 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURPO: A Unified Reward & Policy Optimization Framework for Large Language Models
Jul 23, 2025Large-scale alignment pipelines typically pair a policy model with a separately trained reward model whose parameters remain frozen during reinforcement learning (RL). This separation creates a complex, resource-intensive pipeline and suffers from a performance ceiling due to a static reward signal. We propose a novel framework, Unified Reward & Policy Optimization (URPO), that unifies instruction-following ("player") and reward modeling ("referee") within a single model and a single training phase. Our method recasts all alignment data-including preference pairs, verifiable reasoning, and open-ended instructions-into a unified generative format optimized by a single Group-Relative Policy Optimization (GRPO) loop. This enables the model to learn from ground-truth preferences and verifiable logic while simultaneously generating its own rewards for open-ended tasks. Experiments on the Qwen2.5-7B model demonstrate URPO's superiority. Our unified model significantly outperforms a strong baseline using a separate generative reward model, boosting the instruction-following score on AlpacaEval from 42.24 to 44.84 and the composite reasoning average from 32.66 to 35.66. Furthermore, URPO cultivates a superior internal evaluator as a byproduct of training, achieving a RewardBench score of 85.15 and surpassing the dedicated reward model it replaces (83.55). By eliminating the need for a separate reward model and fostering a co-evolutionary dynamic between generation and evaluation, URPO presents a simpler, more efficient, and more effective path towards robustly aligned language models.
TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
Oct 10, 2024



Current Retrieval-Augmented Generation (RAG) systems concatenate and process numerous retrieved document chunks for prefill which requires a large volume of computation, therefore leading to significant latency in time-to-first-token (TTFT). To reduce the computation overhead as well as TTFT, we introduce TurboRAG, a novel RAG system that redesigns the inference paradigm of the current RAG system by first pre-computing and storing the key-value (KV) caches of documents offline, and then directly retrieving the saved KV cache for prefill. Hence, online computation of KV caches is eliminated during inference. In addition, we provide a number of insights into the mask matrix and positional embedding mechanisms, plus fine-tune a pretrained language model to maintain model accuracy of TurboRAG. Our approach is applicable to most existing large language models and their applications without any requirement in modification of models and inference systems. Experimental results across a suite of RAG benchmarks demonstrate that TurboRAG reduces TTFT by up to 9.4x compared to the conventional RAG systems (on an average of 8.6x), but reserving comparable performance to the standard RAG systems.
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
May 29, 2024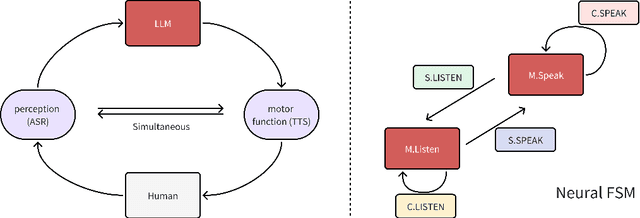


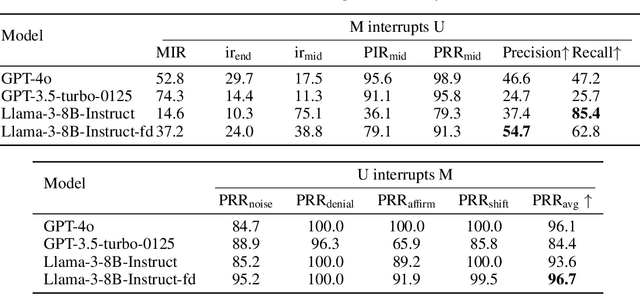
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.