 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Decoupled Anonymization for Visual Evidence in Multi-modal Retrieval-Augmented Generation
Apr 26, 2026Multi-modal retrieval-augmented generation (MRAG) systems retrieve visual evidence from large image corpora to ground the responses of large multi-modal models, yet the retrieved images frequently contain human faces whose identities constitute sensitive personal information. Existing anonymization techniques that destroy the non-identity visual cues that downstream reasoning depends on or fail to provide principled privacy guarantees. We propose Identity-Decoupled MRAG, a framework that interposes a generative anonymization module between retrieval and generation. Our approach consists of three components: (i)a disentangled variational encoder that factorizes each face into an identity code and a spatially-structured attribute code, regularized by a mutual-information penalty and a gradient-based independence term; (ii)a manifold-aware rejection sampler that replaces the identity code with a synthetic one guaranteed to be both distinct from the original and realistic; and (iii)a conditional latent diffusion generator that synthesizes the anonymized face from the replacement identity and the preserved attributes, distilled into a latent consistency model for low-latency deployment. Privacy is enforced through a multi-oracle ensemble of face recognition models with a hinge-based loss that halts optimization once identity similarity drops below the impostor-regime threshold.
CircuitSynth: Reliable Synthetic Data Generation
Apr 11, 2026The generation of high-fidelity synthetic data is a cornerstone of modern machine learning, yet Large Language Models (LLMs) frequently suffer from hallucinations, logical inconsistencies, and mode collapse when tasked with structured generation. Existing approaches, such as prompting or retrieval-augmented generation, lack the mechanisms to balance linguistic expressivity with formal guarantees regarding validity and coverage. To address this, we propose CircuitSynth, a novel neuro-symbolic framework that decouples semantic reasoning from surface realization. By distilling the reasoning capabilities of a Teacher LLM into a Probabilistic Sentential Decision Diagram (PSDD), CircuitSynth creates a tractable semantic prior that structurally enforces hard logical constraints. Furthermore, we introduce a convex optimization mechanism to rigorously satisfy soft distributional goals. Empirical evaluations across diverse benchmarks demonstrate that CircuitSynth achieves 100% Schema Validity even in complex logic puzzles where unconstrained baselines fail (12.4%) while significantly outperforming state-of-the-art methods in rare-combination coverage.
Visual Set Program Synthesizer
Mar 16, 2026A user pointing their phone at a supermarket shelf and asking "Which soda has the least sugar?" poses a difficult challenge for current visual Al assistants. Such queries require not only object recognition, but explicit set-based reasoning such as filtering, comparison, and aggregation. Standard endto-end MLLMs often fail at these tasks because they lack an explicit mechanism for compositional logic. We propose treating visual reasoning as Visual Program Synthesis, where the model first generates a symbolic program that is executed by a separate engine grounded in visual scenes. We also introduce Set-VQA, a new benchmark designed specifically for evaluating set-based visual reasoning. Experiments show that our approach significantly outperforms state-of-the-art baselines on complex reasoning tasks, producing more systematic and transparent behavior while substantially improving answer accuracy. These results demonstrate that program-driven reasoning provides a principled alternative to black-box visual-language inference.
* 10 pages, IEEE International Conference on Multimedia and Expo 2026
Provable Defense Framework for LLM Jailbreaks via Noise-Augumented Alignment
Feb 02, 2026Large Language Models (LLMs) remain vulnerable to adaptive jailbreaks that easily bypass empirical defenses like GCG. We propose a framework for certifiable robustness that shifts safety guarantees from single-pass inference to the statistical stability of an ensemble. We introduce Certified Semantic Smoothing (CSS) via Stratified Randomized Ablation, a technique that partitions inputs into immutable structural prompts and mutable payloads to derive rigorous lo norm guarantees using the Hypergeometric distribution. To resolve performance degradation on sparse contexts, we employ Noise-Augmented Alignment Tuning (NAAT), which transforms the base model into a semantic denoiser. Extensive experiments on Llama-3 show that our method reduces the Attack Success Rate of gradient-based attacks from 84.2% to 1.2% while maintaining 94.1% benign utility, significantly outperforming character-level baselines which degrade utility to 74.3%. This framework provides a deterministic certificate of safety, ensuring that a model remains robust against all adversarial variants within a provable radius.
