 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Mechanisms of Collaborative Learning in VAE Recommenders
Nov 10, 2025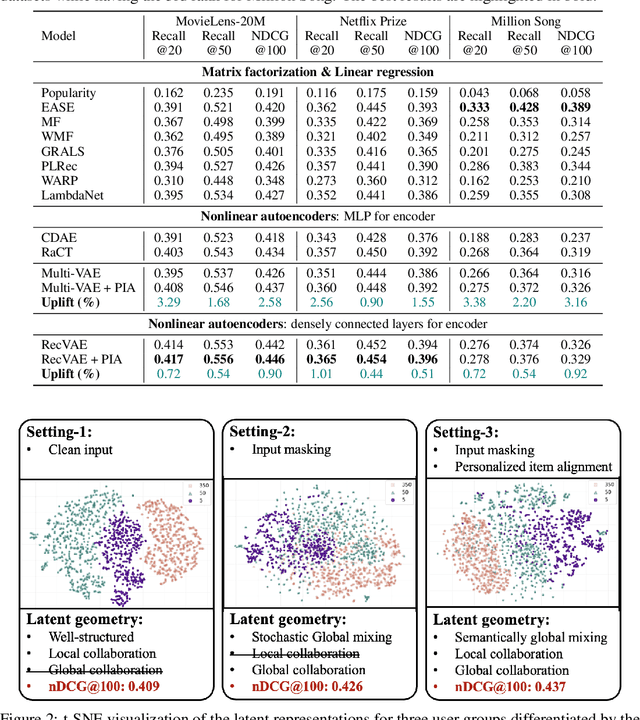
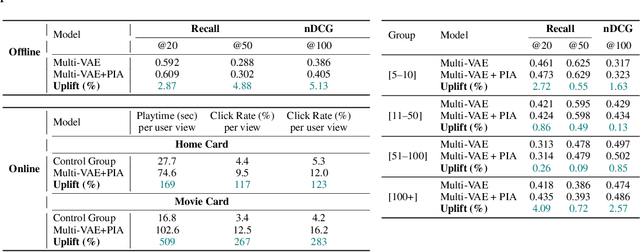

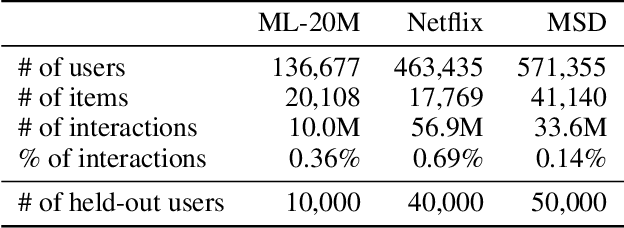
Variational Autoencoders (VAEs) are a powerful alternative to matrix factorization for recommendation. A common technique in VAE-based collaborative filtering (CF) consists in applying binary input masking to user interaction vectors, which improves performance but remains underexplored theoretically. In this work, we analyze how collaboration arises in VAE-based CF and show it is governed by latent proximity: we derive a latent sharing radius that informs when an SGD update on one user strictly reduces the loss on another user, with influence decaying as the latent Wasserstein distance increases. We further study the induced geometry: with clean inputs, VAE-based CF primarily exploits \emph{local} collaboration between input-similar users and under-utilizes global collaboration between far-but-related users. We compare two mechanisms that encourage \emph{global} mixing and characterize their trade-offs: (1) $β$-KL regularization directly tightens the information bottleneck, promoting posterior overlap but risking representational collapse if too large; (2) input masking induces stochastic geometric contractions and expansions, which can bring distant users onto the same latent neighborhood but also introduce neighborhood drift. To preserve user identity while enabling global consistency, we propose an anchor regularizer that aligns user posteriors with item embeddings, stabilizing users under masking and facilitating signal sharing across related items. Our analyses are validated on the Netflix, MovieLens-20M, and Million Song datasets. We also successfully deployed our proposed algorithm on an Amazon streaming platform following a successful online experiment.
Learning Visual Hierarchies with Hyperbolic Embeddings
Nov 26, 2024Structuring latent representations in a hierarchical manner enables models to learn patterns at multiple levels of abstraction. However, most prevalent image understanding models focus on visual similarity, and learning visual hierarchies is relatively unexplored. In this work, for the first time, we introduce a learning paradigm that can encode user-defined multi-level visual hierarchies in hyperbolic space without requiring explicit hierarchical labels. As a concrete example, first, we define a part-based image hierarchy using object-level annotations within and across images. Then, we introduce an approach to enforce the hierarchy using contrastive loss with pairwise entailment metrics. Finally, we discuss new evaluation metrics to effectively measure hierarchical image retrieval. Encoding these complex relationships ensures that the learned representations capture semantic and structural information that transcends mere visual similarity. Experiments in part-based image retrieval show significant improvements in hierarchical retrieval tasks, demonstrating the capability of our model in capturing visual hierarchies.
