 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlan, Watch, Recover: A Benchmark and Architectures for Proactive Procedural Assistance
Jun 03, 2026We envision a proactive multi-modal assistant system which gives users real-time step-by-step guidance on a procedural task, autonomously deciding \textit{when} to interrupt, and \textit{how} to coach. However, progress is limited by the absence of large-scale, cross-domain benchmarks that reflect realistic conditions, particularly the common case in which users deviate from the expected step sequence. We address this gap with four contributions: \textbf{(1)}~we release \textbf{EgoProactive}, a large-scale wearable-egocentric dataset for proactive procedural assistance with explicit Out-of-Plan (OOP) annotations and recovery steps; \textbf{(2)}~we augment five established benchmarks (Ego4D, EPIC-KITCHENS, EgoExo4D, HoloAssist, HowTo100M) into \textbf{Pro\textsuperscript{2}Bench} under a unified proactive-guidance schema; \textbf{(3)}~we propose a \textbf{decoupled planner--interaction architecture} specialized for procedural state, visual cues, and recovery injection; \textbf{(4)}~we introduce a post-training recipe that transfers across model families, validated by cross-backbone replication on Llama~4 and Qwen-3.6-VL. In extensive experiments, our trained Llama-4 system substantially improves objective intervention quality over strong proprietary baselines (Claude Opus~4.6, Gemini~3.1~Pro, GPT~5.2) and open-weight baselines (Qwen3~VL~235B) baselines across all six datasets. Oracle-plan experiments further show that, when plan quality is controlled, the trained duplex model produces high-quality guidance and large gains on Out-of-Plan recovery.
Hierarchical Self-supervised Representation Learning for Movie Understanding
Apr 06, 2022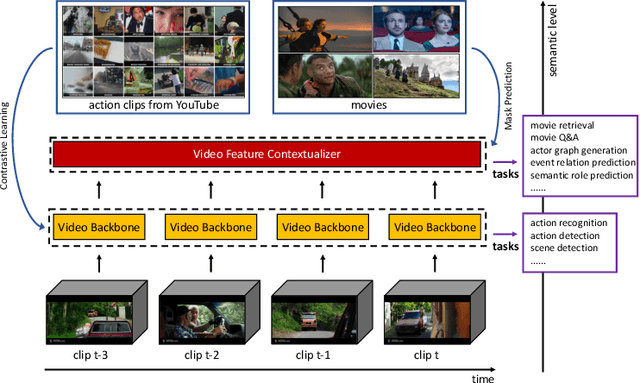
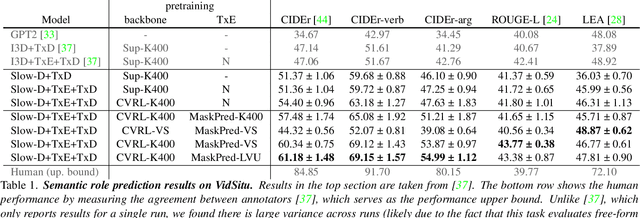
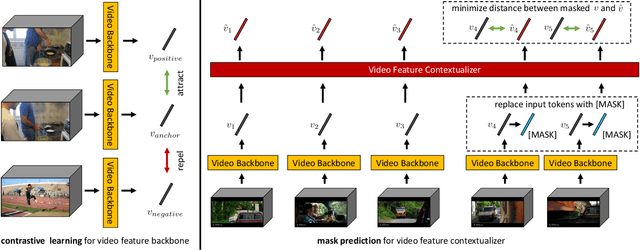
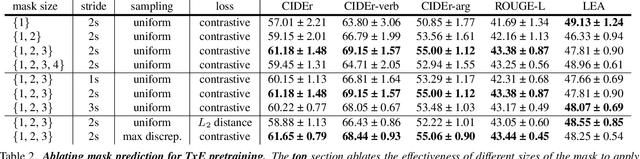
Most self-supervised video representation learning approaches focus on action recognition. In contrast, in this paper we focus on self-supervised video learning for movie understanding and propose a novel hierarchical self-supervised pretraining strategy that separately pretrains each level of our hierarchical movie understanding model (based on [37]). Specifically, we propose to pretrain the low-level video backbone using a contrastive learning objective, while pretrain the higher-level video contextualizer using an event mask prediction task, which enables the usage of different data sources for pretraining different levels of the hierarchy. We first show that our self-supervised pretraining strategies are effective and lead to improved performance on all tasks and metrics on VidSitu benchmark [37] (e.g., improving on semantic role prediction from 47% to 61% CIDEr scores). We further demonstrate the effectiveness of our contextualized event features on LVU tasks [54], both when used alone and when combined with instance features, showing their complementarity.
