 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQL: An End-to-End Context-Aware Vector Quantization Attention for Ultra-Long User Behavior Modeling
Aug 23, 2025In large-scale recommender systems, ultra-long user behavior sequences encode rich signals of evolving interests. Extending sequence length generally improves accuracy, but directly modeling such sequences in production is infeasible due to latency and memory constraints. Existing solutions fall into two categories: (1) top-k retrieval, which truncates the sequence and may discard most attention mass when L >> k; and (2) encoder-based compression, which preserves coverage but often over-compresses and fails to incorporate key context such as temporal gaps or target-aware signals. Neither class achieves a good balance of low-loss compression, context awareness, and efficiency. We propose VQL, a context-aware Vector Quantization Attention framework for ultra-long behavior modeling, with three innovations. (1) Key-only quantization: only attention keys are quantized, while values remain intact; we prove that softmax normalization yields an error bound independent of sequence length, and a codebook loss directly supervises quantization quality. This also enables L-free inference via offline caches. (2) Multi-scale quantization: attention heads are partitioned into groups, each with its own small codebook, which reduces quantization error while keeping cache size fixed. (3) Efficient context injection: static features (e.g., item category, modality) are directly integrated, and relative position is modeled via a separable temporal kernel. All context is injected without enlarging the codebook, so cached representations remain query-independent. Experiments on three large-scale datasets (KuaiRand-1K, KuaiRec, TMALL) show that VQL consistently outperforms strong baselines, achieving higher accuracy while reducing inference latency, establishing a new state of the art in balancing accuracy and efficiency for ultra-long sequence recommendation.
Expert-Guided Diffusion Planner for Auto-bidding
Aug 12, 2025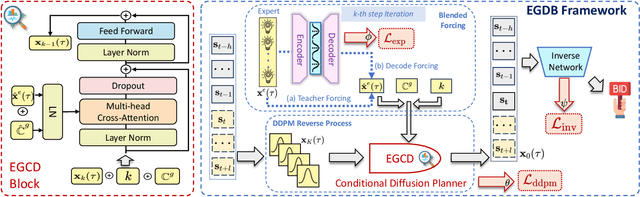
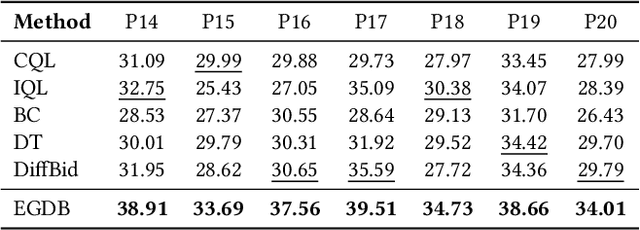
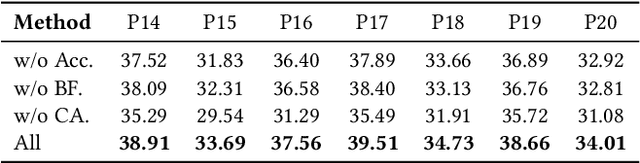
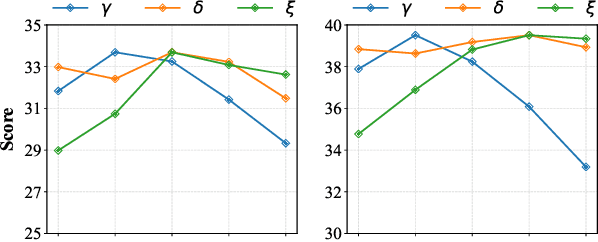
Auto-bidding is extensively applied in advertising systems, serving a multitude of advertisers. Generative bidding is gradually gaining traction due to its robust planning capabilities and generalizability. In contrast to traditional reinforcement learning-based bidding, generative bidding does not rely on the Markov Decision Process (MDP) exhibiting superior planning capabilities in long-horizon scenarios. Conditional diffusion modeling approaches have demonstrated significant potential in the realm of auto-bidding. However, relying solely on return as the optimality condition is weak to guarantee the generation of genuinely optimal decision sequences, lacking personalized structural information. Moreover, diffusion models' t-step autoregressive generation mechanism inherently carries timeliness risks. To address these issues, we propose a novel conditional diffusion modeling method based on expert trajectory guidance combined with a skip-step sampling strategy to enhance generation efficiency. We have validated the effectiveness of this approach through extensive offline experiments and achieved statistically significant results in online A/B testing, achieving an increase of 11.29% in conversion and a 12.35% in revenue compared with the baseline.
