 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinaGS: Scalable Training for Dense Scene Rendering with Billion-Scale 3D Gaussians
Jun 17, 2024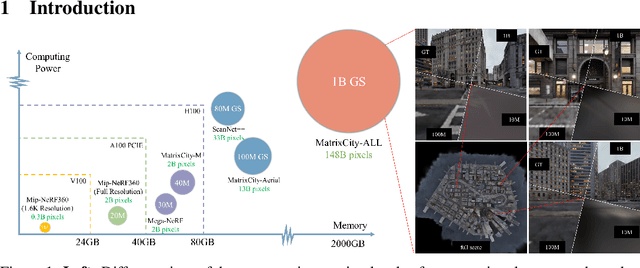


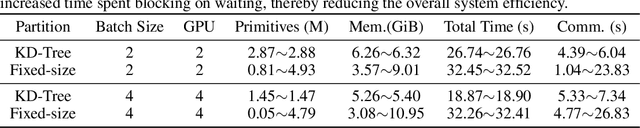
In this work, we explore the possibility of training high-parameter 3D Gaussian splatting (3DGS) models on large-scale, high-resolution datasets. We design a general model parallel training method for 3DGS, named RetinaGS, which uses a proper rendering equation and can be applied to any scene and arbitrary distribution of Gaussian primitives. It enables us to explore the scaling behavior of 3DGS in terms of primitive numbers and training resolutions that were difficult to explore before and surpass previous state-of-the-art reconstruction quality. We observe a clear positive trend of increasing visual quality when increasing primitive numbers with our method. We also demonstrate the first attempt at training a 3DGS model with more than one billion primitives on the full MatrixCity dataset that attains a promising visual quality.
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
May 29, 2024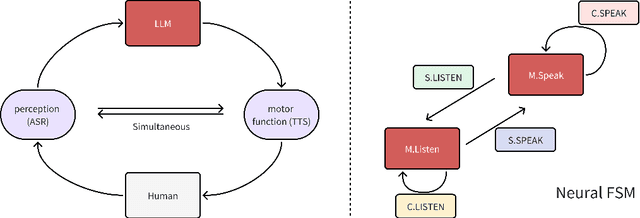


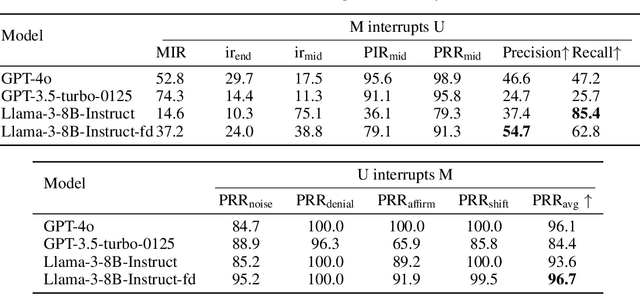
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
Spiral Complete Coverage Path Planning Based on Conformal Slit Mapping in Multi-connected Domains
Sep 19, 2023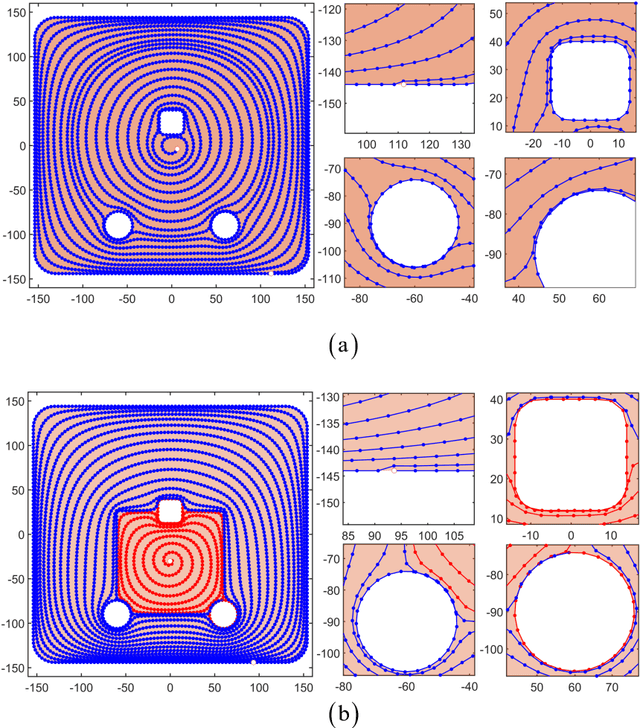

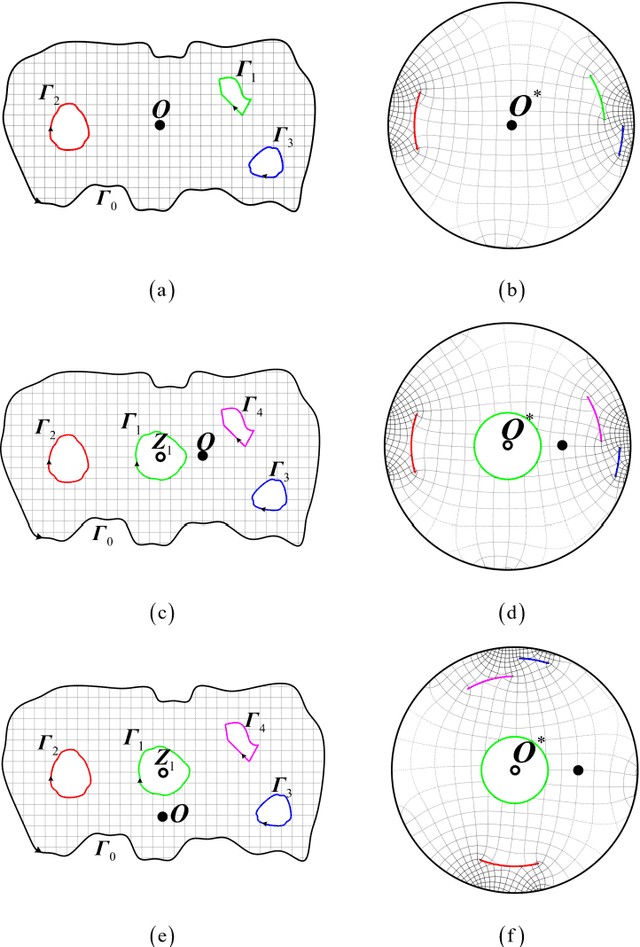
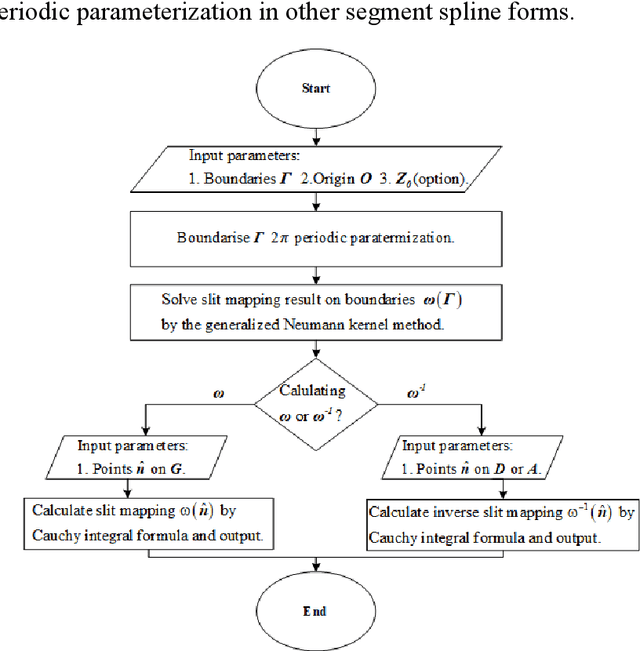
Generating a smooth and shorter spiral complete coverage path in a multi-connected domain is an important research area in robotic cavity machining. Traditional spiral path planning methods in multi-connected domains involve a subregion division procedure; a deformed spiral path is incorporated within each subregion, and these paths within the subregions are interconnected with bridges. In intricate domains with abundant voids and irregular boundaries, the added subregion boundaries increase the path avoidance requirements. This results in excessive bridging and necessitates longer uneven-density spirals to achieve complete subregion coverage. Considering that conformal slit mapping can transform multi-connected regions into regular disks or annuluses without subregion division, this paper presents a novel spiral complete coverage path planning method by conformal slit mapping. Firstly, a slit mapping calculation technique is proposed for segmented cubic spline boundaries with corners. Then, a spiral path spacing control method is developed based on the maximum inscribed circle radius between adjacent conformal slit mapping iso-parameters. Lastly, the spiral path is derived by offsetting iso-parameters. The complexity and applicability of the proposed method are comprehensively analyzed across various boundary scenarios. Meanwhile, two cavities milling experiments are conducted to compare the new method with conventional spiral complete coverage path methods. The comparation indicate that the new path meets the requirement for complete coverage in cavity machining while reducing path length and machining time by 12.70% and 12.34%, respectively.
