 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOstrakon-VL: Towards Domain-Expert MLLM for Food-Service and Retail Stores
Jan 29, 2026Multimodal Large Language Models (MLLMs) have recently achieved substantial progress in general-purpose perception and reasoning. Nevertheless, their deployment in Food-Service and Retail Stores (FSRS) scenarios encounters two major obstacles: (i) real-world FSRS data, collected from heterogeneous acquisition devices, are highly noisy and lack auditable, closed-loop data curation, which impedes the construction of high-quality, controllable, and reproducible training corpora; and (ii) existing evaluation protocols do not offer a unified, fine-grained and standardized benchmark spanning single-image, multi-image, and video inputs, making it challenging to objectively gauge model robustness. To address these challenges, we first develop Ostrakon-VL, an FSRS-oriented MLLM based on Qwen3-VL-8B. Second, we introduce ShopBench, the first public benchmark for FSRS. Third, we propose QUAD (Quality-aware Unbiased Automated Data-curation), a multi-stage multimodal instruction data curation pipeline. Leveraging a multi-stage training strategy, Ostrakon-VL achieves an average score of 60.1 on ShopBench, establishing a new state of the art among open-source MLLMs with comparable parameter scales and diverse architectures. Notably, it surpasses the substantially larger Qwen3-VL-235B-A22B (59.4) by +0.7, and exceeds the same-scale Qwen3-VL-8B (55.3) by +4.8, demonstrating significantly improved parameter efficiency. These results indicate that Ostrakon-VL delivers more robust and reliable FSRS-centric perception and decision-making capabilities. To facilitate reproducible research, we will publicly release Ostrakon-VL and the ShopBench benchmark.
Multi-Constrained Evolutionary Molecular Design Framework: An Interpretable Drug Design Method Combining Rule-Based Evolution and Molecular Crossover
Jan 15, 2026This study proposes MCEMOL (Multi-Constrained Evolutionary Molecular Design Framework), a molecular optimization approach integrating rule-based evolution with molecular crossover. MCEMOL employs dual-layer evolution: optimizing transformation rules at rule level while applying crossover and mutation to molecular structures. Unlike deep learning methods requiring large datasets and extensive training, our algorithm evolves efficiently from minimal starting molecules with low computational overhead. The framework incorporates message-passing neural networks and comprehensive chemical constraints, ensuring efficient and interpretable molecular design. Experimental results demonstrate that MCEMOL provides transparent design pathways through its evolutionary mechanism while generating valid, diverse, target-compliant molecules. The framework achieves 100% molecular validity with high structural diversity and excellent drug-likeness compliance, showing strong performance in symmetry constraints, pharmacophore optimization, and stereochemical integrity. Unlike black-box methods, MCEMOL delivers dual value: interpretable transformation rules researchers can understand and trust, alongside high-quality molecular libraries for practical applications. This establishes a paradigm where interpretable AI-driven drug design and effective molecular generation are achieved simultaneously, bridging the gap between computational innovation and practical drug discovery needs.
Talk2Move: Reinforcement Learning for Text-Instructed Object-Level Geometric Transformation in Scenes
Jan 08, 2026We introduce Talk2Move, a reinforcement learning (RL) based diffusion framework for text-instructed spatial transformation of objects within scenes. Spatially manipulating objects in a scene through natural language poses a challenge for multimodal generation systems. While existing text-based manipulation methods can adjust appearance or style, they struggle to perform object-level geometric transformations-such as translating, rotating, or resizing objects-due to scarce paired supervision and pixel-level optimization limits. Talk2Move employs Group Relative Policy Optimization (GRPO) to explore geometric actions through diverse rollouts generated from input images and lightweight textual variations, removing the need for costly paired data. A spatial reward guided model aligns geometric transformations with linguistic description, while off-policy step evaluation and active step sampling improve learning efficiency by focusing on informative transformation stages. Furthermore, we design object-centric spatial rewards that evaluate displacement, rotation, and scaling behaviors directly, enabling interpretable and coherent transformations. Experiments on curated benchmarks demonstrate that Talk2Move achieves precise, consistent, and semantically faithful object transformations, outperforming existing text-guided editing approaches in both spatial accuracy and scene coherence.