CHIME: A Compressive Framework for Holistic Interest Modeling
Apr 09, 2025Modeling holistic user interests is important for improving recommendation systems but is challenged by high computational cost and difficulty in handling diverse information with full behavior context. Existing search-based methods might lose critical signals during behavior selection. To overcome these limitations, we propose CHIME: A Compressive Framework for Holistic Interest Modeling. It uses adapted large language models to encode complete user behaviors with heterogeneous inputs. We introduce multi-granular contrastive learning objectives to capture both persistent and transient interest patterns and apply residual vector quantization to generate compact embeddings. CHIME demonstrates superior ranking performance across diverse datasets, establishing a robust solution for scalable holistic interest modeling in recommendation systems.
BBQRec: Behavior-Bind Quantization for Multi-Modal Sequential Recommendation
Apr 09, 2025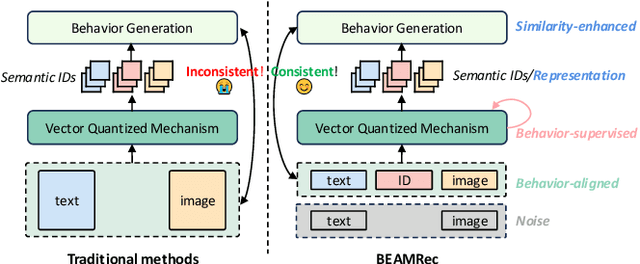
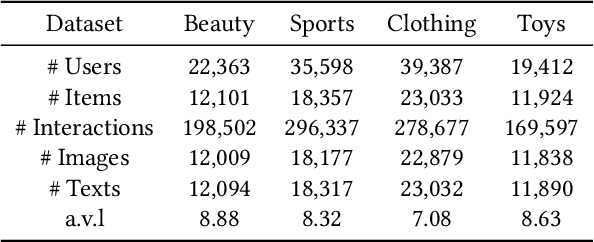
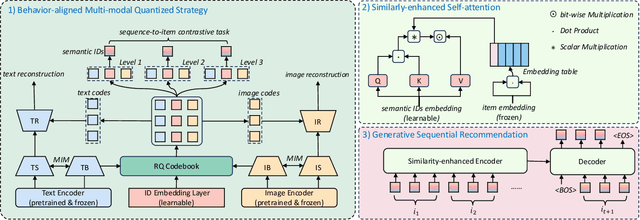
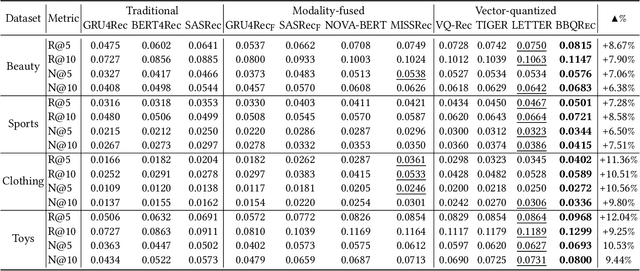
Multi-modal sequential recommendation systems leverage auxiliary signals (e.g., text, images) to alleviate data sparsity in user-item interactions. While recent methods exploit large language models to encode modalities into discrete semantic IDs for autoregressive prediction, we identify two critical limitations: (1) Existing approaches adopt fragmented quantization, where modalities are independently mapped to semantic spaces misaligned with behavioral objectives, and (2) Over-reliance on semantic IDs disrupts inter-modal semantic coherence, thereby weakening the expressive power of multi-modal representations for modeling diverse user preferences. To address these challenges, we propose a Behavior-Bind multi-modal Quantization for Sequential Recommendation (BBQRec for short) featuring dual-aligned quantization and semantics-aware sequence modeling. First, our behavior-semantic alignment module disentangles modality-agnostic behavioral patterns from noisy modality-specific features through contrastive codebook learning, ensuring semantic IDs are inherently tied to recommendation tasks. Second, we design a discretized similarity reweighting mechanism that dynamically adjusts self-attention scores using quantized semantic relationships, preserving multi-modal synergies while avoiding invasive modifications to the sequence modeling architecture. Extensive evaluations across four real-world benchmarks demonstrate BBQRec's superiority over the state-of-the-art baselines.