What to look at and where: Semantic and Spatial Refined Transformer for detecting human-object interactions
Apr 02, 2022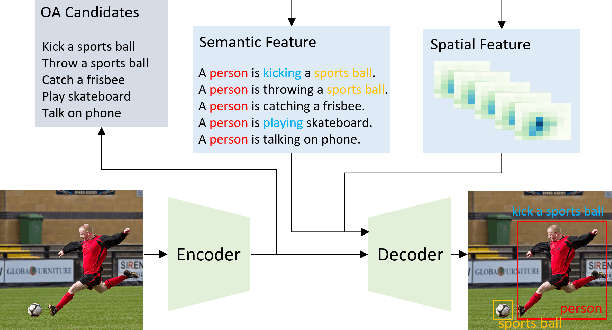
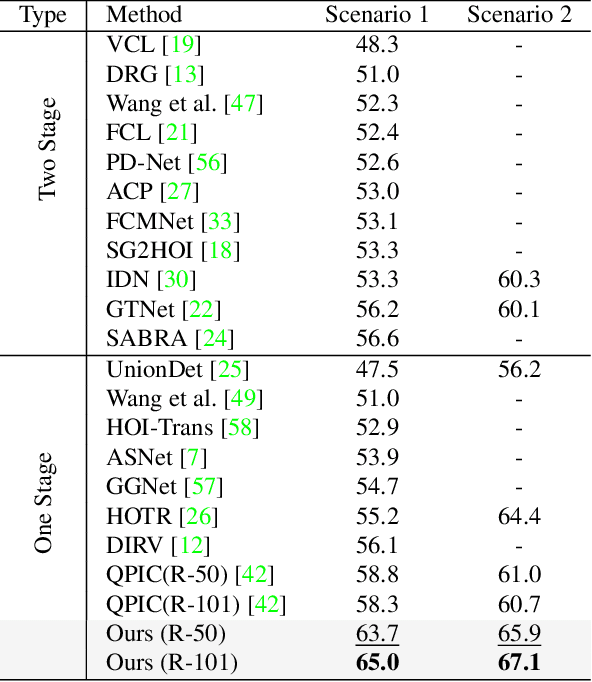
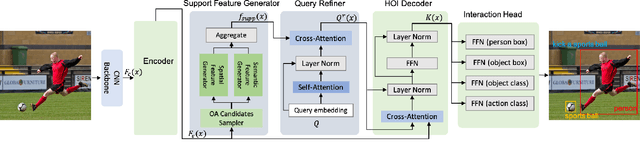
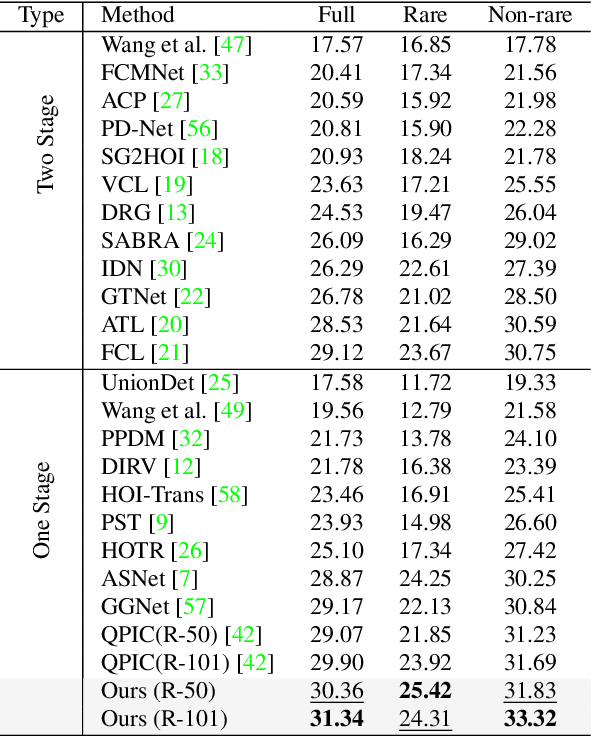
We propose a novel one-stage Transformer-based semantic and spatial refined transformer (SSRT) to solve the Human-Object Interaction detection task, which requires to localize humans and objects, and predicts their interactions. Differently from previous Transformer-based HOI approaches, which mostly focus at improving the design of the decoder outputs for the final detection, SSRT introduces two new modules to help select the most relevant object-action pairs within an image and refine the queries' representation using rich semantic and spatial features. These enhancements lead to state-of-the-art results on the two most popular HOI benchmarks: V-COCO and HICO-DET.
Positive-Congruent Training: Towards Regression-Free Model Updates
