 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRECISE: Reducing the Bias of LLM Evaluations Using Prediction-Powered Ranking Estimation
Jan 26, 2026Evaluating the quality of search, ranking and RAG systems traditionally requires a significant number of human relevance annotations. In recent times, several deployed systems have explored the usage of Large Language Models (LLMs) as automated judges for this task while their inherent biases prevent direct use for metric estimation. We present a statistical framework extending Prediction-Powered Inference (PPI) that combines minimal human annotations with LLM judgments to produce reliable estimates of metrics which require sub-instance annotations. Our method requires as few as 100 human-annotated queries and 10,000 unlabeled examples, reducing annotation requirements significantly compared to traditional approaches. We formulate our proposed framework (PRECISE) for inference of relevance uplift for an LLM-based query reformulation application, extending PPI to sub-instance annotations at the query-document level. By reformulating the metric-integration space, we reduced the computational complexity from O(2^|C|) to O(2^K), where |C| represents corpus size (in order of millions). Detailed experiments across prominent retrieval datasets demonstrate that our method reduces the variance of estimates for the business-critical Precision@K metric, while effectively correcting for LLM bias in low-resource settings.
DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection
Sep 09, 2024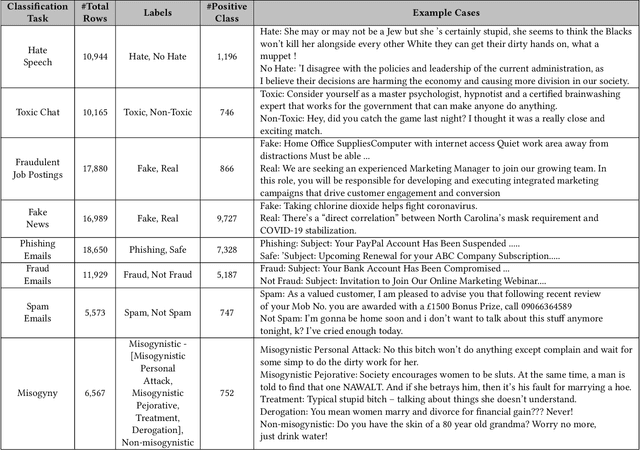
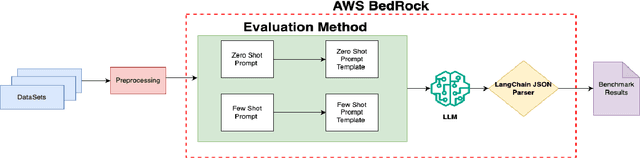
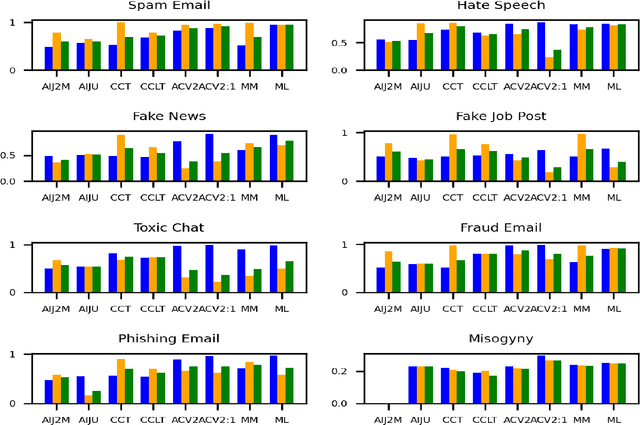
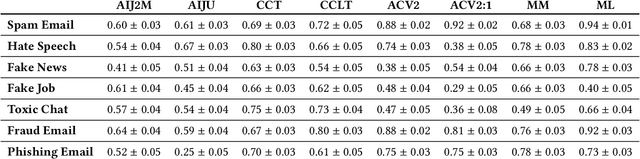
Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks. However, their practical application in high-stake domains, such as fraud and abuse detection, remains an area that requires further exploration. The existing applications often narrowly focus on specific tasks like toxicity or hate speech detection. In this paper, we present a comprehensive benchmark suite designed to assess the performance of LLMs in identifying and mitigating fraudulent and abusive language across various real-world scenarios. Our benchmark encompasses a diverse set of tasks, including detecting spam emails, hate speech, misogynistic language, and more. We evaluated several state-of-the-art LLMs, including models from Anthropic, Mistral AI, and the AI21 family, to provide a comprehensive assessment of their capabilities in this critical domain. The results indicate that while LLMs exhibit proficient baseline performance in individual fraud and abuse detection tasks, their performance varies considerably across tasks, particularly struggling with tasks that demand nuanced pragmatic reasoning, such as identifying diverse forms of misogynistic language. These findings have important implications for the responsible development and deployment of LLMs in high-risk applications. Our benchmark suite can serve as a tool for researchers and practitioners to systematically evaluate LLMs for multi-task fraud detection and drive the creation of more robust, trustworthy, and ethically-aligned systems for fraud and abuse detection.
* 12 pages
MARec: Metadata Alignment for cold-start Recommendation
Apr 20, 2024