S-Diff: An Anisotropic Diffusion Model for Collaborative Filtering in Spectral Domain
Dec 31, 2024



Recovering user preferences from user-item interaction matrices is a key challenge in recommender systems. While diffusion models can sample and reconstruct preferences from latent distributions, they often fail to capture similar users' collective preferences effectively. Additionally, latent variables degrade into pure Gaussian noise during the forward process, lowering the signal-to-noise ratio, which in turn degrades performance. To address this, we propose S-Diff, inspired by graph-based collaborative filtering, better to utilize low-frequency components in the graph spectral domain. S-Diff maps user interaction vectors into the spectral domain and parameterizes diffusion noise to align with graph frequency. This anisotropic diffusion retains significant low-frequency components, preserving a high signal-to-noise ratio. S-Diff further employs a conditional denoising network to encode user interactions, recovering true preferences from noisy data. This method achieves strong results across multiple datasets.
CROLoss: Towards a Customizable Loss for Retrieval Models in Recommender Systems
Aug 05, 2022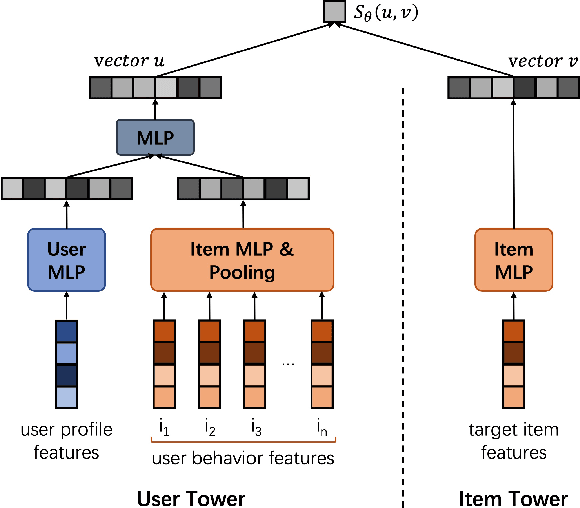
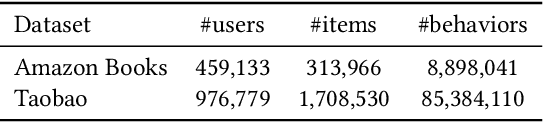
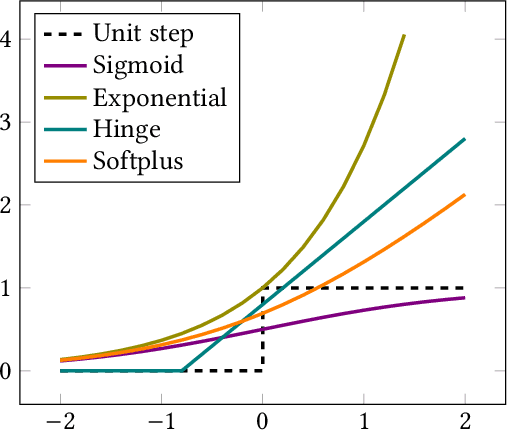
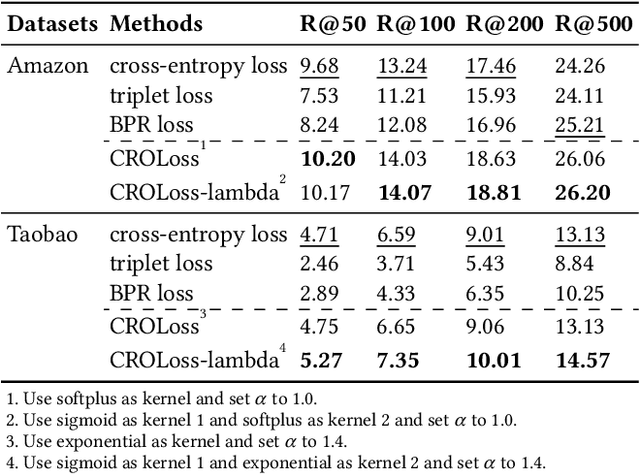
In large-scale recommender systems, retrieving top N relevant candidates accurately with resource constrain is crucial. To evaluate the performance of such retrieval models, Recall@N, the frequency of positive samples being retrieved in the top N ranking, is widely used. However, most of the conventional loss functions for retrieval models such as softmax cross-entropy and pairwise comparison methods do not directly optimize Recall@N. Moreover, those conventional loss functions cannot be customized for the specific retrieval size N required by each application and thus may lead to sub-optimal performance. In this paper, we proposed the Customizable Recall@N Optimization Loss (CROLoss), a loss function that can directly optimize the Recall@N metrics and is customizable for different choices of N. This proposed CROLoss formulation defines a more generalized loss function space, covering most of the conventional loss functions as special cases. Furthermore, we develop the Lambda method, a gradient-based method that invites more flexibility and can further boost the system performance. We evaluate the proposed CROLoss on two public benchmark datasets. The results show that CROLoss achieves SOTA results over conventional loss functions for both datasets with various choices of retrieval size N. CROLoss has been deployed onto our online E-commerce advertising platform, where a fourteen-day online A/B test demonstrated that CROLoss contributes to a significant business revenue growth of 4.75%.
