 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
Feb 05, 2026As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7\% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.
A Unified Shape-Aware Foundation Model for Time Series Classification
Jan 10, 2026Foundation models pre-trained on large-scale source datasets are reshaping the traditional training paradigm for time series classification. However, existing time series foundation models primarily focus on forecasting tasks and often overlook classification-specific challenges, such as modeling interpretable shapelets that capture class-discriminative temporal features. To bridge this gap, we propose UniShape, a unified shape-aware foundation model designed for time series classification. UniShape incorporates a shape-aware adapter that adaptively aggregates multiscale discriminative subsequences (shapes) into class tokens, effectively selecting the most relevant subsequence scales to enhance model interpretability. Meanwhile, a prototype-based pretraining module is introduced to jointly learn instance- and shape-level representations, enabling the capture of transferable shape patterns. Pre-trained on a large-scale multi-domain time series dataset comprising 1.89 million samples, UniShape exhibits superior generalization across diverse target domains. Experiments on 128 UCR datasets and 30 additional time series datasets demonstrate that UniShape achieves state-of-the-art classification performance, with interpretability and ablation analyses further validating its effectiveness.
T2I-Based Physical-World Appearance Attack against Traffic Sign Recognition Systems in Autonomous Driving
Nov 17, 2025Traffic Sign Recognition (TSR) systems play a critical role in Autonomous Driving (AD) systems, enabling real-time detection of road signs, such as STOP and speed limit signs. While these systems are increasingly integrated into commercial vehicles, recent research has exposed their vulnerability to physical-world adversarial appearance attacks. In such attacks, carefully crafted visual patterns are misinterpreted by TSR models as legitimate traffic signs, while remaining inconspicuous or benign to human observers. However, existing adversarial appearance attacks suffer from notable limitations. Pixel-level perturbation-based methods often lack stealthiness and tend to overfit to specific surrogate models, resulting in poor transferability to real-world TSR systems. On the other hand, text-to-image (T2I) diffusion model-based approaches demonstrate limited effectiveness and poor generalization to out-of-distribution sign types. In this paper, we present DiffSign, a novel T2I-based appearance attack framework designed to generate physically robust, highly effective, transferable, practical, and stealthy appearance attacks against TSR systems. To overcome the limitations of prior approaches, we propose a carefully designed attack pipeline that integrates CLIP-based loss and masked prompts to improve attack focus and controllability. We also propose two novel style customization methods to guide visual appearance and improve out-of-domain traffic sign attack generalization and attack stealthiness. We conduct extensive evaluations of DiffSign under varied real-world conditions, including different distances, angles, light conditions, and sign categories. Our method achieves an average physical-world attack success rate of 83.3%, leveraging DiffSign's high effectiveness in attack transferability.
Revisiting Adversarial Patch Defenses on Object Detectors: Unified Evaluation, Large-Scale Dataset, and New Insights
Aug 01, 2025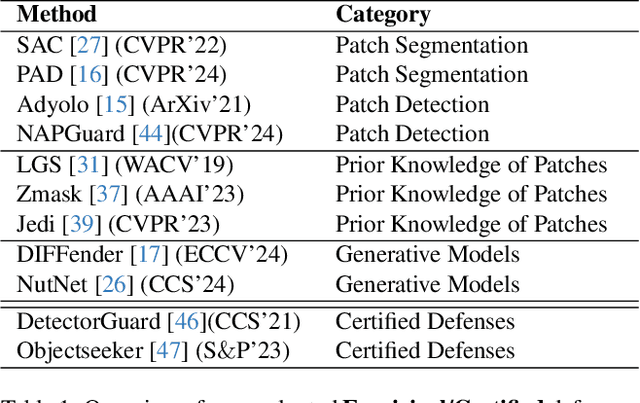