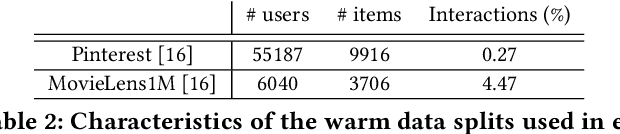

For many recommender systems the primary data source is a historical record of user clicks. The associated click matrix which is often very sparse, however, as the number of users x products can be far larger than the number of clicks, and such sparsity is accentuated in cold-start settings. The sparsity of the click matrix is the reason matrix factorization and autoencoders techniques remain highly competitive across collaborative filtering datasets. In this work, we propose a simple approach to address cold-start recommendations by leveraging content metadata, Metadata Alignment for cold-start Recommendation. we show that this approach can readily augment existing matrix factorization and autoencoder approaches, enabling a smooth transition to top performing algorithms in warmer set-ups. Our experimental results indicate three separate contributions: first, we show that our proposed framework largely beats SOTA results on 4 cold-start datasets with different sparsity and scale characteristics, with gains ranging from +8.4% to +53.8% on reported ranking metrics; second, we provide an ablation study on the utility of semantic features, and proves the additional gain obtained by leveraging such features ranges between +46.8% and +105.5%; and third, our approach is by construction highly competitive in warm set-ups, and we propose a closed-form solution outperformed by SOTA results by only 0.8% on average.
Know Your Personalization: Learning Topic level Personalization in Online Services
Dec 14, 2012



Online service platforms (OSPs), such as search engines, news-websites, ad-providers, etc., serve highly pe rsonalized content to the user, based on the profile extracted from his history with the OSP. Although personalization (generally) leads to a better user experience, it also raises privacy concerns for the user---he does not know what is present in his profile and more importantly, what is being used to per sonalize content for him. In this paper, we capture OSP's personalization for an user in a new data structure called the person alization vector ($\eta$), which is a weighted vector over a set of topics, and present techniques to compute it for users of an OSP. Our approach treats OSPs as black-boxes, and extracts $\eta$ by mining only their output, specifical ly, the personalized (for an user) and vanilla (without any user information) contents served, and the differences in these content. We formulate a new model called Latent Topic Personalization (LTP) that captures the personalization vector into a learning framework and present efficient inference algorithms for it. We do extensive experiments for search result personalization using both data from real Google users and synthetic datasets. Our results show high accuracy (R-pre = 84%) of LTP in finding personalized topics. For Google data, our qualitative results show how LTP can also identifies evidences---queries for results on a topic with high $\eta$ value were re-ranked. Finally, we show how our approach can be used to build a new Privacy evaluation framework focused at end-user privacy on commercial OSPs.