 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-based Domain Adaptation for Image-aware Layout Generation in Advertising Poster Design
Apr 08, 2026Layout plays a crucial role in graphic design and poster generation. Recently, the application of deep learning models for layout generation has gained significant attention. This paper focuses on using a GAN-based model conditioned on images to generate advertising poster graphic layouts, requiring a dataset of paired product images and layouts. To address this task, we introduce the Content-aware Graphic Layout Dataset (CGL-Dataset), consisting of 60,548 paired inpainted posters with annotations and 121,000 clean product images. The inpainting artifacts introduce a domain gap between the inpainted posters and clean images. To bridge this gap, we design two GAN-based models. The first model, CGL-GAN, uses Gaussian blur on the inpainted regions to generate layouts. The second model combines unsupervised domain adaptation by introducing a GAN with a pixel-level discriminator (PD), abbreviated as PDA-GAN, to generate image-aware layouts based on the visual texture of input images. The PD is connected to shallow-level feature maps and computes the GAN loss for each input-image pixel. Additionally, we propose three novel content-aware metrics to assess the model's ability to capture the intricate relationships between graphic elements and image content. Quantitative and qualitative evaluations demonstrate that PDA-GAN achieves state-of-the-art performance and generates high-quality image-aware layouts.
Hybrid Deep Learning with Temporal Data Augmentation for Accurate Remaining Useful Life Prediction of Lithium-Ion Batteries
Mar 28, 2026Accurate prediction of lithium-ion battery remaining useful life (RUL) is essential for reliable health monitoring and data-driven analysis of battery degradation. However, the robustness and generalization capabilities of existing RUL prediction models are significantly challenged by complex operating conditions and limited data availability. To address these limitations, this study proposes a hybrid deep learning model, CDFormer, which integrates convolutional neural networks, deep residual shrinkage networks, and Transformer encoders extract multiscale temporal features from battery measurement signals, including voltage, current, and capacity. This architecture enables the joint modeling of local and global degradation dynamics, effectively improving the accuracy of RUL prediction.To enhance predictive reliability, a composite temporal data augmentation strategy is proposed, incorporating Gaussian noise, time warping, and time resampling, explicitly accounting for measurement noise and variability. CDFormer is evaluated on two real-world datasets, with experimental results demonstrating its consistent superiority over conventional recurrent neural network-based and Transformer-based baselines across key metrics. By improving the reliability and predictive performance of RUL prediction from measurement data, CDFormer provides accurate and reliable forecasts, supporting effective battery health monitoring and data-driven maintenance strategies.
Joint Shadow Generation and Relighting via Light-Geometry Interaction Maps
Feb 25, 2026We propose Light-Geometry Interaction (LGI) maps, a novel representation that encodes light-aware occlusion from monocular depth. Unlike ray tracing, which requires full 3D reconstruction, LGI captures essential light-shadow interactions reliably and accurately, computed from off-the-shelf 2.5D depth map predictions. LGI explicitly ties illumination direction to geometry, providing a physics-inspired prior that constrains generative models. Without such prior, these models often produce floating shadows, inconsistent illumination, and implausible shadow geometry. Building on this representation, we propose a unified pipeline for joint shadow generation and relighting - unlike prior methods that treat them as disjoint tasks - capturing the intrinsic coupling of illumination and shadowing essential for modeling indirect effects. By embedding LGI into a bridge-matching generative backbone, we reduce ambiguity and enforce physically consistent light-shadow reasoning. To enable effective training, we curated the first large-scale benchmark dataset for joint shadow and relighting, covering reflections, transparency, and complex interreflections. Experiments show significant gains in realism and consistency across synthetic and real images. LGI thus bridges geometry-inspired rendering with generative modeling, enabling efficient, physically consistent shadow generation and relighting.
