 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM4VLA: Revisiting Vision-Language-Models in Vision-Language-Action Models
Jan 06, 2026Vision-Language-Action (VLA) models, which integrate pretrained large Vision-Language Models (VLM) into their policy backbone, are gaining significant attention for their promising generalization capabilities. This paper revisits a fundamental yet seldom systematically studied question: how VLM choice and competence translate to downstream VLA policies performance? We introduce VLM4VLA, a minimal adaptation pipeline that converts general-purpose VLMs into VLA policies using only a small set of new learnable parameters for fair and efficient comparison. Despite its simplicity, VLM4VLA proves surprisingly competitive with more sophisticated network designs. Through extensive empirical studies on various downstream tasks across three benchmarks, we find that while VLM initialization offers a consistent benefit over training from scratch, a VLM's general capabilities are poor predictors of its downstream task performance. This challenges common assumptions, indicating that standard VLM competence is necessary but insufficient for effective embodied control. We further investigate the impact of specific embodied capabilities by fine-tuning VLMs on seven auxiliary embodied tasks (e.g., embodied QA, visual pointing, depth estimation). Contrary to intuition, improving a VLM's performance on specific embodied skills does not guarantee better downstream control performance. Finally, modality-level ablations identify the visual module in VLM, rather than the language component, as the primary performance bottleneck. We demonstrate that injecting control-relevant supervision into the vision encoder of the VLM yields consistent gains, even when the encoder remains frozen during downstream fine-tuning. This isolates a persistent domain gap between current VLM pretraining objectives and the requirements of embodied action-planning.
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Jul 31, 2025Visual-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent work has begun to explore the incorporation of latent actions, an abstract representation of visual change between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Visual-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. Together, these contributions enable villa-X to achieve superior performance across simulated environments including SIMPLER and LIBERO, as well as on two real-world robot setups including gripper and dexterous hand manipulation. We believe the ViLLA paradigm holds significant promise, and that our villa-X provides a strong foundation for future research.
Learning Generalizable Robot Policy with Human Demonstration Video as a Prompt
May 27, 2025Recent robot learning methods commonly rely on imitation learning from massive robotic dataset collected with teleoperation. When facing a new task, such methods generally require collecting a set of new teleoperation data and finetuning the policy. Furthermore, the teleoperation data collection pipeline is also tedious and expensive. Instead, human is able to efficiently learn new tasks by just watching others do. In this paper, we introduce a novel two-stage framework that utilizes human demonstrations to learn a generalizable robot policy. Such policy can directly take human demonstration video as a prompt and perform new tasks without any new teleoperation data and model finetuning at all. In the first stage, we train video generation model that captures a joint representation for both the human and robot demonstration video data using cross-prediction. In the second stage, we fuse the learned representation with a shared action space between human and robot using a novel prototypical contrastive loss. Empirical evaluations on real-world dexterous manipulation tasks show the effectiveness and generalization capabilities of our proposed method.