Geometric Collaborative Filtering with Convergence
Oct 04, 2024
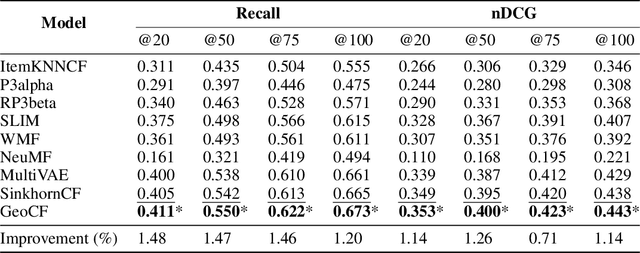
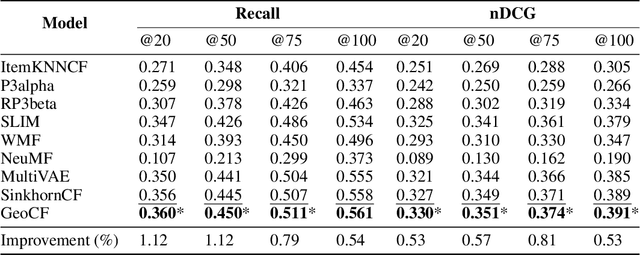

Latent variable collaborative filtering methods have been a standard approach to modelling user-click interactions due to their simplicity and effectiveness. However, there is limited work on analyzing the mathematical properties of these methods in particular on preventing the overfitting towards the identity, and such methods typically utilize loss functions that overlook the geometry between items. In this work, we introduce a notion of generalization gap in collaborative filtering and analyze this with respect to latent collaborative filtering models. We present a geometric upper bound that gives rise to loss functions, and a way to meaningfully utilize the geometry of item-metadata to improve recommendations. We show how these losses can be minimized and gives the recipe to a new latent collaborative filtering algorithm, which we refer to as GeoCF, due to the geometric nature of our results. We then show experimentally that our proposed GeoCF algorithm can outperform other all existing methods on the Movielens20M and Netflix datasets, as well as two large-scale internal datasets. In summary, our work proposes a theoretically sound method which paves a way to better understand generalization of collaborative filtering at large.
MARec: Metadata Alignment for cold-start Recommendation
Apr 20, 2024


For many recommender systems the primary data source is a historical record of user clicks. The associated click matrix which is often very sparse, however, as the number of users x products can be far larger than the number of clicks, and such sparsity is accentuated in cold-start settings. The sparsity of the click matrix is the reason matrix factorization and autoencoders techniques remain highly competitive across collaborative filtering datasets. In this work, we propose a simple approach to address cold-start recommendations by leveraging content metadata, Metadata Alignment for cold-start Recommendation. we show that this approach can readily augment existing matrix factorization and autoencoder approaches, enabling a smooth transition to top performing algorithms in warmer set-ups. Our experimental results indicate three separate contributions: first, we show that our proposed framework largely beats SOTA results on 4 cold-start datasets with different sparsity and scale characteristics, with gains ranging from +8.4% to +53.8% on reported ranking metrics; second, we provide an ablation study on the utility of semantic features, and proves the additional gain obtained by leveraging such features ranges between +46.8% and +105.5%; and third, our approach is by construction highly competitive in warm set-ups, and we propose a closed-form solution outperformed by SOTA results by only 0.8% on average.