Learning Visual Hierarchies with Hyperbolic Embeddings
Nov 26, 2024Structuring latent representations in a hierarchical manner enables models to learn patterns at multiple levels of abstraction. However, most prevalent image understanding models focus on visual similarity, and learning visual hierarchies is relatively unexplored. In this work, for the first time, we introduce a learning paradigm that can encode user-defined multi-level visual hierarchies in hyperbolic space without requiring explicit hierarchical labels. As a concrete example, first, we define a part-based image hierarchy using object-level annotations within and across images. Then, we introduce an approach to enforce the hierarchy using contrastive loss with pairwise entailment metrics. Finally, we discuss new evaluation metrics to effectively measure hierarchical image retrieval. Encoding these complex relationships ensures that the learned representations capture semantic and structural information that transcends mere visual similarity. Experiments in part-based image retrieval show significant improvements in hierarchical retrieval tasks, demonstrating the capability of our model in capturing visual hierarchies.
Unsupervised Domain Adaption with Pixel-level Discriminator for Image-aware Layout Generation
Mar 25, 2023



Layout is essential for graphic design and poster generation. Recently, applying deep learning models to generate layouts has attracted increasing attention. This paper focuses on using the GAN-based model conditioned on image contents to generate advertising poster graphic layouts, which requires an advertising poster layout dataset with paired product images and graphic layouts. However, the paired images and layouts in the existing dataset are collected by inpainting and annotating posters, respectively. There exists a domain gap between inpainted posters (source domain data) and clean product images (target domain data). Therefore, this paper combines unsupervised domain adaption techniques to design a GAN with a novel pixel-level discriminator (PD), called PDA-GAN, to generate graphic layouts according to image contents. The PD is connected to the shallow level feature map and computes the GAN loss for each input-image pixel. Both quantitative and qualitative evaluations demonstrate that PDA-GAN can achieve state-of-the-art performances and generate high-quality image-aware graphic layouts for advertising posters.
Composition-aware Graphic Layout GAN for Visual-textual Presentation Designs
Apr 30, 2022

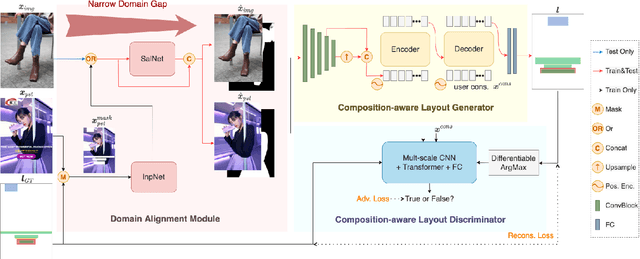

In this paper, we study the graphic layout generation problem of producing high-quality visual-textual presentation designs for given images. We note that image compositions, which contain not only global semantics but also spatial information, would largely affect layout results. Hence, we propose a deep generative model, dubbed as composition-aware graphic layout GAN (CGL-GAN), to synthesize layouts based on the global and spatial visual contents of input images. To obtain training images from images that already contain manually designed graphic layout data, previous work suggests masking design elements (e.g., texts and embellishments) as model inputs, which inevitably leaves hint of the ground truth. We study the misalignment between the training inputs (with hint masks) and test inputs (without masks), and design a novel domain alignment module (DAM) to narrow this gap. For training, we built a large-scale layout dataset which consists of 60,548 advertising posters with annotated layout information. To evaluate the generated layouts, we propose three novel metrics according to aesthetic intuitions. Through both quantitative and qualitative evaluations, we demonstrate that the proposed model can synthesize high-quality graphic layouts according to image compositions.