Soft Retargeting Network for Click Through Rate Prediction
Jun 04, 2022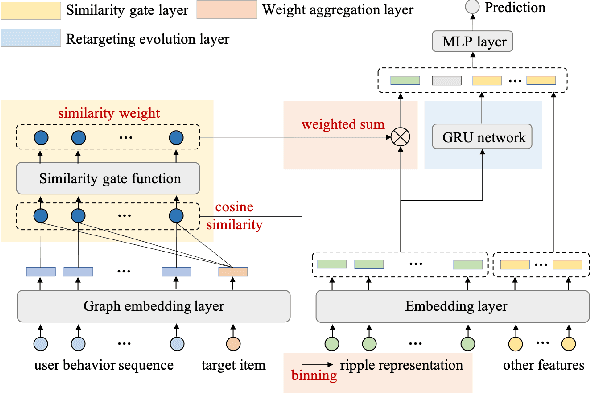



The study of user interest models has received a great deal of attention in click through rate (CTR) prediction recently. These models aim at capturing user interest from different perspectives, including user interest evolution, session interest, multiple interests, etc. In this paper, we focus on a new type of user interest, i.e., user retargeting interest. User retargeting interest is defined as user's click interest on target items the same as or similar to historical click items. We propose a novel soft retargeting network (SRN) to model this specific interest. Specifically, we first calculate the similarity between target item and each historical item with the help of graph embedding. Then we learn to aggregate the similarity weights to measure the extent of user's click interest on target item. Furthermore, we model the evolution of user retargeting interest. Experimental results on public datasets and industrial dataset demonstrate that our model achieves significant improvements over state-of-the-art models.
Adversarial Filtering Modeling on Long-term User Behavior Sequences for Click-Through Rate Prediction
Apr 26, 2022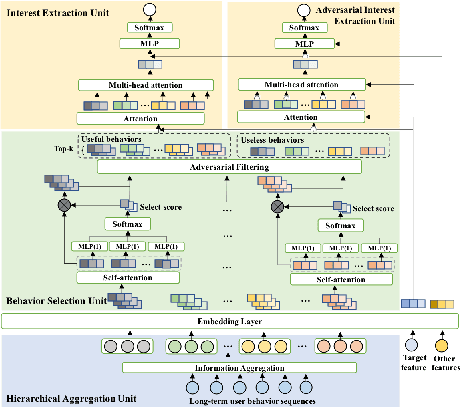


Rich user behavior information is of great importance for capturing and understanding user interest in click-through rate (CTR) prediction. To improve the richness, collecting long-term behaviors becomes a typical approach in academy and industry but at the cost of increasing online storage and latency. Recently, researchers have proposed several approaches to shorten long-term behavior sequence and then model user interests. These approaches reduce online cost efficiently but do not well handle the noisy information in long-term user behavior, which may deteriorate the performance of CTR prediction significantly. To obtain better cost/performance trade-off, we propose a novel Adversarial Filtering Model (ADFM) to model long-term user behavior. ADFM uses a hierarchical aggregation representation to compress raw behavior sequence and then learns to remove useless behavior information with an adversarial filtering mechanism. The selected user behaviors are fed into interest extraction module for CTR prediction. Experimental results on public datasets and industrial dataset demonstrate that our method achieves significant improvements over state-of-the-art models.