 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommendation as Generation: Unifying Personalized Video Generation and Recommendation at Industrial Scale
Jun 24, 2026Traditional short-video recommendation systems match user interest to a fixed pool of pre-produced videos, which limits their ability to capture fine-grained and dynamic preferences. We propose Recommendation-as-Generation (RaG), a new paradigm that generates personalized videos on demand from inferred user interest. Our framework unifies generative recommendation and video generation through shared semantic IDs (SIDs), which disentangle video representation into content semantics and creative style semantics, enabling both fine-grained modeling of user interest and controllable generation of interest-aligned videos. We further develop Video Generation Agents (VGAs) that are conditioned on inferred SIDs to drive hierarchical planning and refinement for video creation, including visual composition, audio alignment, and artistic effect enhancement. To optimize the framework, we effectively introduce a synergistic cross-domain reward learning mechanism that jointly enforces interest alignment, user feedback, and video quality assessment. We deploy RaG on an industrial-scale platform with over 400 million daily active users and evaluate it in a revenue-critical advertising scenario. Online A/B tests show up to 1.87% ad revenue improvement compared to a strong production GRM baseline, demonstrating its effectiveness in driving further revenue gains beyond generative recommendation. Our results highlight a closed-loop generative system as a promising paradigm for integrating personalized video generation into recommendation.
FBOS-RL: Feedback-Driven Bi-Objective Synergistic Reinforcement Learning
May 18, 2026Reinforcement learning has become a cornerstone for aligning and unlocking the reasoning capabilities of large-scale models. At its core, the training loop of GRPO and its variants alternates between rollout sampling and policy update. Unlike supervised learning, where each gradient step is anchored to an explicit ground-truth target, the optimal gradient direction for updating model parameters in this setting is not known a priori; the high-quality rollouts drawn during the sampling stage therefore act as the implicit "teacher" that guides every parameter update. However, GRPO adopt a simple sampling scheme that conditions all rollouts on the same original prompt. When a task lies beyond the policy model's current capability, this sampling scheme rarely yields a high-quality rollout, leaving the policy model without a meaningful gradient direction when updating its parameters, which causes training to stall. To address this issue, we propose FBOS-RL, a Feedback-Driven Bi-Objective Synergistic reinforcement learning framework. Specifically, we let the model perform Feedback-Guided Exploration Enhancement based on the feedback provided by the environment, and on top of this we design two mutually reinforcing training objectives: Exploitation-oriented Policy Alignment(EPA) and Exploration-oriented Capability Cultivation(ECC). Extensive experiments demonstrate that EPA and ECC can mutually reinforce each other, forming a positive flywheel effect that significantly improves both the training efficiency and the final performance ceiling of reinforcement learning. Specifically, under an identical number of rollouts, FBOS-RL learns substantially faster than GRPO and feedback-based baselines and ultimately attains a higher performance ceiling, while exhibiting higher policy entropy and lower gradient norms throughout training.
VQL: An End-to-End Context-Aware Vector Quantization Attention for Ultra-Long User Behavior Modeling
Aug 23, 2025In large-scale recommender systems, ultra-long user behavior sequences encode rich signals of evolving interests. Extending sequence length generally improves accuracy, but directly modeling such sequences in production is infeasible due to latency and memory constraints. Existing solutions fall into two categories: (1) top-k retrieval, which truncates the sequence and may discard most attention mass when L >> k; and (2) encoder-based compression, which preserves coverage but often over-compresses and fails to incorporate key context such as temporal gaps or target-aware signals. Neither class achieves a good balance of low-loss compression, context awareness, and efficiency. We propose VQL, a context-aware Vector Quantization Attention framework for ultra-long behavior modeling, with three innovations. (1) Key-only quantization: only attention keys are quantized, while values remain intact; we prove that softmax normalization yields an error bound independent of sequence length, and a codebook loss directly supervises quantization quality. This also enables L-free inference via offline caches. (2) Multi-scale quantization: attention heads are partitioned into groups, each with its own small codebook, which reduces quantization error while keeping cache size fixed. (3) Efficient context injection: static features (e.g., item category, modality) are directly integrated, and relative position is modeled via a separable temporal kernel. All context is injected without enlarging the codebook, so cached representations remain query-independent. Experiments on three large-scale datasets (KuaiRand-1K, KuaiRec, TMALL) show that VQL consistently outperforms strong baselines, achieving higher accuracy while reducing inference latency, establishing a new state of the art in balancing accuracy and efficiency for ultra-long sequence recommendation.