MARGE: Improving Math Reasoning for LLMs with Guided Exploration
May 18, 2025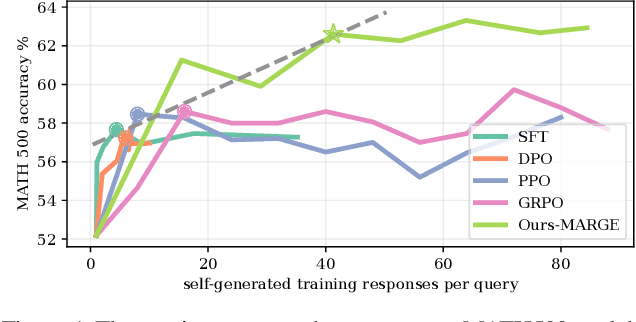
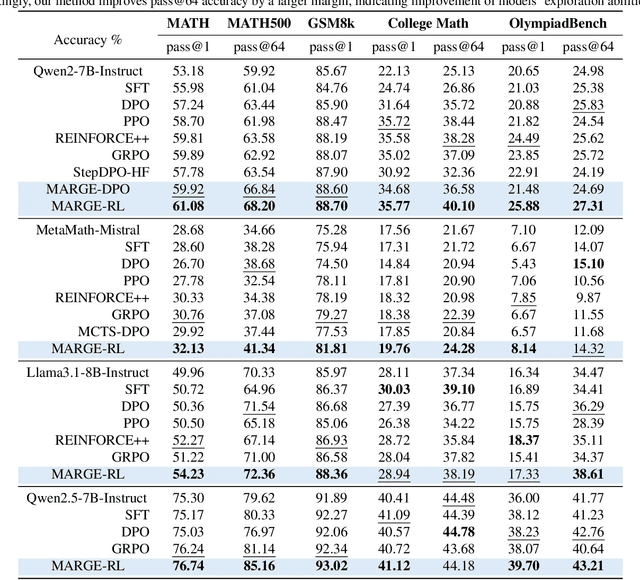
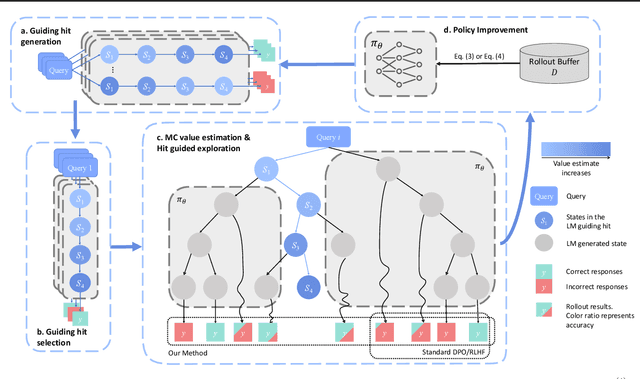
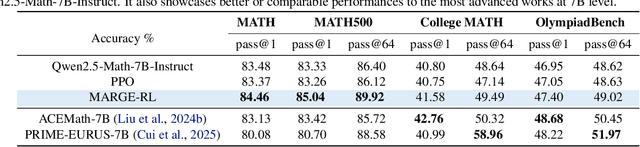
Large Language Models (LLMs) exhibit strong potential in mathematical reasoning, yet their effectiveness is often limited by a shortage of high-quality queries. This limitation necessitates scaling up computational responses through self-generated data, yet current methods struggle due to spurious correlated data caused by ineffective exploration across all reasoning stages. To address such challenge, we introduce \textbf{MARGE}: Improving \textbf{Ma}th \textbf{R}easoning with \textbf{G}uided \textbf{E}xploration, a novel method to address this issue and enhance mathematical reasoning through hit-guided exploration. MARGE systematically explores intermediate reasoning states derived from self-generated solutions, enabling adequate exploration and improved credit assignment throughout the reasoning process. Through extensive experiments across multiple backbone models and benchmarks, we demonstrate that MARGE significantly improves reasoning capabilities without requiring external annotations or training additional value models. Notably, MARGE improves both single-shot accuracy and exploration diversity, mitigating a common trade-off in alignment methods. These results demonstrate MARGE's effectiveness in enhancing mathematical reasoning capabilities and unlocking the potential of scaling self-generated training data. Our code and models are available at \href{https://github.com/georgao35/MARGE}{this link}.
Whleaper: A 10-DOF Flexible Bipedal Wheeled Robot
Apr 30, 2025



Wheel-legged robots combine the advantages of both wheeled robots and legged robots, offering versatile locomotion capabilities with excellent stability on challenging terrains and high efficiency on flat surfaces. However, existing wheel-legged robots typically have limited hip joint mobility compared to humans, while hip joint plays a crucial role in locomotion. In this paper, we introduce Whleaper, a novel 10-degree-of-freedom (DOF) bipedal wheeled robot, with 3 DOFs at the hip of each leg. Its humanoid joint design enables adaptable motion in complex scenarios, ensuring stability and flexibility. This paper introduces the details of Whleaper, with a focus on innovative mechanical design, control algorithms and system implementation. Firstly, stability stems from the increased DOFs at the hip, which expand the range of possible postures and improve the robot's foot-ground contact. Secondly, the extra DOFs also augment its mobility. During walking or sliding, more complex movements can be adopted to execute obstacle avoidance tasks. Thirdly, we utilize two control algorithms to implement multimodal motion for walking and sliding. By controlling specific DOFs of the robot, we conducted a series of simulations and practical experiments, demonstrating that a high-DOF hip joint design can effectively enhance the stability and flexibility of wheel-legged robots. Whleaper shows its capability to perform actions such as squatting, obstacle avoidance sliding, and rapid turning in real-world scenarios.