Towards Diverse and Natural Scene-aware 3D Human Motion Synthesis
May 25, 2022

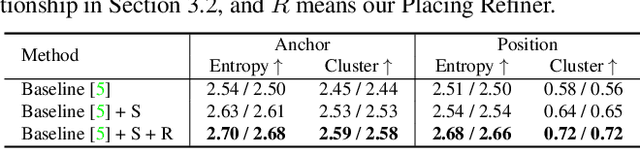
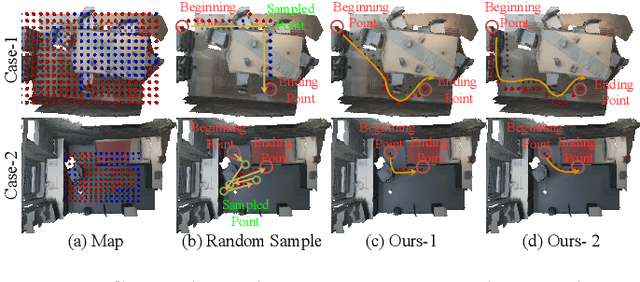
The ability to synthesize long-term human motion sequences in real-world scenes can facilitate numerous applications. Previous approaches for scene-aware motion synthesis are constrained by pre-defined target objects or positions and thus limit the diversity of human-scene interactions for synthesized motions. In this paper, we focus on the problem of synthesizing diverse scene-aware human motions under the guidance of target action sequences. To achieve this, we first decompose the diversity of scene-aware human motions into three aspects, namely interaction diversity (e.g. sitting on different objects with different poses in the given scenes), path diversity (e.g. moving to the target locations following different paths), and the motion diversity (e.g. having various body movements during moving). Based on this factorized scheme, a hierarchical framework is proposed, with each sub-module responsible for modeling one aspect. We assess the effectiveness of our framework on two challenging datasets for scene-aware human motion synthesis. The experiment results show that the proposed framework remarkably outperforms previous methods in terms of diversity and naturalness.
Scene-aware Generative Network for Human Motion Synthesis
May 31, 2021
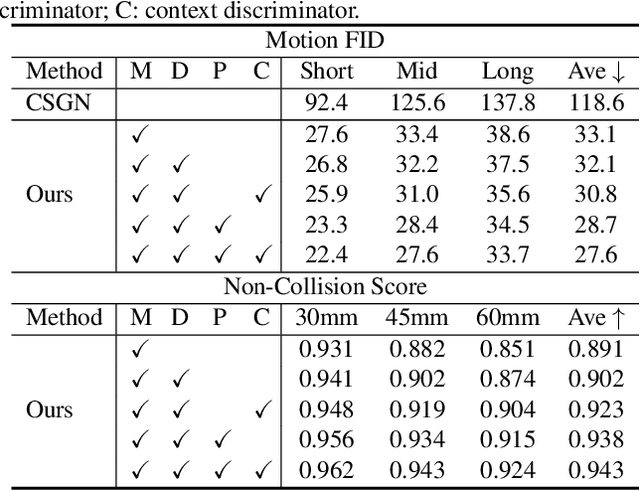
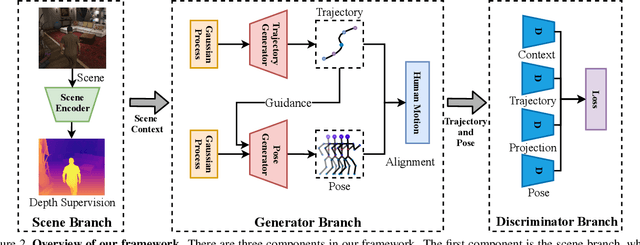
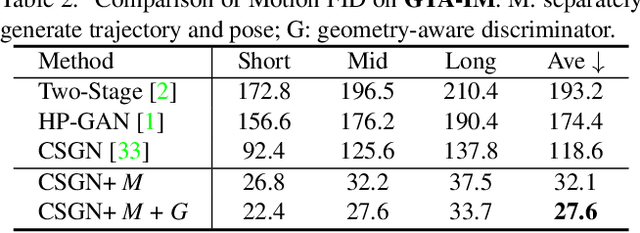
We revisit human motion synthesis, a task useful in various real world applications, in this paper. Whereas a number of methods have been developed previously for this task, they are often limited in two aspects: focusing on the poses while leaving the location movement behind, and ignoring the impact of the environment on the human motion. In this paper, we propose a new framework, with the interaction between the scene and the human motion taken into account. Considering the uncertainty of human motion, we formulate this task as a generative task, whose objective is to generate plausible human motion conditioned on both the scene and the human initial position. This framework factorizes the distribution of human motions into a distribution of movement trajectories conditioned on scenes and that of body pose dynamics conditioned on both scenes and trajectories. We further derive a GAN based learning approach, with discriminators to enforce the compatibility between the human motion and the contextual scene as well as the 3D to 2D projection constraints. We assess the effectiveness of the proposed method on two challenging datasets, which cover both synthetic and real world environments.
