 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposition-aware Graphic Layout GAN for Visual-textual Presentation Designs
Paper and Code


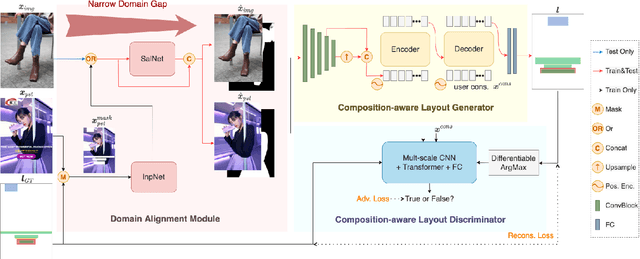

In this paper, we study the graphic layout generation problem of producing high-quality visual-textual presentation designs for given images. We note that image compositions, which contain not only global semantics but also spatial information, would largely affect layout results. Hence, we propose a deep generative model, dubbed as composition-aware graphic layout GAN (CGL-GAN), to synthesize layouts based on the global and spatial visual contents of input images. To obtain training images from images that already contain manually designed graphic layout data, previous work suggests masking design elements (e.g., texts and embellishments) as model inputs, which inevitably leaves hint of the ground truth. We study the misalignment between the training inputs (with hint masks) and test inputs (without masks), and design a novel domain alignment module (DAM) to narrow this gap. For training, we built a large-scale layout dataset which consists of 60,548 advertising posters with annotated layout information. To evaluate the generated layouts, we propose three novel metrics according to aesthetic intuitions. Through both quantitative and qualitative evaluations, we demonstrate that the proposed model can synthesize high-quality graphic layouts according to image compositions.