Deep Learning to Scale up Time Series Traffic Prediction
Nov 29, 2019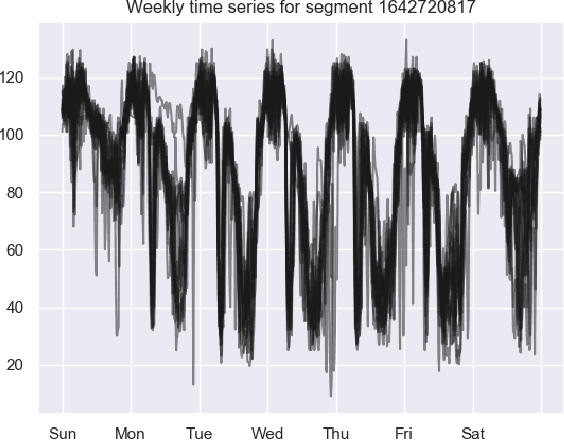
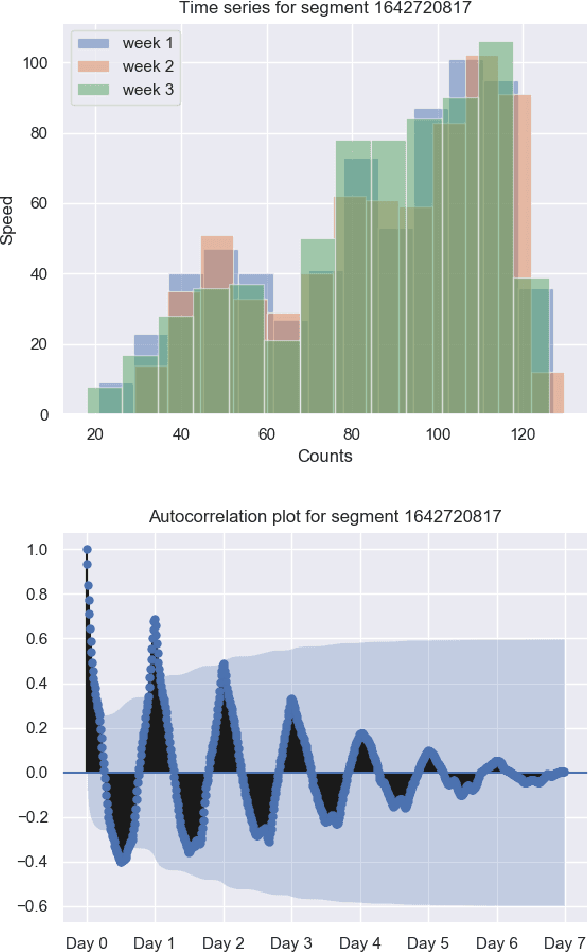
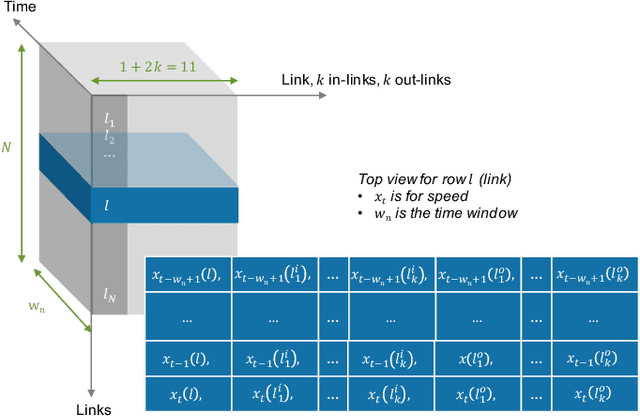
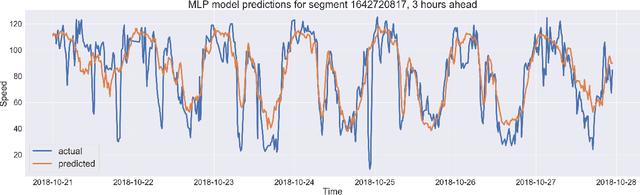
The transport literature is dense regarding short-term traffic predictions, up to the scale of 1 hour, yet less dense for long-term traffic predictions. The transport literature is also sparse when it comes to city-scale traffic predictions, mainly because of low data availability. The main question we try to answer in this work is to which extent the approaches used for short-term prediction at a link level can be scaled up for long-term prediction at a city scale. We investigate a city-scale traffic dataset with 14 weeks of speed observations collected every 15 minutes over 1098 segments in the hypercenter of Los Angeles, California. We look at a variety of machine learning and deep learning predictors for link-based predictions, and investigate ways to make such predictors scale up for larger areas, with brute force, clustering, and model design approaches. In particular we propose a novel deep learning spatio-temporal predictor inspired from recent works on recommender systems. We discuss the potential of including spatio-temporal features into the predictors, and conclude that modelling such features can be helpful for long-term predictions, while simpler predictors achieve very satisfactory performance for link-based and short-term forecasting. The trade-off is discussed not only in terms of prediction accuracy vs prediction horizon but also in terms of training time and model sizing.