Experience-Guided Adaptation of Inference-Time Reasoning Strategies
Nov 14, 2025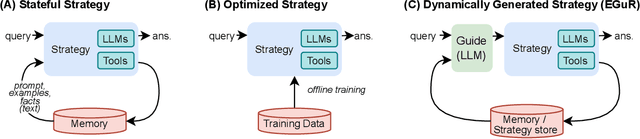
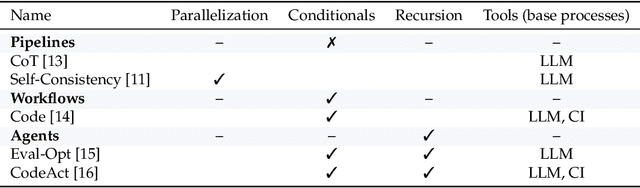

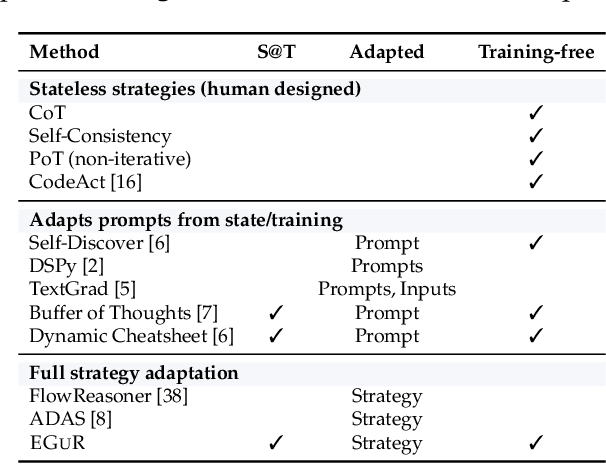
Enabling agentic AI systems to adapt their problem-solving approaches based on post-training interactions remains a fundamental challenge. While systems that update and maintain a memory at inference time have been proposed, existing designs only steer the system by modifying textual input to a language model or agent, which means that they cannot change sampling parameters, remove tools, modify system prompts, or switch between agentic and workflow paradigms. On the other hand, systems that adapt more flexibly require offline optimization and remain static once deployed. We present Experience-Guided Reasoner (EGuR), which generates tailored strategies -- complete computational procedures involving LLM calls, tools, sampling parameters, and control logic -- dynamically at inference time based on accumulated experience. We achieve this using an LLM-based meta-strategy -- a strategy that outputs strategies -- enabling adaptation of all strategy components (prompts, sampling parameters, tool configurations, and control logic). EGuR operates through two components: a Guide generates multiple candidate strategies conditioned on the current problem and structured memory of past experiences, while a Consolidator integrates execution feedback to improve future strategy generation. This produces complete, ready-to-run strategies optimized for each problem, which can be cached, retrieved, and executed as needed without wasting resources. Across five challenging benchmarks (AIME 2025, 3-SAT, and three Big Bench Extra Hard tasks), EGuR achieves up to 14% accuracy improvements over the strongest baselines while reducing computational costs by up to 111x, with both metrics improving as the system gains experience.
Learning to Focus: Focal Attention for Selective and Scalable Transformers
Nov 10, 2025Attention is a core component of transformer architecture, whether encoder-only, decoder-only, or encoder-decoder model. However, the standard softmax attention often produces noisy probability distribution, which can impair effective feature selection at every layer of these models, particularly for long contexts. We propose Focal Attention, a simple yet effective modification that sharpens the attention distribution by controlling the softmax temperature, either as a fixed hyperparameter or as a learnable parameter during training. This sharpening enables the model to concentrate on the most relevant tokens while suppressing irrelevant ones. Empirically, Focal Attention scales more favorably than standard transformer with respect to model size, training data, and context length. Across diverse benchmarks, it achieves the same accuracy with up to 42% fewer parameters or 33% less training data. On long-context tasks, it delivers substantial relative improvements ranging from 17% to 82%, demonstrating its effectiveness in real world applications.