UP-VLA: A Unified Understanding and Prediction Model for Embodied Agent
Jan 31, 2025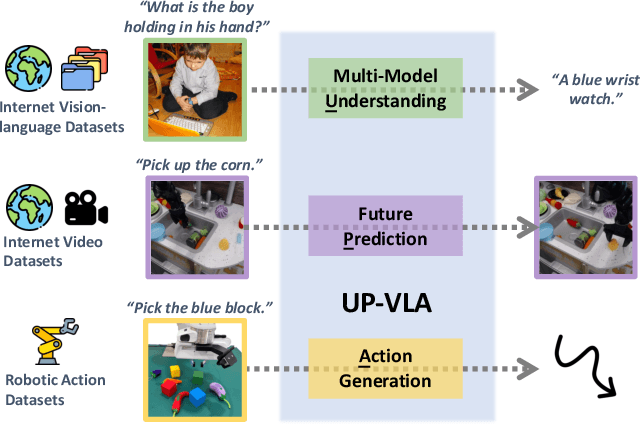
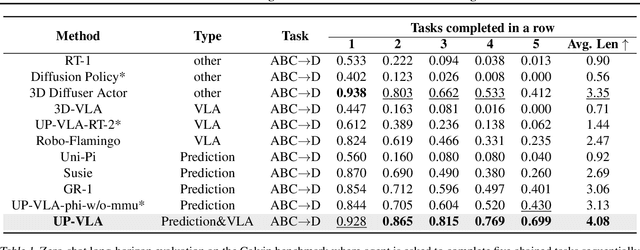
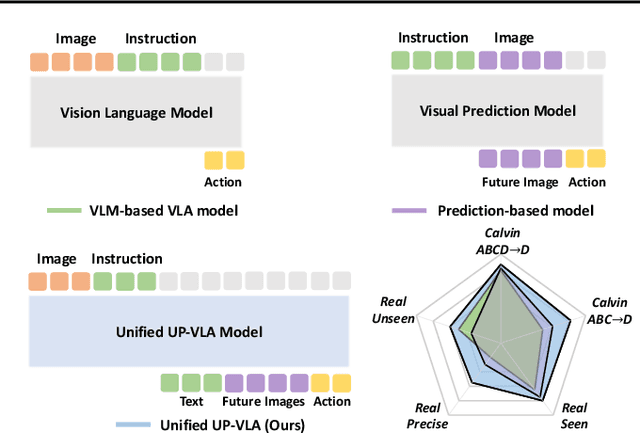
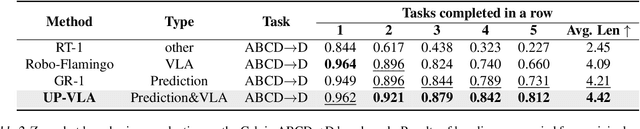
Recent advancements in Vision-Language-Action (VLA) models have leveraged pre-trained Vision-Language Models (VLMs) to improve the generalization capabilities. VLMs, typically pre-trained on vision-language understanding tasks, provide rich semantic knowledge and reasoning abilities. However, prior research has shown that VLMs often focus on high-level semantic content and neglect low-level features, limiting their ability to capture detailed spatial information and understand physical dynamics. These aspects, which are crucial for embodied control tasks, remain underexplored in existing pre-training paradigms. In this paper, we investigate the training paradigm for VLAs, and introduce \textbf{UP-VLA}, a \textbf{U}nified VLA model training with both multi-modal \textbf{U}nderstanding and future \textbf{P}rediction objectives, enhancing both high-level semantic comprehension and low-level spatial understanding. Experimental results show that UP-VLA achieves a 33% improvement on the Calvin ABC-D benchmark compared to the previous state-of-the-art method. Additionally, UP-VLA demonstrates improved success rates in real-world manipulation tasks, particularly those requiring precise spatial information.
Improving Vision-Language-Action Model with Online Reinforcement Learning
Jan 28, 2025
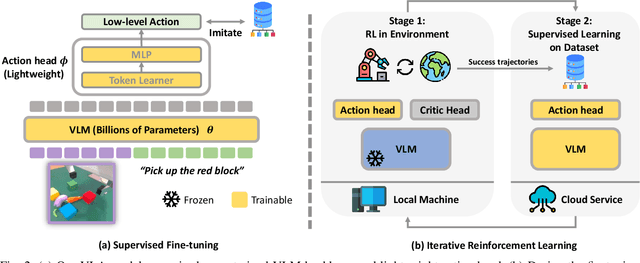

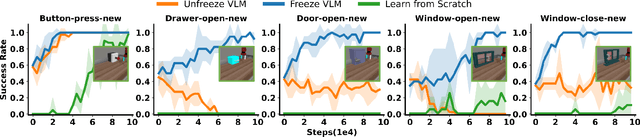
Recent studies have successfully integrated large vision-language models (VLMs) into low-level robotic control by supervised fine-tuning (SFT) with expert robotic datasets, resulting in what we term vision-language-action (VLA) models. Although the VLA models are powerful, how to improve these large models during interaction with environments remains an open question. In this paper, we explore how to further improve these VLA models via Reinforcement Learning (RL), a commonly used fine-tuning technique for large models. However, we find that directly applying online RL to large VLA models presents significant challenges, including training instability that severely impacts the performance of large models, and computing burdens that exceed the capabilities of most local machines. To address these challenges, we propose iRe-VLA framework, which iterates between Reinforcement Learning and Supervised Learning to effectively improve VLA models, leveraging the exploratory benefits of RL while maintaining the stability of supervised learning. Experiments in two simulated benchmarks and a real-world manipulation suite validate the effectiveness of our method.
