 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders
Jan 15, 2026Recent progress in text-to-image (T2I) diffusion models (DMs) has enabled high-quality visual synthesis from diverse textual prompts. Yet, most existing T2I DMs, even those equipped with large language model (LLM)-based text encoders, remain text-pixel mappers -- they employ LLMs merely as text encoders, without leveraging their inherent reasoning capabilities to infer what should be visually depicted given the textual prompt. To move beyond such literal generation, we propose the think-then-generate (T2G) paradigm, where the LLM-based text encoder is encouraged to reason about and rewrite raw user prompts; the states of the rewritten prompts then serve as diffusion conditioning. To achieve this, we first activate the think-then-rewrite pattern of the LLM encoder with a lightweight supervised fine-tuning process. Subsequently, the LLM encoder and diffusion backbone are co-optimized to ensure faithful reasoning about the context and accurate rendering of the semantics via Dual-GRPO. In particular, the text encoder is reinforced using image-grounded rewards to infer and recall world knowledge, while the diffusion backbone is pushed to produce semantically consistent and visually coherent images. Experiments show substantial improvements in factual consistency, semantic alignment, and visual realism across reasoning-based image generation and editing benchmarks, achieving 0.79 on WISE score, nearly on par with GPT-4. Our results constitute a promising step toward next-generation unified models with reasoning, expression, and demonstration capacities.
RETuning: Upgrading Inference-Time Scaling for Stock Movement Prediction with Large Language Models
Oct 24, 2025Recently, large language models (LLMs) have demonstrated outstanding reasoning capabilities on mathematical and coding tasks. However, their application to financial tasks-especially the most fundamental task of stock movement prediction-remains underexplored. We study a three-class classification problem (up, hold, down) and, by analyzing existing reasoning responses, observe that: (1) LLMs follow analysts' opinions rather than exhibit a systematic, independent analytical logic (CoTs). (2) LLMs list summaries from different sources without weighing adversarial evidence, yet such counterevidence is crucial for reliable prediction. It shows that the model does not make good use of its reasoning ability to complete the task. To address this, we propose Reflective Evidence Tuning (RETuning), a cold-start method prior to reinforcement learning, to enhance prediction ability. While generating CoT, RETuning encourages dynamically constructing an analytical framework from diverse information sources, organizing and scoring evidence for price up or down based on that framework-rather than on contextual viewpoints-and finally reflecting to derive the prediction. This approach maximally aligns the model with its learned analytical framework, ensuring independent logical reasoning and reducing undue influence from context. We also build a large-scale dataset spanning all of 2024 for 5,123 A-share stocks, with long contexts (32K tokens) and over 200K samples. In addition to price and news, it incorporates analysts' opinions, quantitative reports, fundamental data, macroeconomic indicators, and similar stocks. Experiments show that RETuning successfully unlocks the model's reasoning ability in the financial domain. Inference-time scaling still works even after 6 months or on out-of-distribution stocks, since the models gain valuable insights about stock movement prediction.
Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks
Oct 14, 2025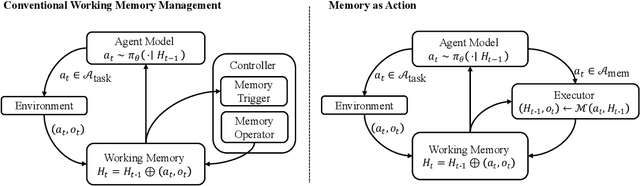
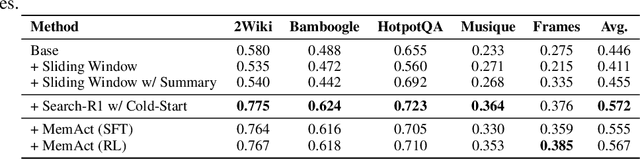
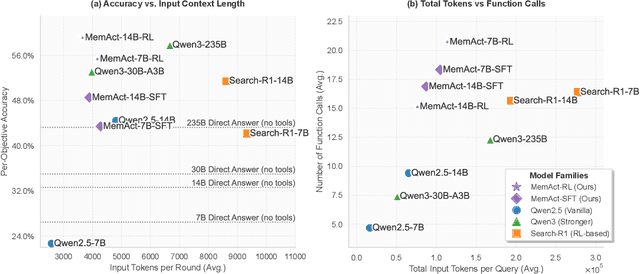
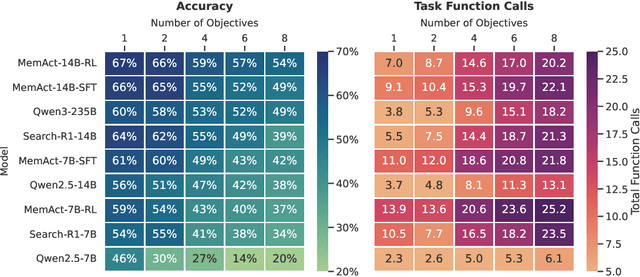