Nov 20, 2020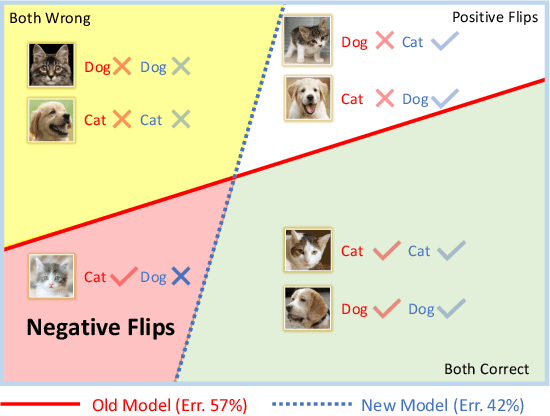
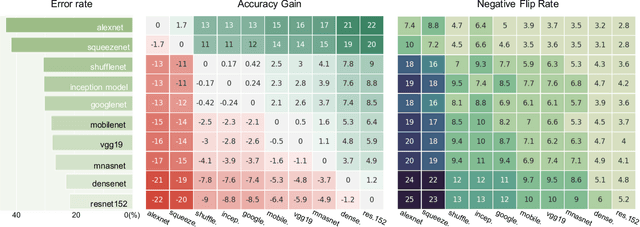
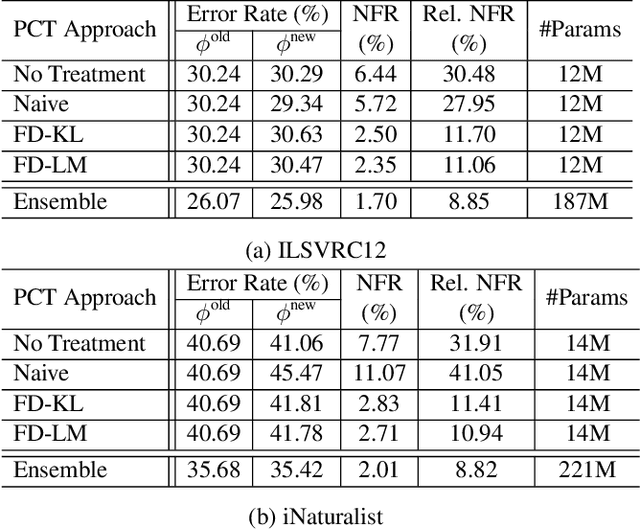
Reducing inconsistencies in the behavior of different versions of an AI system can be as important in practice as reducing its overall error. In image classification, sample-wise inconsistencies appear as "negative flips:" A new model incorrectly predicts the output for a test sample that was correctly classified by the old (reference) model. Positive-congruent (PC) training aims at reducing error rate while at the same time reducing negative flips, thus maximizing congruency with the reference model only on positive predictions, unlike model distillation. We propose a simple approach for PC training, Focal Distillation, which enforces congruence with the reference model by giving more weights to samples that were correctly classified. We also found that, if the reference model itself can be chosen as an ensemble of multiple deep neural networks, negative flips can be further reduced without affecting the new model's accuracy.