Positive-Congruent Training: Towards Regression-Free Model Updates
Nov 20, 2020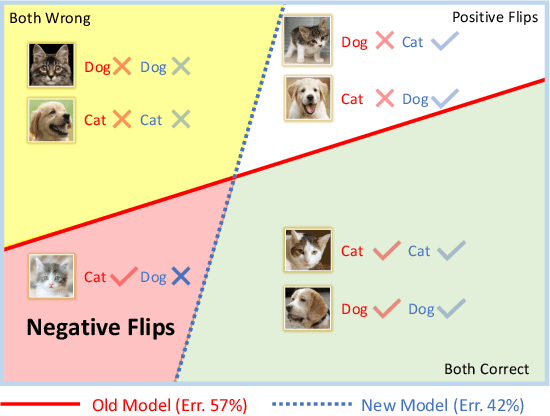
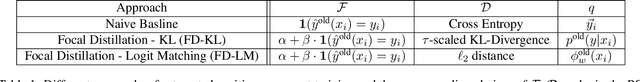
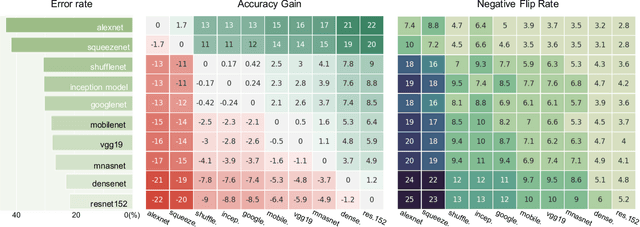
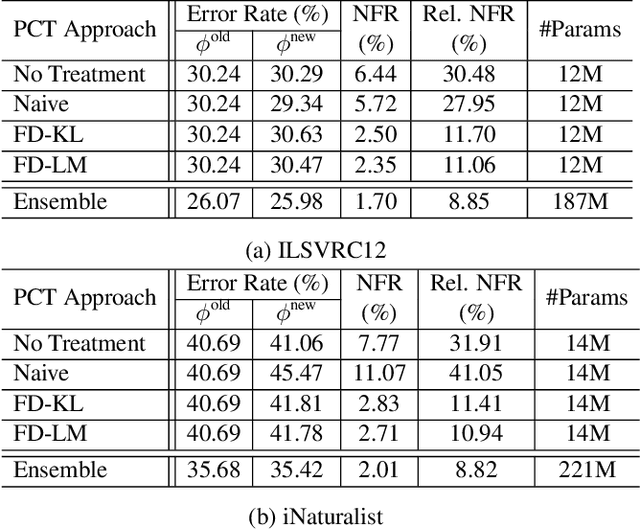
Reducing inconsistencies in the behavior of different versions of an AI system can be as important in practice as reducing its overall error. In image classification, sample-wise inconsistencies appear as "negative flips:" A new model incorrectly predicts the output for a test sample that was correctly classified by the old (reference) model. Positive-congruent (PC) training aims at reducing error rate while at the same time reducing negative flips, thus maximizing congruency with the reference model only on positive predictions, unlike model distillation. We propose a simple approach for PC training, Focal Distillation, which enforces congruence with the reference model by giving more weights to samples that were correctly classified. We also found that, if the reference model itself can be chosen as an ensemble of multiple deep neural networks, negative flips can be further reduced without affecting the new model's accuracy.