An LLM-LVLM Driven Agent for Iterative and Fine-Grained Image Editing
Aug 24, 2025



Despite the remarkable capabilities of text-to-image (T2I) generation models, real-world applications often demand fine-grained, iterative image editing that existing methods struggle to provide. Key challenges include granular instruction understanding, robust context preservation during modifications, and the lack of intelligent feedback mechanisms for iterative refinement. This paper introduces RefineEdit-Agent, a novel, training-free intelligent agent framework designed to address these limitations by enabling complex, iterative, and context-aware image editing. RefineEdit-Agent leverages the powerful planning capabilities of Large Language Models (LLMs) and the advanced visual understanding and evaluation prowess of Vision-Language Large Models (LVLMs) within a closed-loop system. Our framework comprises an LVLM-driven instruction parser and scene understanding module, a multi-level LLM-driven editing planner for goal decomposition, tool selection, and sequence generation, an iterative image editing module, and a crucial LVLM-driven feedback and evaluation loop. To rigorously evaluate RefineEdit-Agent, we propose LongBench-T2I-Edit, a new benchmark featuring 500 initial images with complex, multi-turn editing instructions across nine visual dimensions. Extensive experiments demonstrate that RefineEdit-Agent significantly outperforms state-of-the-art baselines, achieving an average score of 3.67 on LongBench-T2I-Edit, compared to 2.29 for Direct Re-Prompting, 2.91 for InstructPix2Pix, 3.16 for GLIGEN-based Edit, and 3.39 for ControlNet-XL. Ablation studies, human evaluations, and analyses of iterative refinement, backbone choices, tool usage, and robustness to instruction complexity further validate the efficacy of our agentic design in delivering superior edit fidelity and context preservation.
Expert-Guided Diffusion Planner for Auto-bidding
Aug 12, 2025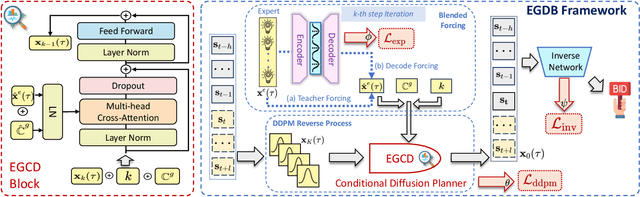
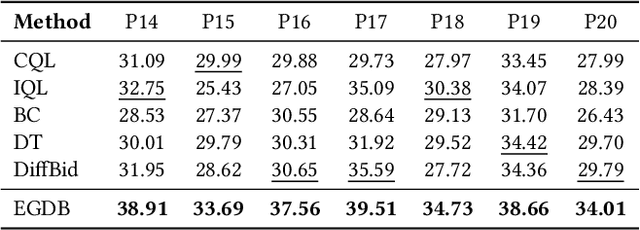
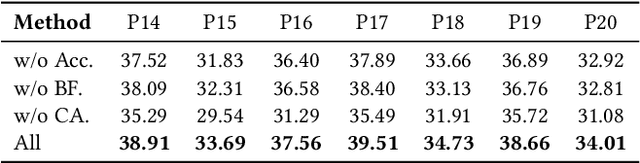
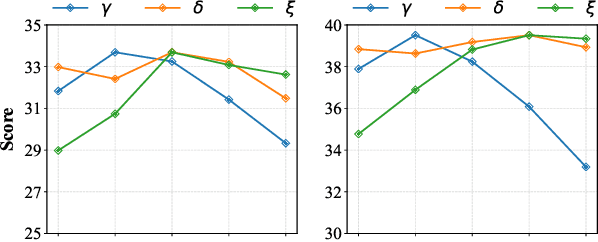
Auto-bidding is extensively applied in advertising systems, serving a multitude of advertisers. Generative bidding is gradually gaining traction due to its robust planning capabilities and generalizability. In contrast to traditional reinforcement learning-based bidding, generative bidding does not rely on the Markov Decision Process (MDP) exhibiting superior planning capabilities in long-horizon scenarios. Conditional diffusion modeling approaches have demonstrated significant potential in the realm of auto-bidding. However, relying solely on return as the optimality condition is weak to guarantee the generation of genuinely optimal decision sequences, lacking personalized structural information. Moreover, diffusion models' t-step autoregressive generation mechanism inherently carries timeliness risks. To address these issues, we propose a novel conditional diffusion modeling method based on expert trajectory guidance combined with a skip-step sampling strategy to enhance generation efficiency. We have validated the effectiveness of this approach through extensive offline experiments and achieved statistically significant results in online A/B testing, achieving an increase of 11.29% in conversion and a 12.35% in revenue compared with the baseline.
