 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedSAM-Agent: Empowering Interactive Medical Image Segmentation with Multi-turn Agentic Reinforcement Learning
Feb 03, 2026Medical image segmentation is evolving from task-specific models toward generalizable frameworks. Recent research leverages Multi-modal Large Language Models (MLLMs) as autonomous agents, employing reinforcement learning with verifiable reward (RLVR) to orchestrate specialized tools like the Segment Anything Model (SAM). However, these approaches often rely on single-turn, rigid interaction strategies and lack process-level supervision during training, which hinders their ability to fully exploit the dynamic potential of interactive tools and leads to redundant actions. To bridge this gap, we propose MedSAM-Agent, a framework that reformulates interactive segmentation as a multi-step autonomous decision-making process. First, we introduce a hybrid prompting strategy for expert-curated trajectory generation, enabling the model to internalize human-like decision heuristics and adaptive refinement strategies. Furthermore, we develop a two-stage training pipeline that integrates multi-turn, end-to-end outcome verification with a clinical-fidelity process reward design to promote interaction parsimony and decision efficiency. Extensive experiments across 6 medical modalities and 21 datasets demonstrate that MedSAM-Agent achieves state-of-the-art performance, effectively unifying autonomous medical reasoning with robust, iterative optimization. Code is available \href{https://github.com/CUHK-AIM-Group/MedSAM-Agent}{here}.
Unveiling and Bridging the Functional Perception Gap in MLLMs: Atomic Visual Alignment and Hierarchical Evaluation via PET-Bench
Jan 06, 2026While Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in tasks such as abnormality detection and report generation for anatomical modalities, their capability in functional imaging remains largely unexplored. In this work, we identify and quantify a fundamental functional perception gap: the inability of current vision encoders to decode functional tracer biodistribution independent of morphological priors. Identifying Positron Emission Tomography (PET) as the quintessential modality to investigate this disconnect, we introduce PET-Bench, the first large-scale functional imaging benchmark comprising 52,308 hierarchical QA pairs from 9,732 multi-site, multi-tracer PET studies. Extensive evaluation of 19 state-of-the-art MLLMs reveals a critical safety hazard termed the Chain-of-Thought (CoT) hallucination trap. We observe that standard CoT prompting, widely considered to enhance reasoning, paradoxically decouples linguistic generation from visual evidence in PET, producing clinically fluent but factually ungrounded diagnoses. To resolve this, we propose Atomic Visual Alignment (AVA), a simple fine-tuning strategy that enforces the mastery of low-level functional perception prior to high-level diagnostic reasoning. Our results demonstrate that AVA effectively bridges the perception gap, transforming CoT from a source of hallucination into a robust inference tool and improving diagnostic accuracy by up to 14.83%. Code and data are available at https://github.com/yezanting/PET-Bench.
Medical Reasoning in the Era of LLMs: A Systematic Review of Enhancement Techniques and Applications
Aug 01, 2025The proliferation of Large Language Models (LLMs) in medicine has enabled impressive capabilities, yet a critical gap remains in their ability to perform systematic, transparent, and verifiable reasoning, a cornerstone of clinical practice. This has catalyzed a shift from single-step answer generation to the development of LLMs explicitly designed for medical reasoning. This paper provides the first systematic review of this emerging field. We propose a taxonomy of reasoning enhancement techniques, categorized into training-time strategies (e.g., supervised fine-tuning, reinforcement learning) and test-time mechanisms (e.g., prompt engineering, multi-agent systems). We analyze how these techniques are applied across different data modalities (text, image, code) and in key clinical applications such as diagnosis, education, and treatment planning. Furthermore, we survey the evolution of evaluation benchmarks from simple accuracy metrics to sophisticated assessments of reasoning quality and visual interpretability. Based on an analysis of 60 seminal studies from 2022-2025, we conclude by identifying critical challenges, including the faithfulness-plausibility gap and the need for native multimodal reasoning, and outlining future directions toward building efficient, robust, and sociotechnically responsible medical AI.
TumorGen: Boundary-Aware Tumor-Mask Synthesis with Rectified Flow Matching
May 30, 2025


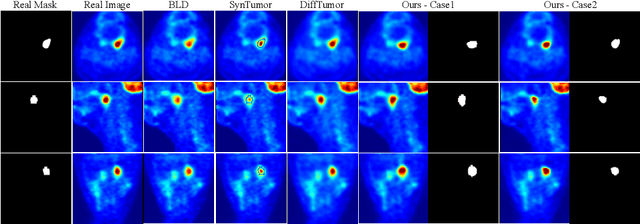
Tumor data synthesis offers a promising solution to the shortage of annotated medical datasets. However, current approaches either limit tumor diversity by using predefined masks or employ computationally expensive two-stage processes with multiple denoising steps, causing computational inefficiency. Additionally, these methods typically rely on binary masks that fail to capture the gradual transitions characteristic of tumor boundaries. We present TumorGen, a novel Boundary-Aware Tumor-Mask Synthesis with Rectified Flow Matching for efficient 3D tumor synthesis with three key components: a Boundary-Aware Pseudo Mask Generation module that replaces strict binary masks with flexible bounding boxes; a Spatial-Constraint Vector Field Estimator that simultaneously synthesizes tumor latents and masks using rectified flow matching to ensure computational efficiency; and a VAE-guided mask refiner that enhances boundary realism. TumorGen significantly improves computational efficiency by requiring fewer sampling steps while maintaining pathological accuracy through coarse and fine-grained spatial constraints. Experimental results demonstrate TumorGen's superior performance over existing tumor synthesis methods in both efficiency and realism, offering a valuable contribution to AI-driven cancer diagnostics.
A Comprehensive Evaluation of Multi-Modal Large Language Models for Endoscopy Analysis
May 29, 2025