Scaling up Deep Learning for PDE-based Models
Oct 22, 2018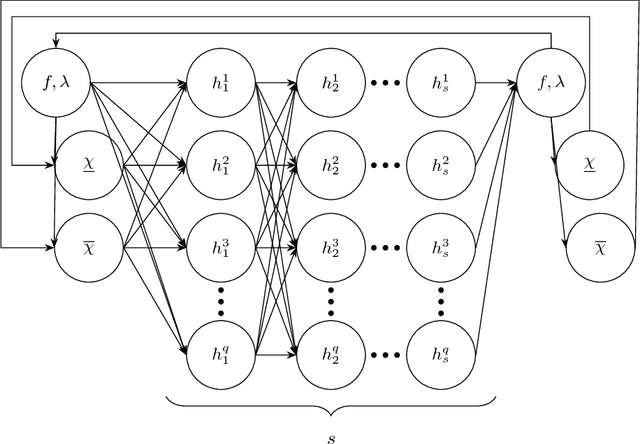
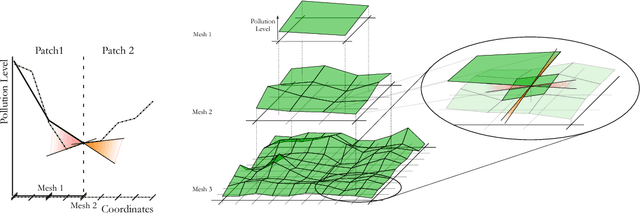
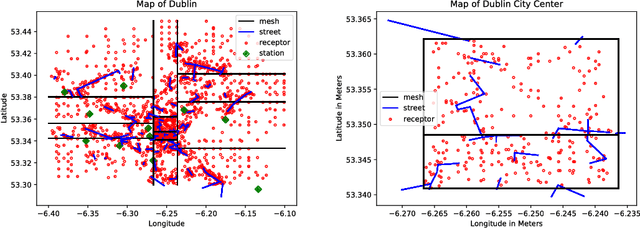
In numerous applications, forecasting relies on numerical solvers for partial differential equations (PDEs). Although the use of deep-learning techniques has been proposed, the uses have been restricted by the fact the training data are obtained using PDE solvers. Thereby, the uses were limited to domains, where the PDE solver was applicable, but no further. We present methods for training on small domains, while applying the trained models on larger domains, with consistency constraints ensuring the solutions are physically meaningful even at the boundary of the small domains. We demonstrate the results on an air-pollution forecasting model for Dublin, Ireland.
Bayesian Classifier for Route Prediction with Markov Chains
Aug 31, 2018
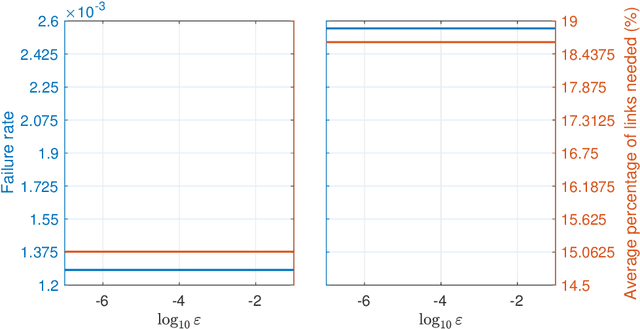
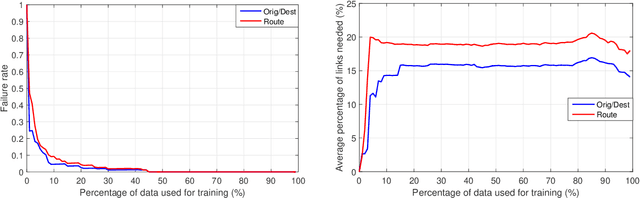
We present here a general framework and a specific algorithm for predicting the destination, route, or more generally a pattern, of an ongoing journey, building on the recent work of [Y. Lassoued, J. Monteil, Y. Gu, G. Russo, R. Shorten, and M. Mevissen, "Hidden Markov model for route and destination prediction," in IEEE International Conference on Intelligent Transportation Systems, 2017]. In the presented framework, known journey patterns are modelled as stochastic processes, emitting the road segments visited during the journey, and the ongoing journey is predicted by updating the posterior probability of each journey pattern given the road segments visited so far. In this contribution, we use Markov chains as models for the journey patterns, and consider the prediction as final, once one of the posterior probabilities crosses a predefined threshold. Despite the simplicity of both, examples run on a synthetic dataset demonstrate high accuracy of the made predictions.