Large Language Models face challenges in long-horizon agentic tasks as their constrained memory is easily overwhelmed by distracting or irrelevant context. Existing working memory methods typically rely on external, heuristic mechanisms that are decoupled from the agent's core policy. In this work, we reframe working memory management as a learnable, intrinsic capability. We propose a novel framework, Memory-as-Action, where an agent actively manages its working memory by executing explicit editing operations as part of a unified policy. This formulation allows an agent, trained via reinforcement learning, to balance memory curation against long-term task objectives under given resource constraints. However, such memory editing actions break the standard assumption of a continuously growing prefix in LLM interactions, leading to what we call trajectory fractures. These non-prefix changes disrupt the causal continuity required by standard policy gradient methods, making those methods inapplicable. To address this, we propose a new algorithm, Dynamic Context Policy Optimization, which enables stable end-to-end reinforcement learning by segmenting trajectories at memory action points and applying trajectory-level advantages to the resulting action segments. Our results demonstrate that jointly optimizing for task reasoning and memory management in an end-to-end fashion not only reduces overall computational consumption but also improves task performance, driven by adaptive context curation strategies tailored to the model's intrinsic capabilities.
Text-Video Multi-Grained Integration for Video Moment Montage
Dec 12, 2024The proliferation of online short video platforms has driven a surge in user demand for short video editing. However, manually selecting, cropping, and assembling raw footage into a coherent, high-quality video remains laborious and time-consuming. To accelerate this process, we focus on a user-friendly new task called Video Moment Montage (VMM), which aims to accurately locate the corresponding video segments based on a pre-provided narration text and then arrange these video clips to create a complete video that aligns with the corresponding descriptions. The challenge lies in extracting precise temporal segments while ensuring intra-sentence and inter-sentence context consistency, as a single script sentence may require trimming and assembling multiple video clips. To address this problem, we present a novel \textit{Text-Video Multi-Grained Integration} method (TV-MGI) that efficiently fuses text features from the script with both shot-level and frame-level video features, which enables the global and fine-grained alignment between the video content and the corresponding textual descriptions in the script. To facilitate further research in this area, we introduce the Multiple Sentences with Shots Dataset (MSSD), a large-scale dataset designed explicitly for the VMM task. We conduct extensive experiments on the MSSD dataset to demonstrate the effectiveness of our framework compared to baseline methods.
Orthus: Autoregressive Interleaved Image-Text Generation with Modality-Specific Heads
Nov 28, 2024
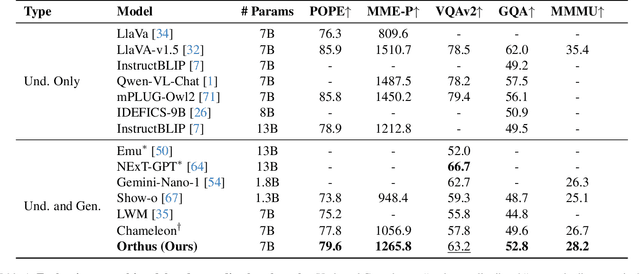
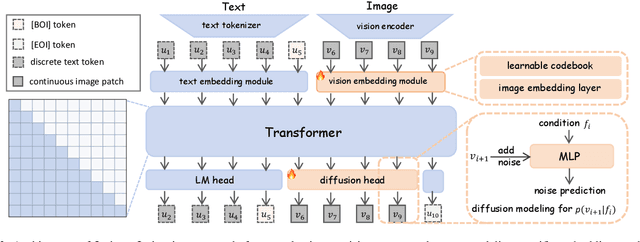
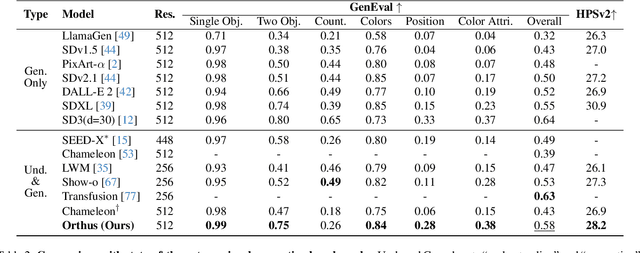
We introduce Orthus, an autoregressive (AR) transformer that excels in generating images given textual prompts, answering questions based on visual inputs, and even crafting lengthy image-text interleaved contents. Unlike prior arts on unified multimodal modeling, Orthus simultaneously copes with discrete text tokens and continuous image features under the AR modeling principle. The continuous treatment of visual signals minimizes the information loss for both image understanding and generation while the fully AR formulation renders the characterization of the correlation between modalities straightforward. The key mechanism enabling Orthus to leverage these advantages lies in its modality-specific heads -- one regular language modeling (LM) head predicts discrete text tokens and one diffusion head generates continuous image features conditioning on the output of the backbone. We devise an efficient strategy for building Orthus -- by substituting the Vector Quantization (VQ) operation in the existing unified AR model with a soft alternative, introducing a diffusion head, and tuning the added modules to reconstruct images, we can create an Orthus-base model effortlessly (e.g., within mere 72 A100 GPU hours). Orthus-base can further embrace post-training to better model interleaved images and texts. Empirically, Orthus surpasses competing baselines including Show-o and Chameleon across standard benchmarks, achieving a GenEval score of 0.58 and an MME-P score of 1265.8 using 7B parameters. Orthus also shows exceptional mixed-modality generation capabilities, reflecting the potential for handling intricate practical generation tasks.