Revisiting Adversarial Patch Defenses on Object Detectors: Unified Evaluation, Large-Scale Dataset, and New Insights
Aug 01, 2025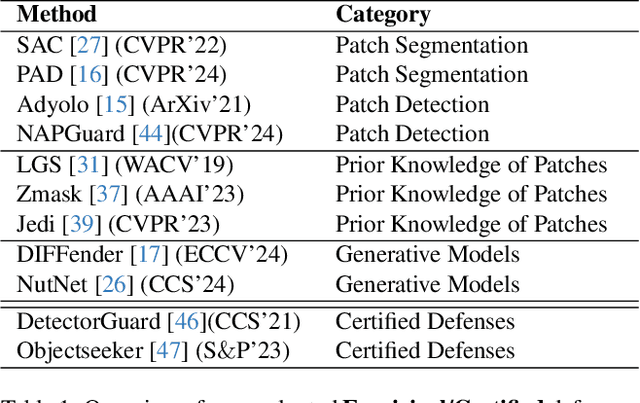

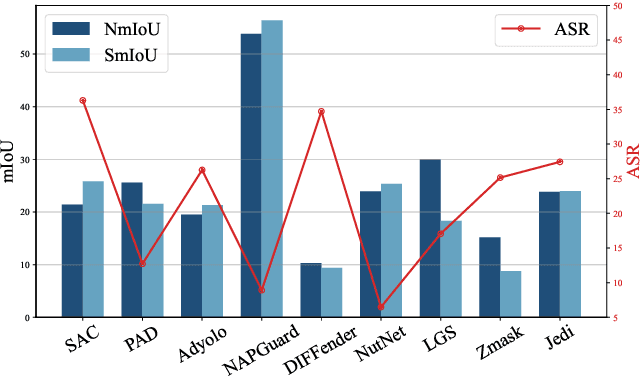
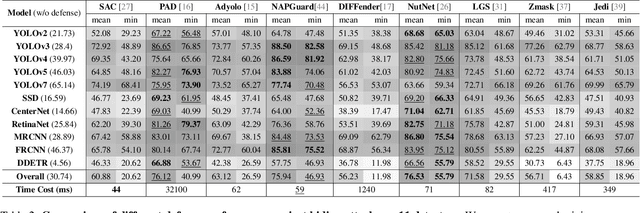
Developing reliable defenses against patch attacks on object detectors has attracted increasing interest. However, we identify that existing defense evaluations lack a unified and comprehensive framework, resulting in inconsistent and incomplete assessments of current methods. To address this issue, we revisit 11 representative defenses and present the first patch defense benchmark, involving 2 attack goals, 13 patch attacks, 11 object detectors, and 4 diverse metrics. This leads to the large-scale adversarial patch dataset with 94 types of patches and 94,000 images. Our comprehensive analyses reveal new insights: (1) The difficulty in defending against naturalistic patches lies in the data distribution, rather than the commonly believed high frequencies. Our new dataset with diverse patch distributions can be used to improve existing defenses by 15.09% AP@0.5. (2) The average precision of the attacked object, rather than the commonly pursued patch detection accuracy, shows high consistency with defense performance. (3) Adaptive attacks can substantially bypass existing defenses, and defenses with complex/stochastic models or universal patch properties are relatively robust. We hope that our analyses will serve as guidance on properly evaluating patch attacks/defenses and advancing their design. Code and dataset are available at https://github.com/Gandolfczjh/APDE, where we will keep integrating new attacks/defenses.
AIArena: A Blockchain-Based Decentralized AI Training Platform
Dec 19, 2024The rapid advancement of AI has underscored critical challenges in its development and implementation, largely due to centralized control by a few major corporations. This concentration of power intensifies biases within AI models, resulting from inadequate governance and oversight mechanisms. Additionally, it limits public involvement and heightens concerns about the integrity of model generation. Such monopolistic control over data and AI outputs threatens both innovation and fair data usage, as users inadvertently contribute data that primarily benefits these corporations. In this work, we propose AIArena, a blockchain-based decentralized AI training platform designed to democratize AI development and alignment through on-chain incentive mechanisms. AIArena fosters an open and collaborative environment where participants can contribute models and computing resources. Its on-chain consensus mechanism ensures fair rewards for participants based on their contributions. We instantiate and implement AIArena on the public Base blockchain Sepolia testnet, and the evaluation results demonstrate the feasibility of AIArena in real-world applications.