CHIME: A Compressive Framework for Holistic Interest Modeling
Apr 09, 2025Modeling holistic user interests is important for improving recommendation systems but is challenged by high computational cost and difficulty in handling diverse information with full behavior context. Existing search-based methods might lose critical signals during behavior selection. To overcome these limitations, we propose CHIME: A Compressive Framework for Holistic Interest Modeling. It uses adapted large language models to encode complete user behaviors with heterogeneous inputs. We introduce multi-granular contrastive learning objectives to capture both persistent and transient interest patterns and apply residual vector quantization to generate compact embeddings. CHIME demonstrates superior ranking performance across diverse datasets, establishing a robust solution for scalable holistic interest modeling in recommendation systems.
BBQRec: Behavior-Bind Quantization for Multi-Modal Sequential Recommendation
Apr 09, 2025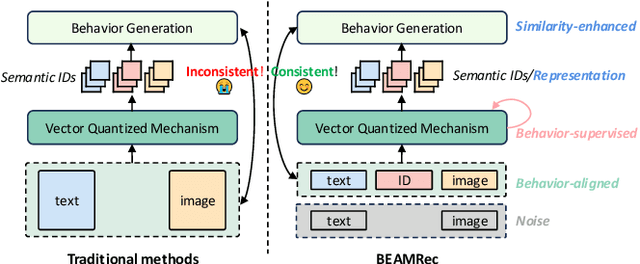
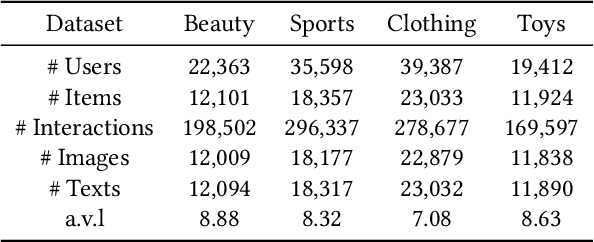
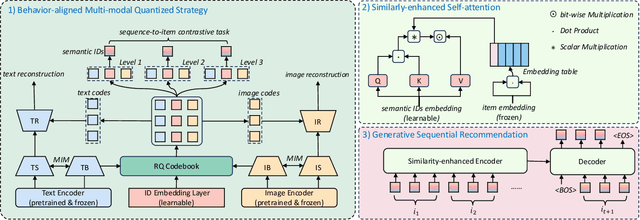
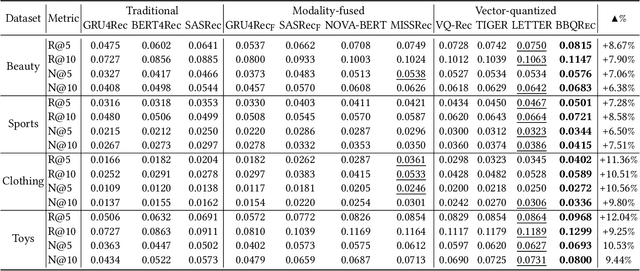
Multi-modal sequential recommendation systems leverage auxiliary signals (e.g., text, images) to alleviate data sparsity in user-item interactions. While recent methods exploit large language models to encode modalities into discrete semantic IDs for autoregressive prediction, we identify two critical limitations: (1) Existing approaches adopt fragmented quantization, where modalities are independently mapped to semantic spaces misaligned with behavioral objectives, and (2) Over-reliance on semantic IDs disrupts inter-modal semantic coherence, thereby weakening the expressive power of multi-modal representations for modeling diverse user preferences. To address these challenges, we propose a Behavior-Bind multi-modal Quantization for Sequential Recommendation (BBQRec for short) featuring dual-aligned quantization and semantics-aware sequence modeling. First, our behavior-semantic alignment module disentangles modality-agnostic behavioral patterns from noisy modality-specific features through contrastive codebook learning, ensuring semantic IDs are inherently tied to recommendation tasks. Second, we design a discretized similarity reweighting mechanism that dynamically adjusts self-attention scores using quantized semantic relationships, preserving multi-modal synergies while avoiding invasive modifications to the sequence modeling architecture. Extensive evaluations across four real-world benchmarks demonstrate BBQRec's superiority over the state-of-the-art baselines.