D&M: Enriching E-commerce Videos with Sound Effects by Key Moment Detection and SFX Matching
Aug 23, 2024Videos showcasing specific products are increasingly important for E-commerce. Key moments naturally exist as the first appearance of a specific product, presentation of its distinctive features, the presence of a buying link, etc. Adding proper sound effects (SFX) to these key moments, or video decoration with SFX (VDSFX), is crucial for enhancing the user engaging experience. Previous studies about adding SFX to videos perform video to SFX matching at a holistic level, lacking the ability of adding SFX to a specific moment. Meanwhile, previous studies on video highlight detection or video moment retrieval consider only moment localization, leaving moment to SFX matching untouched. By contrast, we propose in this paper D&M, a unified method that accomplishes key moment detection and moment to SFX matching simultaneously. Moreover, for the new VDSFX task we build a large-scale dataset SFX-Moment from an E-commerce platform. For a fair comparison, we build competitive baselines by extending a number of current video moment detection methods to the new task. Extensive experiments on SFX-Moment show the superior performance of the proposed method over the baselines. Code and data will be released.
Training-free Subject-Enhanced Attention Guidance for Compositional Text-to-image Generation
May 11, 2024Existing subject-driven text-to-image generation models suffer from tedious fine-tuning steps and struggle to maintain both text-image alignment and subject fidelity. For generating compositional subjects, it often encounters problems such as object missing and attribute mixing, where some subjects in the input prompt are not generated or their attributes are incorrectly combined. To address these limitations, we propose a subject-driven generation framework and introduce training-free guidance to intervene in the generative process during inference time. This approach strengthens the attention map, allowing for precise attribute binding and feature injection for each subject. Notably, our method exhibits exceptional zero-shot generation ability, especially in the challenging task of compositional generation. Furthermore, we propose a novel metric GroundingScore to evaluate subject alignment thoroughly. The obtained quantitative results serve as compelling evidence showcasing the effectiveness of our proposed method. The code will be released soon.
AutoPoster: A Highly Automatic and Content-aware Design System for Advertising Poster Generation
Aug 23, 2023



Advertising posters, a form of information presentation, combine visual and linguistic modalities. Creating a poster involves multiple steps and necessitates design experience and creativity. This paper introduces AutoPoster, a highly automatic and content-aware system for generating advertising posters. With only product images and titles as inputs, AutoPoster can automatically produce posters of varying sizes through four key stages: image cleaning and retargeting, layout generation, tagline generation, and style attribute prediction. To ensure visual harmony of posters, two content-aware models are incorporated for layout and tagline generation. Moreover, we propose a novel multi-task Style Attribute Predictor (SAP) to jointly predict visual style attributes. Meanwhile, to our knowledge, we propose the first poster generation dataset that includes visual attribute annotations for over 76k posters. Qualitative and quantitative outcomes from user studies and experiments substantiate the efficacy of our system and the aesthetic superiority of the generated posters compared to other poster generation methods.
