 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Learning of Large Language Model based Agents: A Roadmap
Jan 13, 2025Lifelong learning, also known as continual or incremental learning, is a crucial component for advancing Artificial General Intelligence (AGI) by enabling systems to continuously adapt in dynamic environments. While large language models (LLMs) have demonstrated impressive capabilities in natural language processing, existing LLM agents are typically designed for static systems and lack the ability to adapt over time in response to new challenges. This survey is the first to systematically summarize the potential techniques for incorporating lifelong learning into LLM-based agents. We categorize the core components of these agents into three modules: the perception module for multimodal input integration, the memory module for storing and retrieving evolving knowledge, and the action module for grounded interactions with the dynamic environment. We highlight how these pillars collectively enable continuous adaptation, mitigate catastrophic forgetting, and improve long-term performance. This survey provides a roadmap for researchers and practitioners working to develop lifelong learning capabilities in LLM agents, offering insights into emerging trends, evaluation metrics, and application scenarios. Relevant literature and resources are available at \href{this url}{https://github.com/qianlima-lab/awesome-lifelong-llm-agent}.
Advancing Humanoid Locomotion: Mastering Challenging Terrains with Denoising World Model Learning
Aug 26, 2024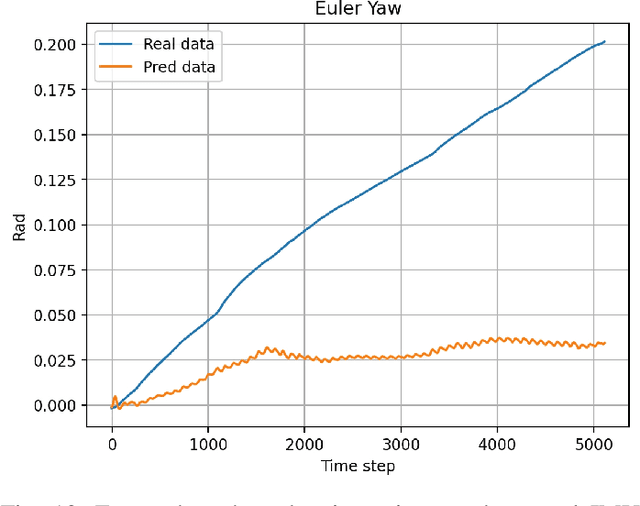
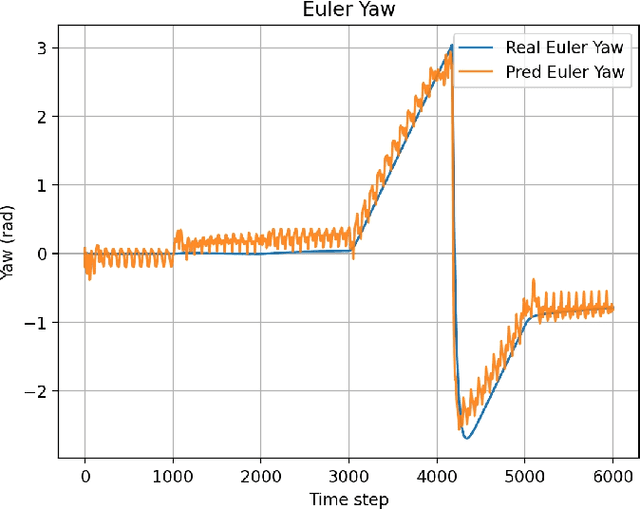
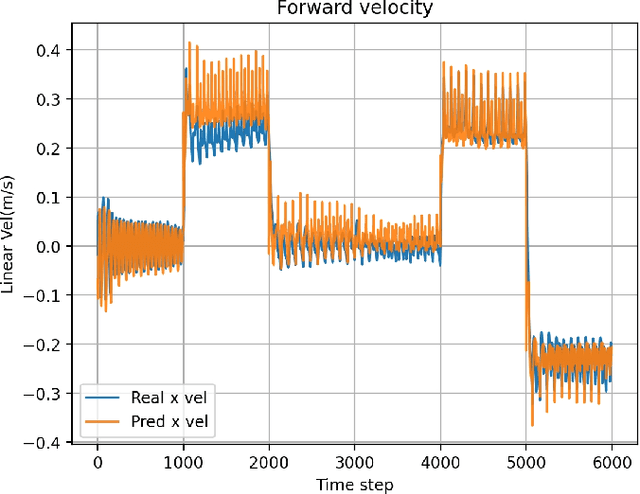
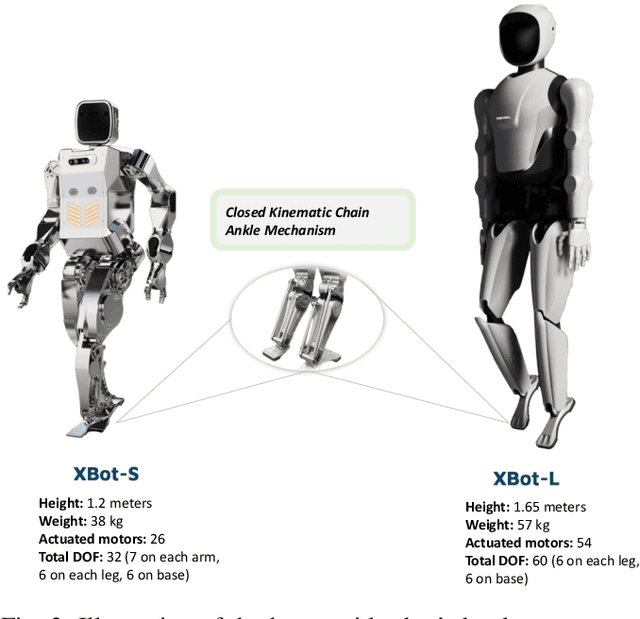
Humanoid robots, with their human-like skeletal structure, are especially suited for tasks in human-centric environments. However, this structure is accompanied by additional challenges in locomotion controller design, especially in complex real-world environments. As a result, existing humanoid robots are limited to relatively simple terrains, either with model-based control or model-free reinforcement learning. In this work, we introduce Denoising World Model Learning (DWL), an end-to-end reinforcement learning framework for humanoid locomotion control, which demonstrates the world's first humanoid robot to master real-world challenging terrains such as snowy and inclined land in the wild, up and down stairs, and extremely uneven terrains. All scenarios run the same learned neural network with zero-shot sim-to-real transfer, indicating the superior robustness and generalization capability of the proposed method.