Transcribing Natural Languages for The Deaf via Neural Editing Programs
Dec 17, 2021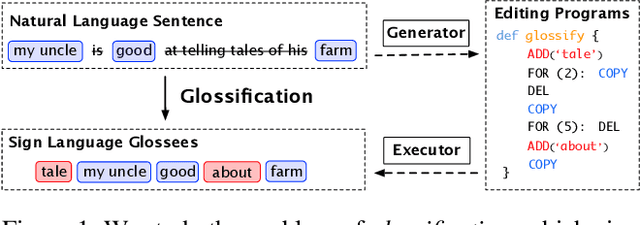


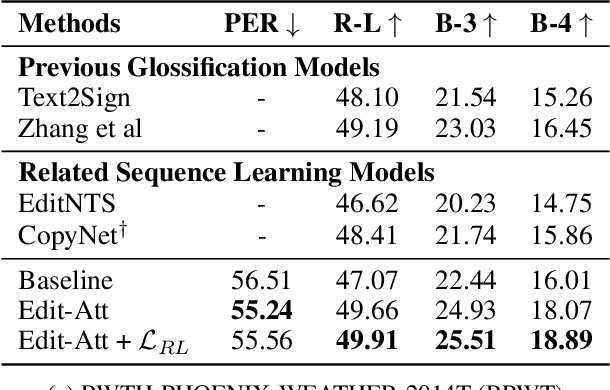
This work studies the task of glossification, of which the aim is to em transcribe natural spoken language sentences for the Deaf (hard-of-hearing) community to ordered sign language glosses. Previous sequence-to-sequence language models trained with paired sentence-gloss data often fail to capture the rich connections between the two distinct languages, leading to unsatisfactory transcriptions. We observe that despite different grammars, glosses effectively simplify sentences for the ease of deaf communication, while sharing a large portion of vocabulary with sentences. This has motivated us to implement glossification by executing a collection of editing actions, e.g. word addition, deletion, and copying, called editing programs, on their natural spoken language counterparts. Specifically, we design a new neural agent that learns to synthesize and execute editing programs, conditioned on sentence contexts and partial editing results. The agent is trained to imitate minimal editing programs, while exploring more widely the program space via policy gradients to optimize sequence-wise transcription quality. Results show that our approach outperforms previous glossification models by a large margin.
Enhancing Clinical Information Extraction with Transferred Contextual Embeddings
Sep 22, 2021
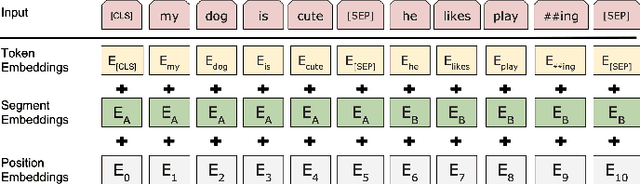
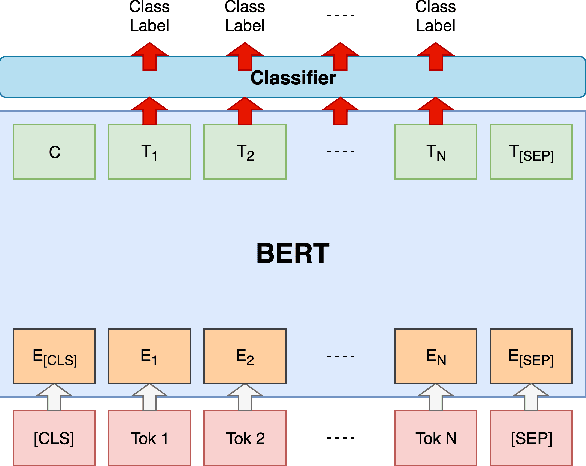
The Bidirectional Encoder Representations from Transformers (BERT) model has achieved the state-of-the-art performance for many natural language processing (NLP) tasks. Yet, limited research has been contributed to studying its effectiveness when the target domain is shifted from the pre-training corpora, for example, for biomedical or clinical NLP applications. In this paper, we applied it to a widely studied a hospital information extraction (IE) task and analyzed its performance under the transfer learning setting. Our application became the new state-of-the-art result by a clear margin, compared with a range of existing IE models. Specifically, on this nursing handover data set, the macro-average F1 score from our model was 0.438, whilst the previous best deep learning models had 0.416. In conclusion, we showed that BERT based pre-training models can be transferred to health-related documents under mild conditions and with a proper fine-tuning process.