A Semi-Autoregressive Graph Generative Model for Dependency Graph Parsing
Jun 21, 2023



Recent years have witnessed the impressive progress in Neural Dependency Parsing. According to the different factorization approaches to the graph joint probabilities, existing parsers can be roughly divided into autoregressive and non-autoregressive patterns. The former means that the graph should be factorized into multiple sequentially dependent components, then it can be built up component by component. And the latter assumes these components to be independent so that they can be outputted in a one-shot manner. However, when treating the directed edge as an explicit dependency relationship, we discover that there is a mixture of independent and interdependent components in the dependency graph, signifying that both aforementioned models fail to precisely capture the explicit dependencies among nodes and edges. Based on this property, we design a Semi-Autoregressive Dependency Parser to generate dependency graphs via adding node groups and edge groups autoregressively while pouring out all group elements in parallel. The model gains a trade-off between non-autoregression and autoregression, which respectively suffer from the lack of target inter-dependencies and the uncertainty of graph generation orders. The experiments show the proposed parser outperforms strong baselines on Enhanced Universal Dependencies of multiple languages, especially achieving $4\%$ average promotion at graph-level accuracy. Also, the performances of model variations show the importance of specific parts.
Geometry Aligned Variational Transformer for Image-conditioned Layout Generation
Sep 02, 2022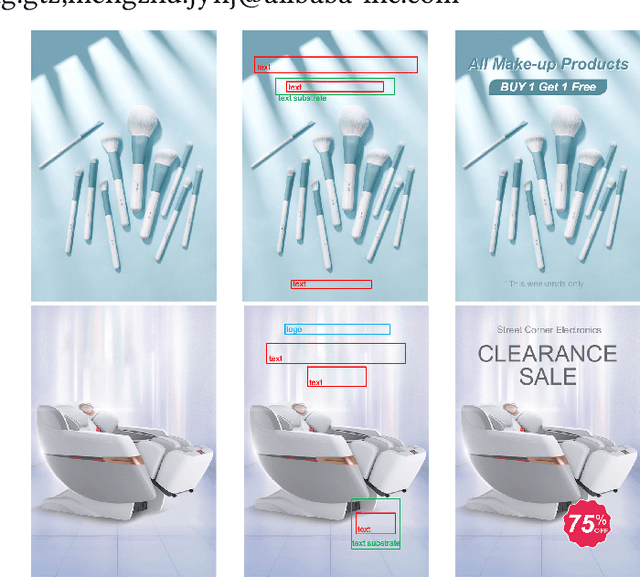
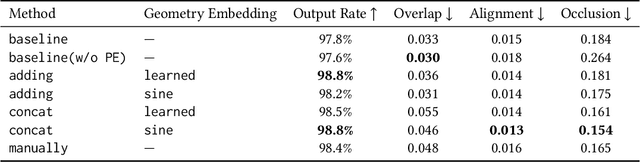
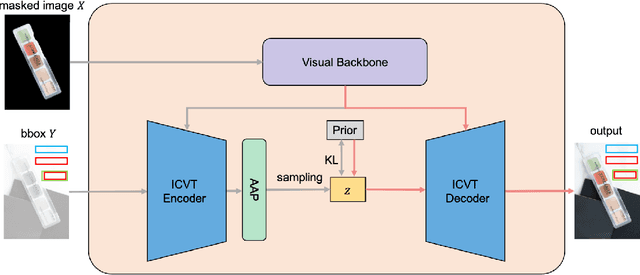

Layout generation is a novel task in computer vision, which combines the challenges in both object localization and aesthetic appraisal, widely used in advertisements, posters, and slides design. An accurate and pleasant layout should consider both the intra-domain relationship within layout elements and the inter-domain relationship between layout elements and the image. However, most previous methods simply focus on image-content-agnostic layout generation, without leveraging the complex visual information from the image. To this end, we explore a novel paradigm entitled image-conditioned layout generation, which aims to add text overlays to an image in a semantically coherent manner. Specifically, we propose an Image-Conditioned Variational Transformer (ICVT) that autoregressively generates various layouts in an image. First, self-attention mechanism is adopted to model the contextual relationship within layout elements, while cross-attention mechanism is used to fuse the visual information of conditional images. Subsequently, we take them as building blocks of conditional variational autoencoder (CVAE), which demonstrates appealing diversity. Second, in order to alleviate the gap between layout elements domain and visual domain, we design a Geometry Alignment module, in which the geometric information of the image is aligned with the layout representation. In addition, we construct a large-scale advertisement poster layout designing dataset with delicate layout and saliency map annotations. Experimental results show that our model can adaptively generate layouts in the non-intrusive area of the image, resulting in a harmonious layout design.