SoK: Decentralized AI (DeAI)
Nov 26, 2024The centralization of Artificial Intelligence (AI) poses significant challenges, including single points of failure, inherent biases, data privacy concerns, and scalability issues. These problems are especially prevalent in closed-source large language models (LLMs), where user data is collected and used without transparency. To mitigate these issues, blockchain-based decentralized AI (DeAI) has emerged as a promising solution. DeAI combines the strengths of both blockchain and AI technologies to enhance the transparency, security, decentralization, and trustworthiness of AI systems. However, a comprehensive understanding of state-of-the-art DeAI development, particularly for active industry solutions, is still lacking. In this work, we present a Systematization of Knowledge (SoK) for blockchain-based DeAI solutions. We propose a taxonomy to classify existing DeAI protocols based on the model lifecycle. Based on this taxonomy, we provide a structured way to clarify the landscape of DeAI protocols and identify their similarities and differences. We analyze the functionalities of blockchain in DeAI, investigating how blockchain features contribute to enhancing the security, transparency, and trustworthiness of AI processes, while also ensuring fair incentives for AI data and model contributors. In addition, we identify key insights and research gaps in developing DeAI protocols, highlighting several critical avenues for future research.
Multi-Continental Healthcare Modelling Using Blockchain-Enabled Federated Learning
Oct 23, 2024
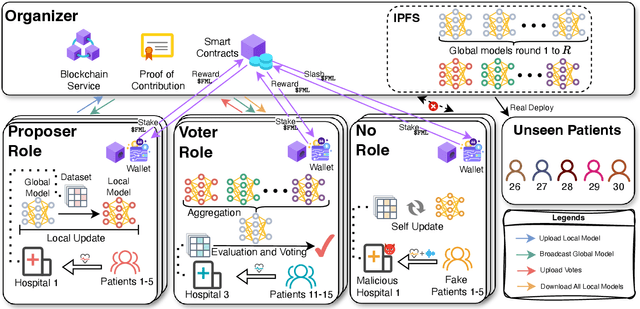
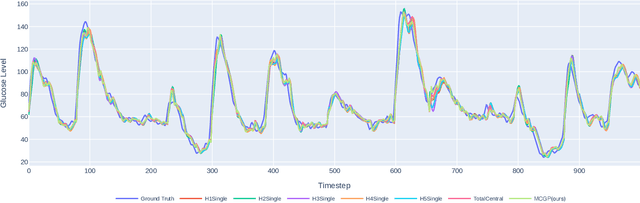
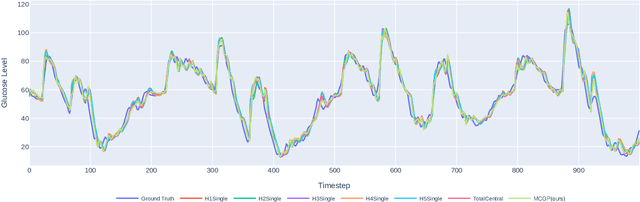
One of the biggest challenges of building artificial intelligence (AI) model in healthcare area is the data sharing. Since healthcare data is private, sensitive, and heterogeneous, collecting sufficient data for modelling is exhausted, costly, and sometimes impossible. In this paper, we propose a framework for global healthcare modelling using datasets from multi-continents (Europe, North America and Asia) while without sharing the local datasets, and choose glucose management as a study model to verify its effectiveness. Technically, blockchain-enabled federated learning is implemented with adaption to make it meet with the privacy and safety requirements of healthcare data, meanwhile rewards honest participation and penalize malicious activities using its on-chain incentive mechanism. Experimental results show that the proposed framework is effective, efficient, and privacy preserved. Its prediction accuracy is much better than the models trained from limited personal data and is similar to, and even slightly better than, the results from a centralized dataset. This work paves the way for international collaborations on healthcare projects, where additional data is crucial for reducing bias and providing benefits to humanity.