Humanly Certifying Superhuman Classifiers
Sep 16, 2021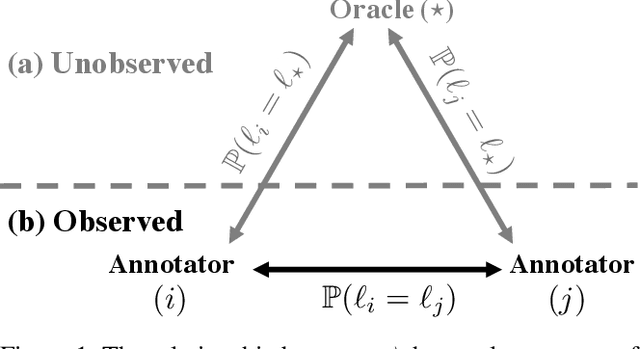
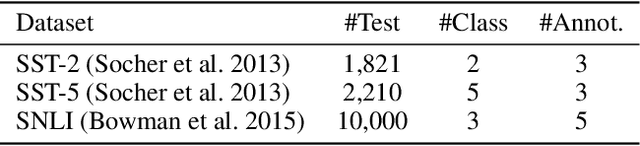
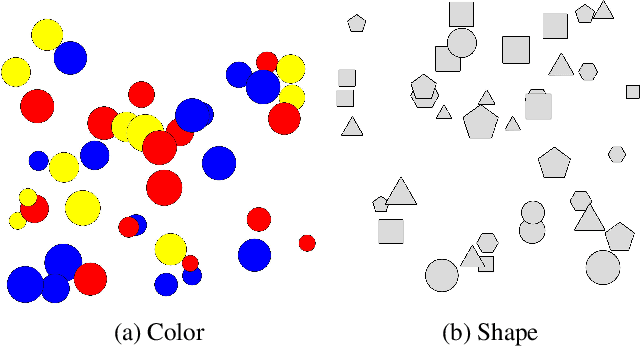
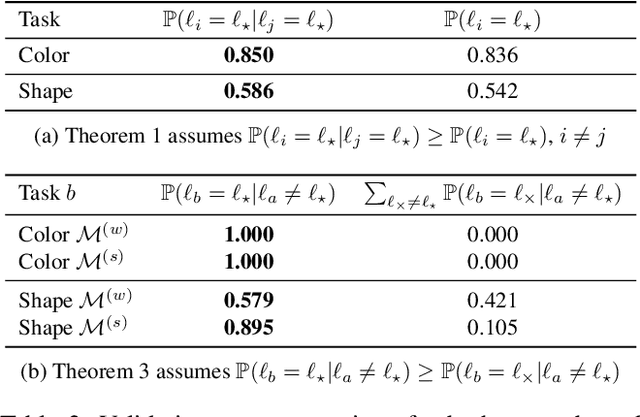
Estimating the performance of a machine learning system is a longstanding challenge in artificial intelligence research. Today, this challenge is especially relevant given the emergence of systems which appear to increasingly outperform human beings. In some cases, this "superhuman" performance is readily demonstrated; for example by defeating legendary human players in traditional two player games. On the other hand, it can be challenging to evaluate classification models that potentially surpass human performance. Indeed, human annotations are often treated as a ground truth, which implicitly assumes the superiority of the human over any models trained on human annotations. In reality, human annotators can make mistakes and be subjective. Evaluating the performance with respect to a genuine oracle may be more objective and reliable, even when querying the oracle is expensive or impossible. In this paper, we first raise the challenge of evaluating the performance of both humans and models with respect to an oracle which is unobserved. We develop a theory for estimating the accuracy compared to the oracle, using only imperfect human annotations for reference. Our analysis provides a simple recipe for detecting and certifying superhuman performance in this setting, which we believe will assist in understanding the stage of current research on classification. We validate the convergence of the bounds and the assumptions of our theory on carefully designed toy experiments with known oracles. Moreover, we demonstrate the utility of our theory by meta-analyzing large-scale natural language processing tasks, for which an oracle does not exist, and show that under our assumptions a number of models from recent years are with high probability superhuman.