e1: Learning Adaptive Control of Reasoning Effort
Oct 30, 2025Increasing the thinking budget of AI models can significantly improve accuracy, but not all questions warrant the same amount of reasoning. Users may prefer to allocate different amounts of reasoning effort depending on how they value output quality versus latency and cost. To leverage this tradeoff effectively, users need fine-grained control over the amount of thinking used for a particular query, but few approaches enable such control. Existing methods require users to specify the absolute number of desired tokens, but this requires knowing the difficulty of the problem beforehand to appropriately set the token budget for a query. To address these issues, we propose Adaptive Effort Control, a self-adaptive reinforcement learning method that trains models to use a user-specified fraction of tokens relative to the current average chain-of-thought length for each query. This approach eliminates dataset- and phase-specific tuning while producing better cost-accuracy tradeoff curves compared to standard methods. Users can dynamically adjust the cost-accuracy trade-off through a continuous effort parameter specified at inference time. We observe that the model automatically learns to allocate resources proportionally to the task difficulty and, across model scales ranging from 1.5B to 32B parameters, our approach enables approximately 3x reduction in chain-of-thought length while maintaining or improving performance relative to the base model used for RL training.
Maximally-Informative Retrieval for State Space Model Generation
Jun 13, 2025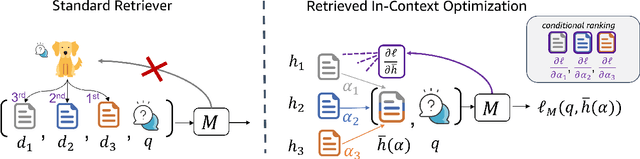
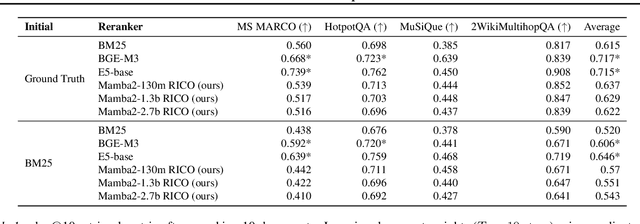
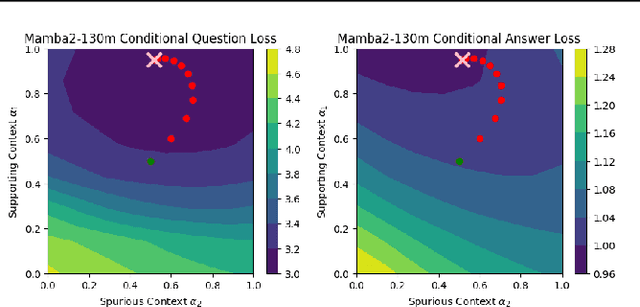
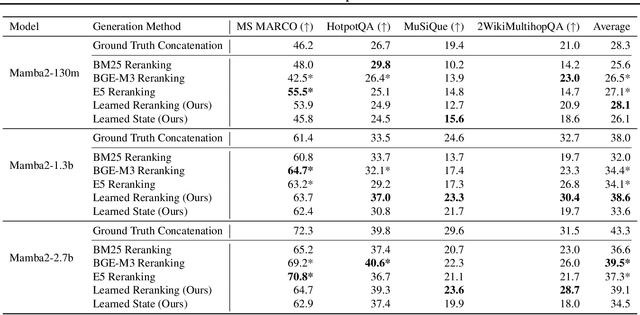
Given a query and dataset, the optimal way of answering the query is to make use all the information available. Modern LLMs exhibit impressive ability to memorize training data, but data not deemed important during training is forgotten, and information outside that training set cannot be made use of. Processing an entire dataset at inference time is infeasible due to the bounded nature of model resources (e.g. context size in transformers or states in state space models), meaning we must resort to external memory. This constraint naturally leads to the following problem: How can we decide based on the present query and model, what among a virtually unbounded set of known data matters for inference? To minimize model uncertainty for a particular query at test-time, we introduce Retrieval In-Context Optimization (RICO), a retrieval method that uses gradients from the LLM itself to learn the optimal mixture of documents for answer generation. Unlike traditional retrieval-augmented generation (RAG), which relies on external heuristics for document retrieval, our approach leverages direct feedback from the model. Theoretically, we show that standard top-$k$ retrieval with model gradients can approximate our optimization procedure, and provide connections to the leave-one-out loss. We demonstrate empirically that by minimizing an unsupervised loss objective in the form of question perplexity, we can achieve comparable retriever metric performance to BM25 with \emph{no finetuning}. Furthermore, when evaluated on quality of the final prediction, our method often outperforms fine-tuned dense retrievers such as E5.