Motion Guided 3D Pose Estimation from Videos
Apr 29, 2020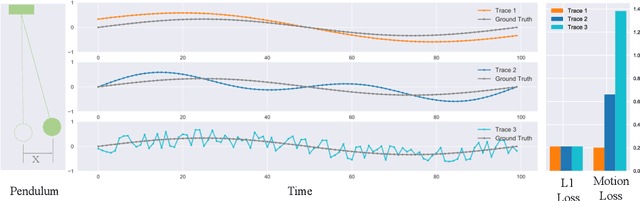



We propose a new loss function, called motion loss, for the problem of monocular 3D Human pose estimation from 2D pose. In computing motion loss, a simple yet effective representation for keypoint motion, called pairwise motion encoding, is introduced. We design a new graph convolutional network architecture, U-shaped GCN (UGCN). It captures both short-term and long-term motion information to fully leverage the additional supervision from the motion loss. We experiment training UGCN with the motion loss on two large scale benchmarks: Human3.6M and MPI-INF-3DHP. Our model surpasses other state-of-the-art models by a large margin. It also demonstrates strong capacity in producing smooth 3D sequences and recovering keypoint motion.
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition
Jan 25, 2018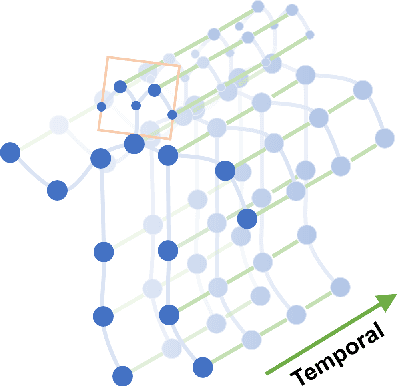
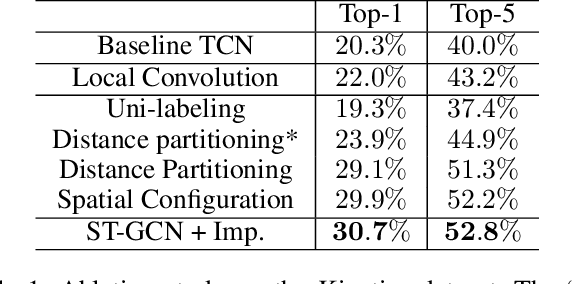

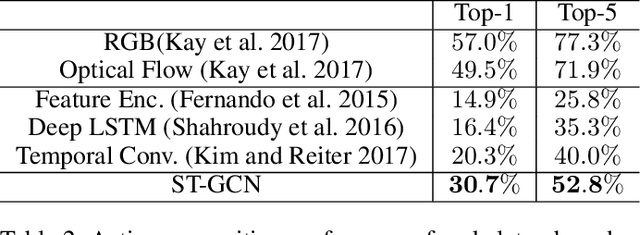
Dynamics of human body skeletons convey significant information for human action recognition. Conventional approaches for modeling skeletons usually rely on hand-crafted parts or traversal rules, thus resulting in limited expressive power and difficulties of generalization. In this work, we propose a novel model of dynamic skeletons called Spatial-Temporal Graph Convolutional Networks (ST-GCN), which moves beyond the limitations of previous methods by automatically learning both the spatial and temporal patterns from data. This formulation not only leads to greater expressive power but also stronger generalization capability. On two large datasets, Kinetics and NTU-RGBD, it achieves substantial improvements over mainstream methods.
Unconstrained Fashion Landmark Detection via Hierarchical Recurrent Transformer Networks
Aug 07, 2017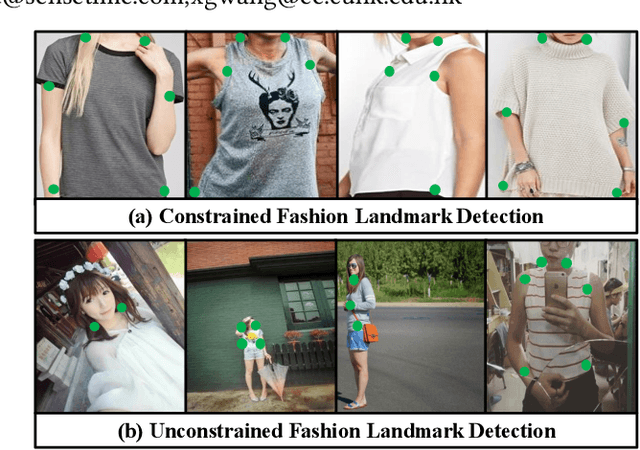

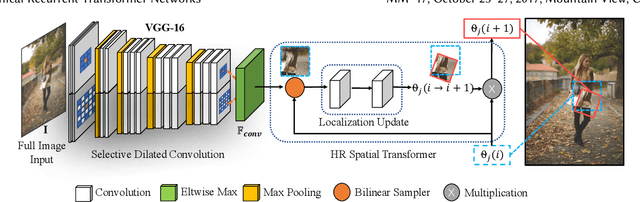

Fashion landmarks are functional key points defined on clothes, such as corners of neckline, hemline, and cuff. They have been recently introduced as an effective visual representation for fashion image understanding. However, detecting fashion landmarks are challenging due to background clutters, human poses, and scales. To remove the above variations, previous works usually assumed bounding boxes of clothes are provided