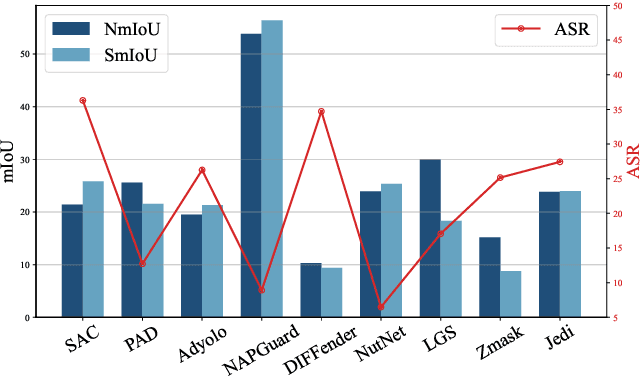
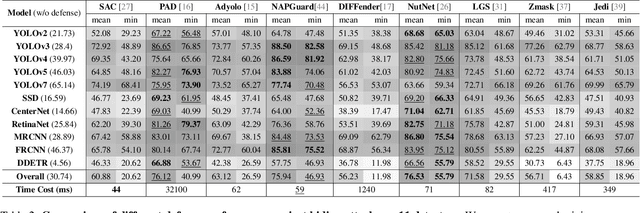
Developing reliable defenses against patch attacks on object detectors has attracted increasing interest. However, we identify that existing defense evaluations lack a unified and comprehensive framework, resulting in inconsistent and incomplete assessments of current methods. To address this issue, we revisit 11 representative defenses and present the first patch defense benchmark, involving 2 attack goals, 13 patch attacks, 11 object detectors, and 4 diverse metrics. This leads to the large-scale adversarial patch dataset with 94 types of patches and 94,000 images. Our comprehensive analyses reveal new insights: (1) The difficulty in defending against naturalistic patches lies in the data distribution, rather than the commonly believed high frequencies. Our new dataset with diverse patch distributions can be used to improve existing defenses by 15.09% AP@0.5. (2) The average precision of the attacked object, rather than the commonly pursued patch detection accuracy, shows high consistency with defense performance. (3) Adaptive attacks can substantially bypass existing defenses, and defenses with complex/stochastic models or universal patch properties are relatively robust. We hope that our analyses will serve as guidance on properly evaluating patch attacks/defenses and advancing their design. Code and dataset are available at https://github.com/Gandolfczjh/APDE, where we will keep integrating new attacks/defenses.
HyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting
May 23, 2025Irregular multivariate time series (IMTS) are characterized by irregular time intervals within variables and unaligned observations across variables, posing challenges in learning temporal and variable dependencies. Many existing IMTS models either require padded samples to learn separately from temporal and variable dimensions, or represent original samples via bipartite graphs or sets. However, the former approaches often need to handle extra padding values affecting efficiency and disrupting original sampling patterns, while the latter ones have limitations in capturing dependencies among unaligned observations. To represent and learn both dependencies from original observations in a unified form, we propose HyperIMTS, a Hypergraph neural network for Irregular Multivariate Time Series forecasting. Observed values are converted as nodes in the hypergraph, interconnected by temporal and variable hyperedges to enable message passing among all observations. Through irregularity-aware message passing, HyperIMTS captures variable dependencies in a time-adaptive way to achieve accurate forecasting. Experiments demonstrate HyperIMTS's competitive performance among state-of-the-art models in IMTS forecasting with low computational cost.
LifelongAgentBench: Evaluating LLM Agents as Lifelong Learners
May 17, 2025Lifelong learning is essential for intelligent agents operating in dynamic environments. Current large language model (LLM)-based agents, however, remain stateless and unable to accumulate or transfer knowledge over time. Existing benchmarks treat agents as static systems and fail to evaluate lifelong learning capabilities. We present LifelongAgentBench, the first unified benchmark designed to systematically assess the lifelong learning ability of LLM agents. It provides skill-grounded, interdependent tasks across three interactive environments, Database, Operating System, and Knowledge Graph, with automatic label verification, reproducibility, and modular extensibility. Extensive experiments reveal that conventional experience replay has limited effectiveness for LLM agents due to irrelevant information and context length constraints. We further introduce a group self-consistency mechanism that significantly improves lifelong learning performance. We hope LifelongAgentBench will advance the development of adaptive, memory-capable LLM agents.
From System 1 to System 2: A Survey of Reasoning Large Language Models
Feb 25, 2025Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI's o1/o3 and DeepSeek's R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
Neural-Symbolic Message Passing with Dynamic Pruning
Jan 24, 2025



Complex Query Answering (CQA) over incomplete Knowledge Graphs (KGs) is a challenging task. Recently, a line of message-passing-based research has been proposed to solve CQA. However, they perform unsatisfactorily on negative queries and fail to address the noisy messages between variable nodes in the query graph. Moreover, they offer little interpretability and require complex query data and resource-intensive training. In this paper, we propose a Neural-Symbolic Message Passing (NSMP) framework based on pre-trained neural link predictors. By introducing symbolic reasoning and fuzzy logic, NSMP can generalize to arbitrary existential first order logic queries without requiring training while providing interpretable answers. Furthermore, we introduce a dynamic pruning strategy to filter out noisy messages between variable nodes. Experimental results show that NSMP achieves a strong performance. Additionally, through complexity analysis and empirical verification, we demonstrate the superiority of NSMP in inference time over the current state-of-the-art neural-symbolic method. Compared to this approach, NSMP demonstrates faster inference times across all query types on benchmark datasets, with speedup ranging from 2$\times$ to over 150$\times$.
ListConRanker: A Contrastive Text Reranker with Listwise Encoding
Jan 13, 2025



Reranker models aim to re-rank the passages based on the semantics similarity between the given query and passages, which have recently received more attention due to the wide application of the Retrieval-Augmented Generation. Most previous methods apply pointwise encoding, meaning that it can only encode the context of the query for each passage input into the model. However, for the reranker model, given a query, the comparison results between passages are even more important, which is called listwise encoding. Besides, previous models are trained using the cross-entropy loss function, which leads to issues of unsmooth gradient changes during training and low training efficiency. To address these issues, we propose a novel Listwise-encoded Contrastive text reRanker (ListConRanker). It can help the passage to be compared with other passages during the encoding process, and enhance the contrastive information between positive examples and between positive and negative examples. At the same time, we use the circle loss to train the model to increase the flexibility of gradients and solve the problem of training efficiency. Experimental results show that ListConRanker achieves state-of-the-art performance on the reranking benchmark of Chinese Massive Text Embedding Benchmark, including the cMedQA1.0, cMedQA2.0, MMarcoReranking, and T2Reranking datasets.
Lifelong Learning of Large Language Model based Agents: A Roadmap
Jan 13, 2025Lifelong learning, also known as continual or incremental learning, is a crucial component for advancing Artificial General Intelligence (AGI) by enabling systems to continuously adapt in dynamic environments. While large language models (LLMs) have demonstrated impressive capabilities in natural language processing, existing LLM agents are typically designed for static systems and lack the ability to adapt over time in response to new challenges. This survey is the first to systematically summarize the potential techniques for incorporating lifelong learning into LLM-based agents. We categorize the core components of these agents into three modules: the perception module for multimodal input integration, the memory module for storing and retrieving evolving knowledge, and the action module for grounded interactions with the dynamic environment. We highlight how these pillars collectively enable continuous adaptation, mitigate catastrophic forgetting, and improve long-term performance. This survey provides a roadmap for researchers and practitioners working to develop lifelong learning capabilities in LLM agents, offering insights into emerging trends, evaluation metrics, and application scenarios. Relevant literature and resources are available at \href{this url}{https://github.com/qianlima-lab/awesome-lifelong-llm-agent}.