S-Diff: An Anisotropic Diffusion Model for Collaborative Filtering in Spectral Domain
Dec 31, 2024



Recovering user preferences from user-item interaction matrices is a key challenge in recommender systems. While diffusion models can sample and reconstruct preferences from latent distributions, they often fail to capture similar users' collective preferences effectively. Additionally, latent variables degrade into pure Gaussian noise during the forward process, lowering the signal-to-noise ratio, which in turn degrades performance. To address this, we propose S-Diff, inspired by graph-based collaborative filtering, better to utilize low-frequency components in the graph spectral domain. S-Diff maps user interaction vectors into the spectral domain and parameterizes diffusion noise to align with graph frequency. This anisotropic diffusion retains significant low-frequency components, preserving a high signal-to-noise ratio. S-Diff further employs a conditional denoising network to encode user interactions, recovering true preferences from noisy data. This method achieves strong results across multiple datasets.
Enhancing Instruction-Following Capability of Visual-Language Models by Reducing Image Redundancy
Nov 23, 2024


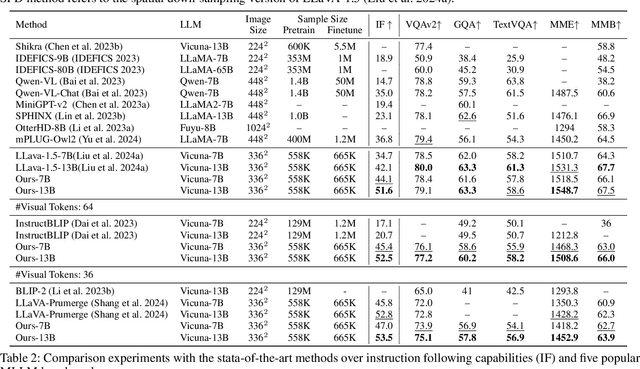
Large Language Models (LLMs) have strong instruction-following capability to interpret and execute tasks as directed by human commands. Multimodal Large Language Models (MLLMs) have inferior instruction-following ability compared to LLMs. However, there is a significant gap in the instruction-following capabilities between the MLLMs and LLMs. In this study, we conduct a pilot experiment, which demonstrates that spatially down-sampling visual tokens significantly enhances the instruction-following capability of MLLMs. This is attributed to the substantial redundancy in visual modality. However, this intuitive method severely impairs the MLLM's multimodal understanding capability. In this paper, we propose Visual-Modality Token Compression (VMTC) and Cross-Modality Attention Inhibition (CMAI) strategies to alleviate this gap between MLLMs and LLMs by inhibiting the influence of irrelevant visual tokens during content generation, increasing the instruction-following ability of the MLLMs while retaining their multimodal understanding capacity. In VMTC module, the primary tokens are retained and the redundant tokens are condensed by token clustering and merging. In CMAI process, we aggregate text-to-image attentions by text-to-text attentions to obtain a text-to-image focus score. Attention inhibition is performed on the text-image token pairs with low scores. Our comprehensive experiments over instruction-following capabilities and VQA-V2, GQA, TextVQA, MME and MMBench five benchmarks, demonstrate that proposed strategy significantly enhances the instruction following capability of MLLMs while preserving the ability to understand and process multimodal inputs.
Knowledge Condensation and Reasoning for Knowledge-based VQA
Mar 15, 2024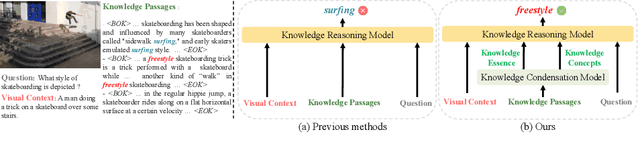
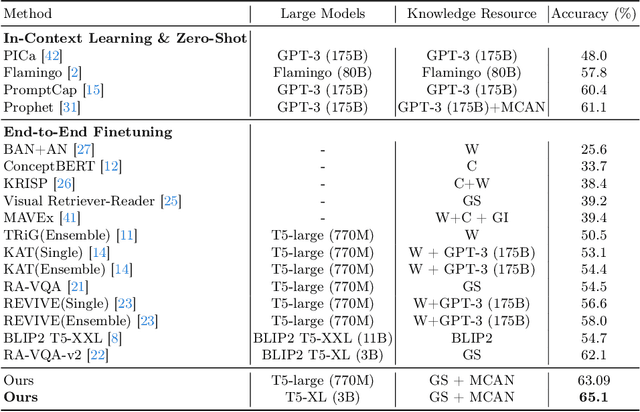
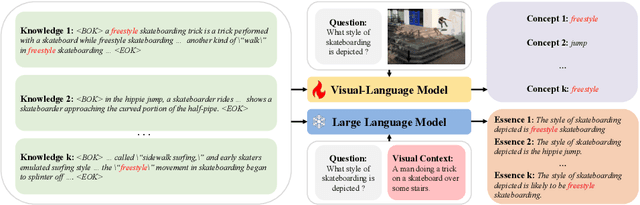
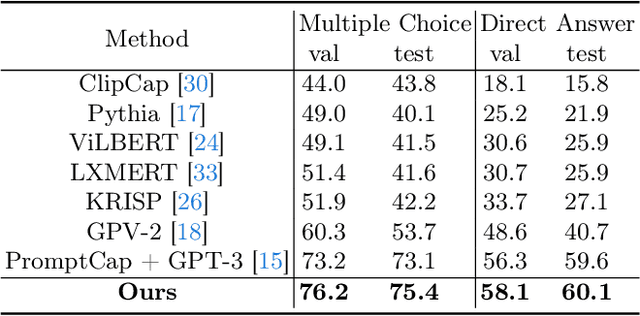
Knowledge-based visual question answering (KB-VQA) is a challenging task, which requires the model to leverage external knowledge for comprehending and answering questions grounded in visual content. Recent studies retrieve the knowledge passages from external knowledge bases and then use them to answer questions. However, these retrieved knowledge passages often contain irrelevant or noisy information, which limits the performance of the model. To address the challenge, we propose two synergistic models: Knowledge Condensation model and Knowledge Reasoning model. We condense the retrieved knowledge passages from two perspectives. First, we leverage the multimodal perception and reasoning ability of the visual-language models to distill concise