Analyzing the Granularity and Cost of Annotation in Clinical Sequence Labeling
Aug 23, 2021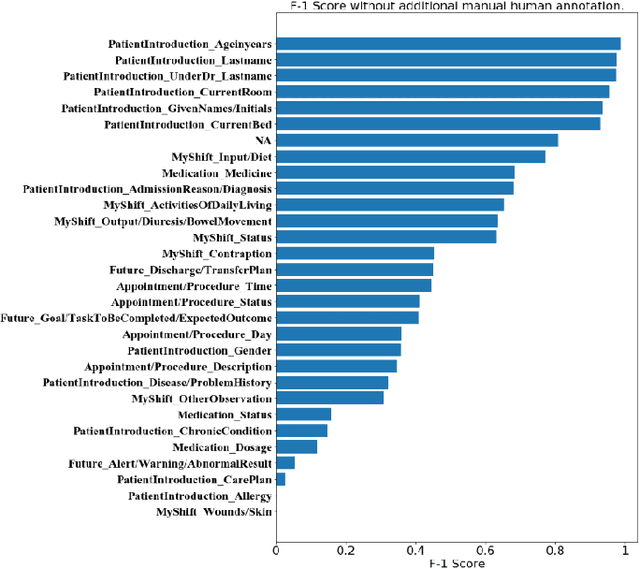
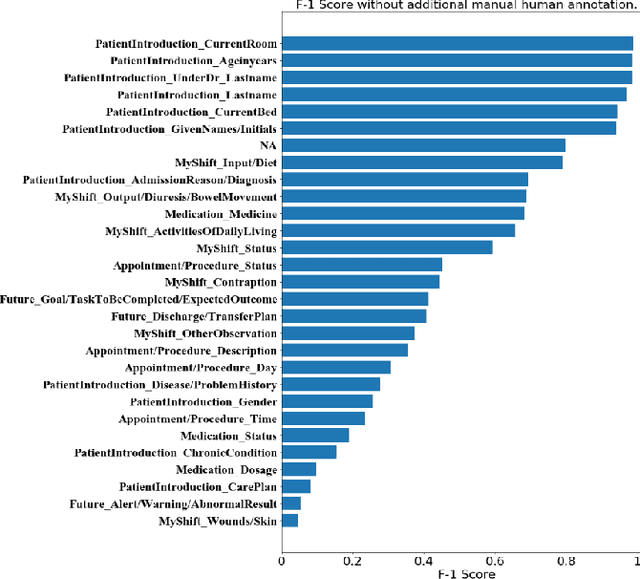
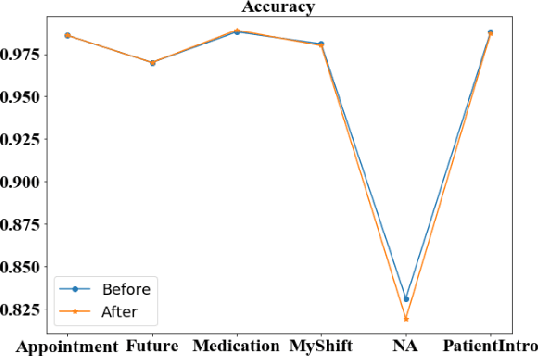
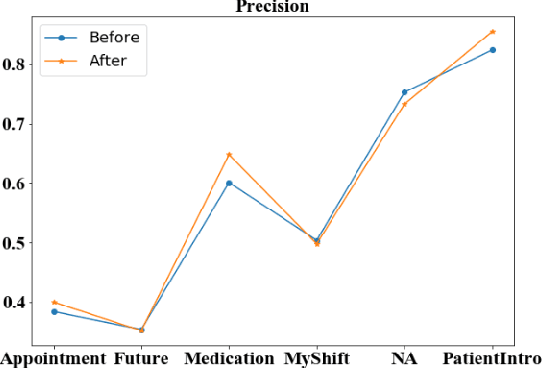
Well-annotated datasets, as shown in recent top studies, are becoming more important for researchers than ever before in supervised machine learning (ML). However, the dataset annotation process and its related human labor costs remain overlooked. In this work, we analyze the relationship between the annotation granularity and ML performance in sequence labeling, using clinical records from nursing shift-change handover. We first study a model derived from textual language features alone, without additional information based on nursing knowledge. We find that this sequence tagger performs well in most categories under this granularity. Then, we further include the additional manual annotations by a nurse, and find the sequence tagging performance remaining nearly the same. Finally, we give a guideline and reference to the community arguing it is not necessary and even not recommended to annotate in detailed granularity because of a low Return on Investment. Therefore we recommend emphasizing other features, like textual knowledge, for researchers and practitioners as a cost-effective source for increasing the sequence labeling performance.