Respond to Change with Constancy: Instruction-tuning with LLM for Non-I.I.D. Network Traffic Classification
May 27, 2025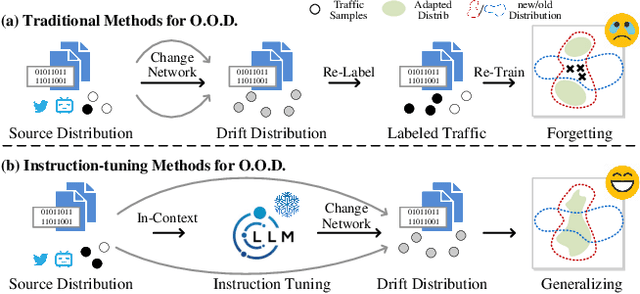
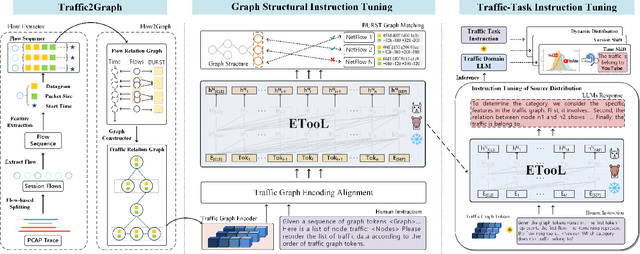
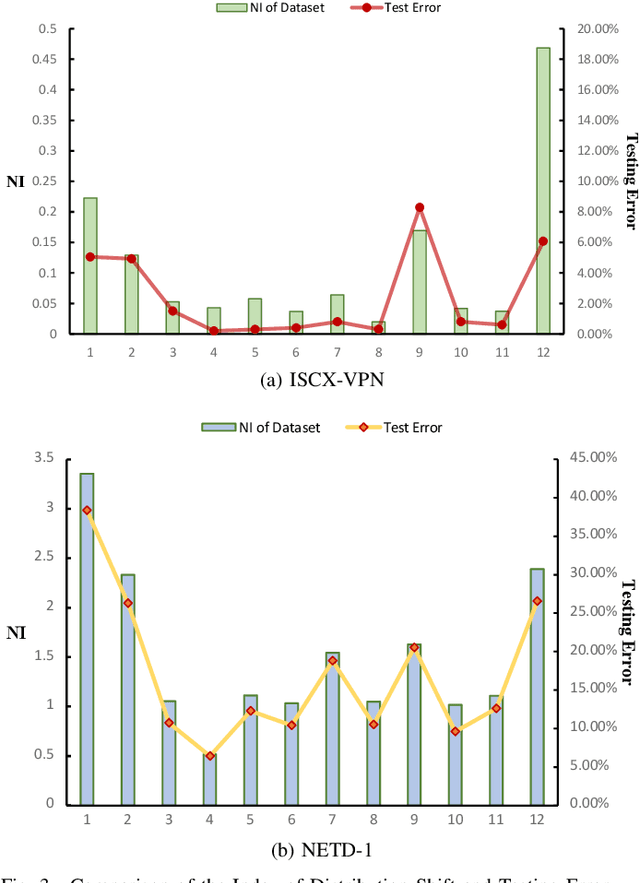
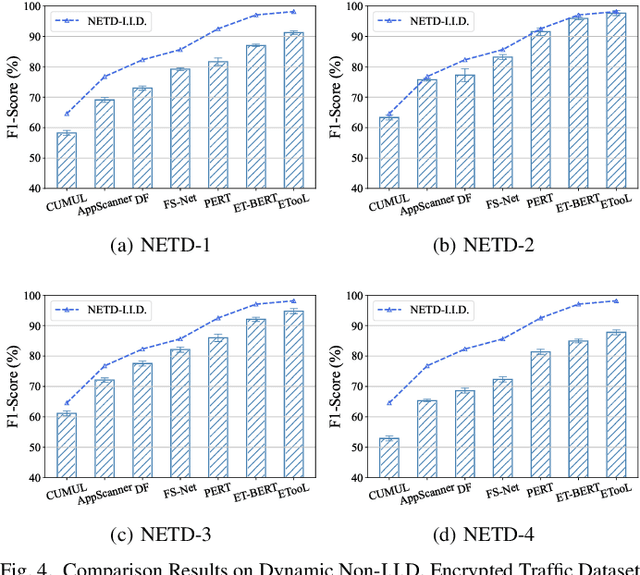
Encrypted traffic classification is highly challenging in network security due to the need for extracting robust features from content-agnostic traffic data. Existing approaches face critical issues: (i) Distribution drift, caused by reliance on the closedworld assumption, limits adaptability to realworld, shifting patterns; (ii) Dependence on labeled data restricts applicability where such data is scarce or unavailable. Large language models (LLMs) have demonstrated remarkable potential in offering generalizable solutions across a wide range of tasks, achieving notable success in various specialized fields. However, their effectiveness in traffic analysis remains constrained by challenges in adapting to the unique requirements of the traffic domain. In this paper, we introduce a novel traffic representation model named Encrypted Traffic Out-of-Distribution Instruction Tuning with LLM (ETooL), which integrates LLMs with knowledge of traffic structures through a self-supervised instruction tuning paradigm. This framework establishes connections between textual information and traffic interactions. ETooL demonstrates more robust classification performance and superior generalization in both supervised and zero-shot traffic classification tasks. Notably, it achieves significant improvements in F1 scores: APP53 (I.I.D.) to 93.19%(6.62%) and 92.11%(4.19%), APP53 (O.O.D.) to 74.88%(18.17%) and 72.13%(15.15%), and ISCX-Botnet (O.O.D.) to 95.03%(9.16%) and 81.95%(12.08%). Additionally, we construct NETD, a traffic dataset designed to support dynamic distributional shifts, and use it to validate ETooL's effectiveness under varying distributional conditions. Furthermore, we evaluate the efficiency gains achieved through ETooL's instruction tuning approach.
AdvKT: An Adversarial Multi-Step Training Framework for Knowledge Tracing
Apr 07, 2025Knowledge Tracing (KT) monitors students' knowledge states and simulates their responses to question sequences. Existing KT models typically follow a single-step training paradigm, which leads to discrepancies with the multi-step inference process required in real-world simulations, resulting in significant error accumulation. This accumulation of error, coupled with the issue of data sparsity, can substantially degrade the performance of recommendation models in the intelligent tutoring systems. To address these