knowledge concepts from retrieved lengthy passages, ensuring relevance to both the visual content and the question. Second, we leverage the text comprehension ability of the large language models to summarize and condense the passages into the knowledge essence which helps answer the question. These two types of condensed knowledge are then seamlessly integrated into our Knowledge Reasoning model, which judiciously navigates through the amalgamated information to arrive at the conclusive answer. Extensive experiments validate the superiority of the proposed method. Compared to previous methods, our method achieves state-of-the-art performance on knowledge-based VQA datasets (65.1% on OK-VQA and 60.1% on A-OKVQA) without resorting to the knowledge produced by GPT-3 (175B).
Towards Efficient and Effective Text-to-Video Retrieval with Coarse-to-Fine Visual Representation Learning
Jan 01, 2024



In recent years, text-to-video retrieval methods based on CLIP have experienced rapid development. The primary direction of evolution is to exploit the much wider gamut of visual and textual cues to achieve alignment. Concretely, those methods with impressive performance often design a heavy fusion block for sentence (words)-video (frames) interaction, regardless of the prohibitive computation complexity. Nevertheless, these approaches are not optimal in terms of feature utilization and retrieval efficiency. To address this issue, we adopt multi-granularity visual feature learning, ensuring the model's comprehensiveness in capturing visual content features spanning from abstract to detailed levels during the training phase. To better leverage the multi-granularity features, we devise a two-stage retrieval architecture in the retrieval phase. This solution ingeniously balances the coarse and fine granularity of retrieval content. Moreover, it also strikes a harmonious equilibrium between retrieval effectiveness and efficiency. Specifically, in training phase, we design a parameter-free text-gated interaction block (TIB) for fine-grained video representation learning and embed an extra Pearson Constraint to optimize cross-modal representation learning. In retrieval phase, we use coarse-grained video representations for fast recall of top-k candidates, which are then reranked by fine-grained video representations. Extensive experiments on four benchmarks demonstrate the efficiency and effectiveness. Notably, our method achieves comparable performance with the current state-of-the-art methods while being nearly 50 times faster.
Cross-view Semantic Alignment for Livestreaming Product Recognition
Aug 19, 2023



Live commerce is the act of selling products online through live streaming. The customer's diverse demands for online products introduce more challenges to Livestreaming Product Recognition. Previous works have primarily focused on fashion clothing data or utilize single-modal input, which does not reflect the real-world scenario where multimodal data from various categories are present. In this paper, we present LPR4M, a large-scale multimodal dataset that covers 34 categories, comprises 3 modalities (image, video, and text), and is 50x larger than the largest publicly available dataset. LPR4M contains diverse videos and noise modality pairs while exhibiting a long-tailed distribution, resembling real-world problems. Moreover, a cRoss-vIew semantiC alignmEnt (RICE) model is proposed to learn discriminative instance features from the image and video views of the products. This is achieved through instance-level contrastive learning and cross-view patch-level feature propagation. A novel Patch Feature Reconstruction loss is proposed to penalize the semantic misalignment between cross-view patches. Extensive experiments demonstrate the effectiveness of RICE and provide insights into the importance of dataset diversity and expressivity. The dataset and code are available at https://github.com/adxcreative/RICE