Towards Lifelong Learning of Large Language Models: A Survey
Jun 10, 2024As the applications of large language models (LLMs) expand across diverse fields, the ability of these models to adapt to ongoing changes in data, tasks, and user preferences becomes crucial. Traditional training methods, relying on static datasets, are increasingly inadequate for coping with the dynamic nature of real-world information. Lifelong learning, also known as continual or incremental learning, addresses this challenge by enabling LLMs to learn continuously and adaptively over their operational lifetime, integrating new knowledge while retaining previously learned information and preventing catastrophic forgetting. This survey delves into the sophisticated landscape of lifelong learning, categorizing strategies into two primary groups: Internal Knowledge and External Knowledge. Internal Knowledge includes continual pretraining and continual finetuning, each enhancing the adaptability of LLMs in various scenarios. External Knowledge encompasses retrieval-based and tool-based lifelong learning, leveraging external data sources and computational tools to extend the model's capabilities without modifying core parameters. The key contributions of our survey are: (1) Introducing a novel taxonomy categorizing the extensive literature of lifelong learning into 12 scenarios; (2) Identifying common techniques across all lifelong learning scenarios and classifying existing literature into various technique groups within each scenario; (3) Highlighting emerging techniques such as model expansion and data selection, which were less explored in the pre-LLM era. Through a detailed examination of these groups and their respective categories, this survey aims to enhance the adaptability, reliability, and overall performance of LLMs in real-world applications.
Reinforcement learning with Demonstrations from Mismatched Task under Sparse Reward
Dec 03, 2022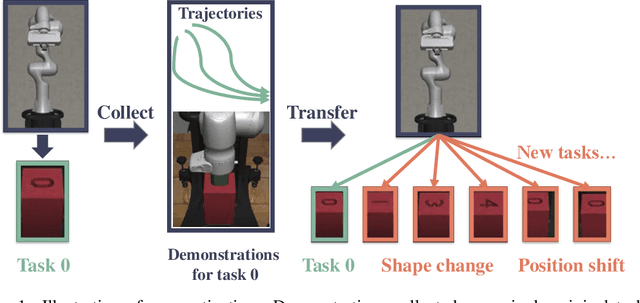
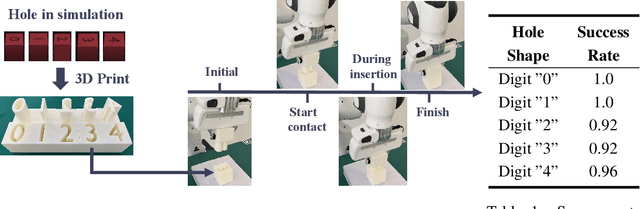
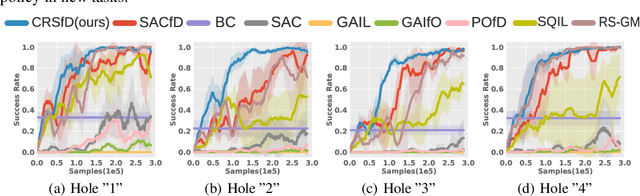
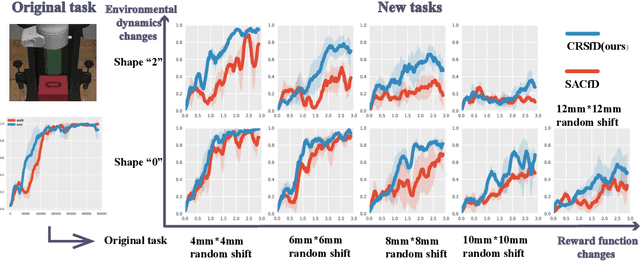
Reinforcement learning often suffer from the sparse reward issue in real-world robotics problems. Learning from demonstration (LfD) is an effective way to eliminate this problem, which leverages collected expert data to aid online learning. Prior works often assume that the learning agent and the expert aim to accomplish the same task, which requires collecting new data for every new task. In this paper, we consider the case where the target task is mismatched from but similar with that of the expert. Such setting can be challenging and we found existing LfD methods can not effectively guide learning in mismatched new tasks with sparse rewards. We propose conservative reward shaping from demonstration (CRSfD), which shapes the sparse rewards using estimated expert value function. To accelerate learning processes, CRSfD guides the agent to conservatively explore around demonstrations. Experimental results of robot manipulation tasks show that our approach outperforms baseline LfD methods when transferring demonstrations collected in a single task to other different but similar tasks.