challenges, we propose a novel Adversarial Multi-Step Training Framework for Knowledge Tracing (AdvKT), which, for the first time, focuses on the multi-step KT task. More specifically, AdvKT leverages adversarial learning paradigm involving a generator and a discriminator. The generator mimics high-reward responses, effectively reducing error accumulation across multiple steps, while the discriminator provides feedback to generate synthetic data. Additionally, we design specialized data augmentation techniques to enrich the training data with realistic variations, ensuring that the model generalizes well even in scenarios with sparse data. Experiments conducted on four real-world datasets demonstrate the superiority of AdvKT over existing KT models, showcasing its ability to address both error accumulation and data sparsity issues effectively.
Expansion Span: Combining Fading Memory and Retrieval in Hybrid State Space Models
Dec 17, 2024



The "state" of State Space Models (SSMs) represents their memory, which fades exponentially over an unbounded span. By contrast, Attention-based models have "eidetic" (i.e., verbatim, or photographic) memory over a finite span (context size). Hybrid architectures combine State Space layers with Attention, but still cannot recall the distant past and can access only the most recent tokens eidetically. Unlike current methods of combining SSM and Attention layers, we allow the state to be allocated based on relevancy rather than recency. In this way, for every new set of query tokens, our models can "eidetically" access tokens from beyond the Attention span of current Hybrid SSMs without requiring extra hardware resources. We describe a method to expand the memory span of the hybrid state by "reserving" a fraction of the Attention context for tokens retrieved from arbitrarily distant in the past, thus expanding the eidetic memory span of the overall state. We call this reserved fraction of tokens the "expansion span," and the mechanism to retrieve and aggregate it "Span-Expanded Attention" (SE-Attn). To adapt Hybrid models to using SE-Attn, we propose a novel fine-tuning method that extends LoRA to Hybrid models (HyLoRA) and allows efficient adaptation on long spans of tokens. We show that SE-Attn enables us to efficiently adapt pre-trained Hybrid models on sequences of tokens up to 8 times longer than the ones used for pre-training. We show that HyLoRA with SE-Attn is cheaper and more performant than alternatives like LongLoRA when applied to Hybrid models on natural language benchmarks with long-range dependencies, such as PG-19, RULER, and other common natural language downstream tasks.