Endoscopic procedures are essential for diagnosing and treating internal diseases, and multi-modal large language models (MLLMs) are increasingly applied to assist in endoscopy analysis. However, current benchmarks are limited, as they typically cover specific endoscopic scenarios and a small set of clinical tasks, failing to capture the real-world diversity of endoscopic scenarios and the full range of skills needed in clinical workflows. To address these issues, we introduce EndoBench, the first comprehensive benchmark specifically designed to assess MLLMs across the full spectrum of endoscopic practice with multi-dimensional capacities. EndoBench encompasses 4 distinct endoscopic scenarios, 12 specialized clinical tasks with 12 secondary subtasks, and 5 levels of visual prompting granularities, resulting in 6,832 rigorously validated VQA pairs from 21 diverse datasets. Our multi-dimensional evaluation framework mirrors the clinical workflow--spanning anatomical recognition, lesion analysis, spatial localization, and surgical operations--to holistically gauge the perceptual and diagnostic abilities of MLLMs in realistic scenarios. We benchmark 23 state-of-the-art models, including general-purpose, medical-specialized, and proprietary MLLMs, and establish human clinician performance as a reference standard. Our extensive experiments reveal: (1) proprietary MLLMs outperform open-source and medical-specialized models overall, but still trail human experts; (2) medical-domain supervised fine-tuning substantially boosts task-specific accuracy; and (3) model performance remains sensitive to prompt format and clinical task complexity. EndoBench establishes a new standard for evaluating and advancing MLLMs in endoscopy, highlighting both progress and persistent gaps between current models and expert clinical reasoning. We publicly release our benchmark and code.
Polyp-Gen: Realistic and Diverse Polyp Image Generation for Endoscopic Dataset Expansion
Jan 29, 2025



Automated diagnostic systems (ADS) have shown significant potential in the early detection of polyps during endoscopic examinations, thereby reducing the incidence of colorectal cancer. However, due to high annotation costs and strict privacy concerns, acquiring high-quality endoscopic images poses a considerable challenge in the development of ADS. Despite recent advancements in generating synthetic images for dataset expansion, existing endoscopic image generation algorithms failed to accurately generate the details of polyp boundary regions and typically required medical priors to specify plausible locations and shapes of polyps, which limited the realism and diversity of the generated images. To address these limitations, we present Polyp-Gen, the first full-automatic diffusion-based endoscopic image generation framework. Specifically, we devise a spatial-aware diffusion training scheme with a lesion-guided loss to enhance the structural context of polyp boundary regions. Moreover, to capture medical priors for the localization of potential polyp areas, we introduce a hierarchical retrieval-based sampling strategy to match similar fine-grained spatial features. In this way, our Polyp-Gen can generate realistic and diverse endoscopic images for building reliable ADS. Extensive experiments demonstrate the state-of-the-art generation quality, and the synthetic images can improve the downstream polyp detection task. Additionally, our Polyp-Gen has shown remarkable zero-shot generalizability on other datasets. The source code is available at https://github.com/CUHK-AIM-Group/Polyp-Gen.
Enhancing Instruction-Following Capability of Visual-Language Models by Reducing Image Redundancy
Nov 23, 2024


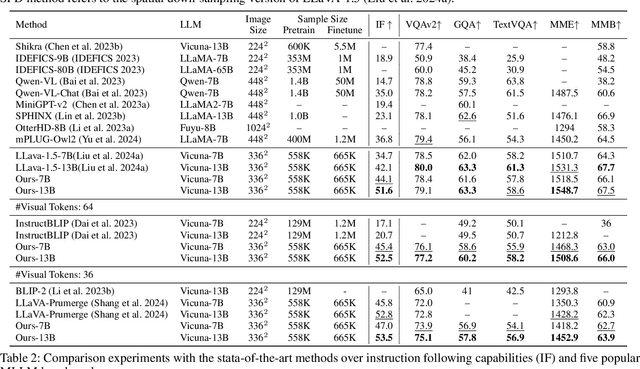
Large Language Models (LLMs) have strong instruction-following capability to interpret and execute tasks as directed by human commands. Multimodal Large Language Models (MLLMs) have inferior instruction-following ability compared to LLMs. However, there is a significant gap in the instruction-following capabilities between the MLLMs and LLMs. In this study, we conduct a pilot experiment, which demonstrates that spatially down-sampling visual tokens significantly enhances the instruction-following capability of MLLMs. This is attributed to the substantial redundancy in visual modality. However, this intuitive method severely impairs the MLLM's multimodal understanding capability. In this paper, we propose Visual-Modality Token Compression (VMTC) and Cross-Modality Attention Inhibition (CMAI) strategies to alleviate this gap between MLLMs and LLMs by inhibiting the influence of irrelevant visual tokens during content generation, increasing the instruction-following ability of the MLLMs while retaining their multimodal understanding capacity. In VMTC module, the primary tokens are retained and the redundant tokens are condensed by token clustering and merging. In CMAI process, we aggregate text-to-image attentions by text-to-text attentions to obtain a text-to-image focus score. Attention inhibition is performed on the text-image token pairs with low scores. Our comprehensive experiments over instruction-following capabilities and VQA-V2, GQA, TextVQA, MME and MMBench five benchmarks, demonstrate that proposed strategy significantly enhances the instruction following capability of MLLMs while preserving the ability to understand and process multimodal inputs.
Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
May 11, 2024Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.