in training and test as additional annotations, which are expensive to obtain and inapplicable in practice. This work addresses unconstrained fashion landmark detection, where clothing bounding boxes are not provided in both training and test. To this end, we present a novel Deep LAndmark Network (DLAN), where bounding boxes and landmarks are jointly estimated and trained iteratively in an end-to-end manner. DLAN contains two dedicated modules, including a Selective Dilated Convolution for handling scale discrepancies, and a Hierarchical Recurrent Spatial Transformer for handling background clutters. To evaluate DLAN, we present a large-scale fashion landmark dataset, namely Unconstrained Landmark Database (ULD), consisting of 30K images. Statistics show that ULD is more challenging than existing datasets in terms of image scales, background clutters, and human poses. Extensive experiments demonstrate the effectiveness of DLAN over the state-of-the-art methods. DLAN also exhibits excellent generalization across different clothing categories and modalities, making it extremely suitable for real-world fashion analysis.
Fashion Landmark Detection in the Wild
Aug 10, 2016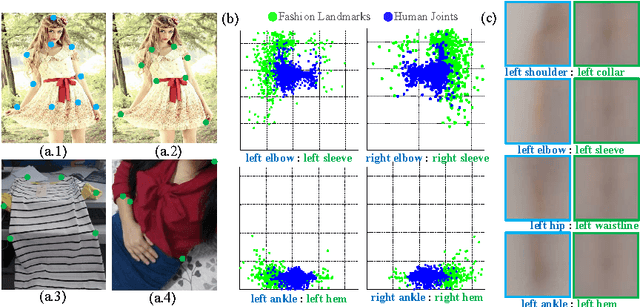

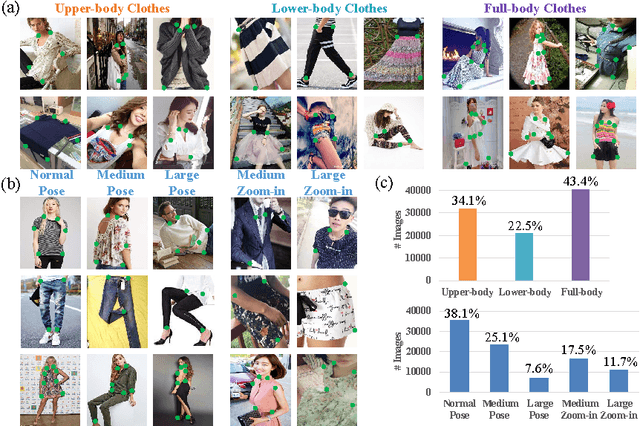
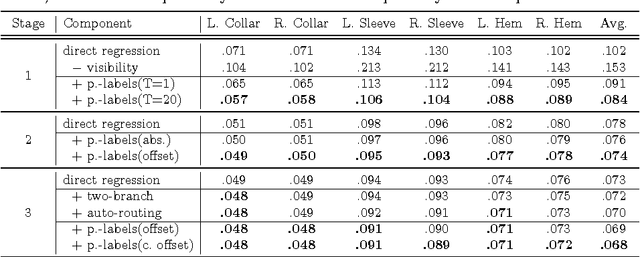
Visual fashion analysis has attracted many attentions in the recent years. Previous work represented clothing regions by either bounding boxes or human joints. This work presents fashion landmark detection or fashion alignment, which is to predict the positions of functional key points defined on the fashion items, such as the corners of neckline, hemline, and cuff. To encourage future studies, we introduce a fashion landmark dataset with over 120K images, where each image is labeled with eight landmarks. With this dataset, we study fashion alignment by cascading multiple convolutional neural networks in three stages. These stages gradually improve the accuracies of landmark predictions. Extensive experiments demonstrate the effectiveness of the proposed method, as well as its generalization ability to pose estimation. Fashion landmark is also compared to clothing bounding boxes and human joints in two applications, fashion attribute prediction and clothes retrieval, showing that fashion landmark is a more discriminative representation to understand fashion images.