify our framework in both simulation and the real world. Results show that our method has better online computing efficiency and driving performance including traffic efficiency and safety compared with baseline methods. In addition, it yields great interpretability and adaptability among different driving tasks. The real road test also suggests that it is applicable in complicated traffic scenarios without even tuning.
Approximate Optimal Filter for Linear Gaussian Time-invariant Systems
Mar 09, 2021
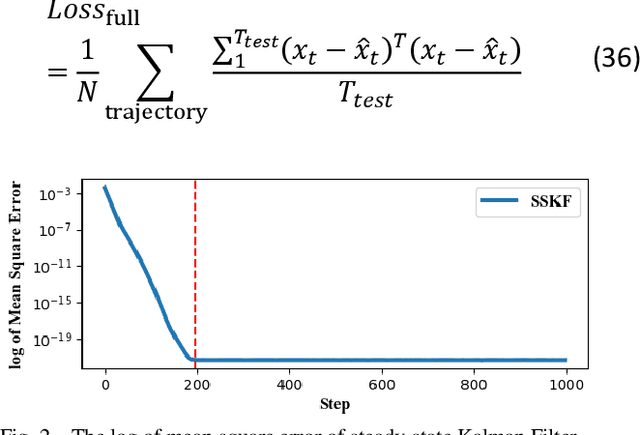

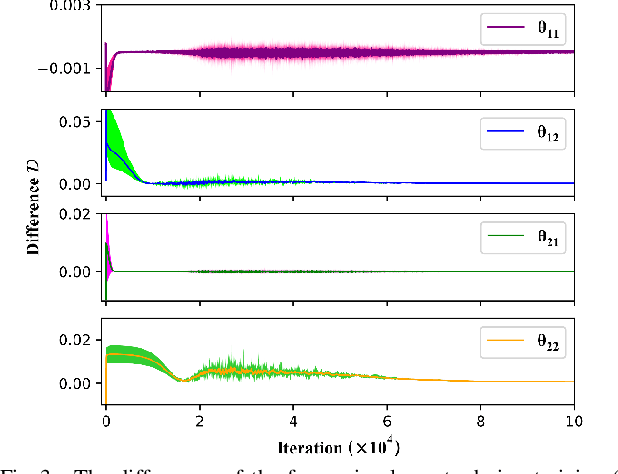
State estimation is critical to control systems, especially when the states cannot be directly measured. This paper presents an approximate optimal filter, which enables to use policy iteration technique to obtain the steady-state gain in linear Gaussian time-invariant systems. This design transforms the optimal filtering problem with minimum mean square error into an optimal control problem, called Approximate Optimal Filtering (AOF) problem. The equivalence holds given certain conditions about initial state distributions and policy formats, in which the system state is the estimation error, control input is the filter gain, and control objective function is the accumulated estimation error. We present a policy iteration algorithm to solve the AOF problem in steady-state. A classic vehicle state estimation problem finally evaluates the approximate filter. The results show that the policy converges to the steady-state Kalman gain, and its accuracy is within 2 %.