AIF-SFDA: Autonomous Information Filter-driven Source-Free Domain Adaptation for Medical Image Segmentation
Jan 06, 2025



Decoupling domain-variant information (DVI) from domain-invariant information (DII) serves as a prominent strategy for mitigating domain shifts in the practical implementation of deep learning algorithms. However, in medical settings, concerns surrounding data collection and privacy often restrict access to both training and test data, hindering the empirical decoupling of information by existing methods. To tackle this issue, we propose an Autonomous Information Filter-driven Source-free Domain Adaptation (AIF-SFDA) algorithm, which leverages a frequency-based learnable information filter to autonomously decouple DVI and DII. Information Bottleneck (IB) and Self-supervision (SS) are incorporated to optimize the learnable frequency filter. The IB governs the information flow within the filter to diminish redundant DVI, while SS preserves DII in alignment with the specific task and image modality. Thus, the autonomous information filter can overcome domain shifts relying solely on target data. A series of experiments covering various medical image modalities and segmentation tasks were conducted to demonstrate the benefits of AIF-SFDA through comparisons with leading algorithms and ablation studies. The code is available at https://github.com/JingHuaMan/AIF-SFDA.
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Dec 19, 2024



Recent advancements in robotics have focused on developing generalist policies capable of performing multiple tasks. Typically, these policies utilize pre-trained vision encoders to capture crucial information from current observations. However, previous vision encoders, which trained on two-image contrastive learning or single-image reconstruction, can not perfectly capture the sequential information essential for embodied tasks. Recently, video diffusion models (VDMs) have demonstrated the capability to accurately predict future image sequences, exhibiting a good understanding of physical dynamics. Motivated by the strong visual prediction capabilities of VDMs, we hypothesize that they inherently possess visual representations that reflect the evolution of the physical world, which we term predictive visual representations. Building on this hypothesis, we propose the Video Prediction Policy (VPP), a generalist robotic policy conditioned on the predictive visual representations from VDMs. To further enhance these representations, we incorporate diverse human or robotic manipulation datasets, employing unified video-generation training objectives. VPP consistently outperforms existing methods across two simulated and two real-world benchmarks. Notably, it achieves a 28.1\% relative improvement in the Calvin ABC-D benchmark compared to the previous state-of-the-art and delivers a 28.8\% increase in success rates for complex real-world dexterous manipulation tasks.
Prediction with Action: Visual Policy Learning via Joint Denoising Process
Nov 27, 2024



Diffusion models have demonstrated remarkable capabilities in image generation tasks, including image editing and video creation, representing a good understanding of the physical world. On the other line, diffusion models have also shown promise in robotic control tasks by denoising actions, known as diffusion policy. Although the diffusion generative model and diffusion policy exhibit distinct capabilities--image prediction and robotic action, respectively--they technically follow a similar denoising process. In robotic tasks, the ability to predict future images and generate actions is highly correlated since they share the same underlying dynamics of the physical world. Building on this insight, we introduce PAD, a novel visual policy learning framework that unifies image Prediction and robot Action within a joint Denoising process. Specifically, PAD utilizes Diffusion Transformers (DiT) to seamlessly integrate images and robot states, enabling the simultaneous prediction of future images and robot actions. Additionally, PAD supports co-training on both robotic demonstrations and large-scale video datasets and can be easily extended to other robotic modalities, such as depth images. PAD outperforms previous methods, achieving a significant 26.3% relative improvement on the full Metaworld benchmark, by utilizing a single text-conditioned visual policy within a data-efficient imitation learning setting. Furthermore, PAD demonstrates superior generalization to unseen tasks in real-world robot manipulation settings with 28.0% success rate increase compared to the strongest baseline. Project page at https://sites.google.com/view/pad-paper