SurfConv: Bridging 3D and 2D Convolution for RGBD Images
Dec 04, 2018
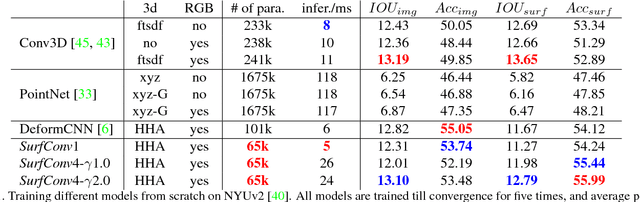
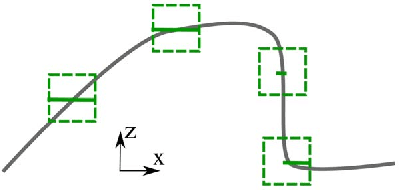
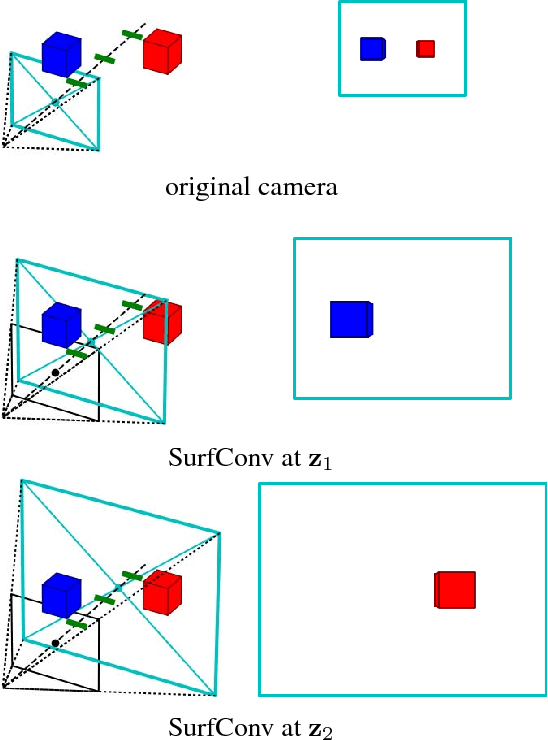
We tackle the problem of using 3D information in convolutional neural networks for down-stream recognition tasks. Using depth as an additional channel alongside the RGB input has the scale variance problem present in image convolution based approaches. On the other hand, 3D convolution wastes a large amount of memory on mostly unoccupied 3D space, which consists of only the surface visible to the sensor. Instead, we propose SurfConv, which "slides" compact 2D filters along the visible 3D surface. SurfConv is formulated as a simple depth-aware multi-scale 2D convolution, through a new Data-Driven Depth Discretization (D4) scheme. We demonstrate the effectiveness of our method on indoor and outdoor 3D semantic segmentation datasets. Our method achieves state-of-the-art performance with less than 30% parameters used by the 3D convolution-based approaches.
* Published at CVPR 2018
Pose Estimation for Objects with Rotational Symmetry
Oct 13, 2018

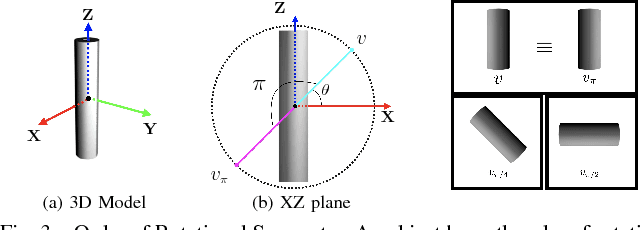
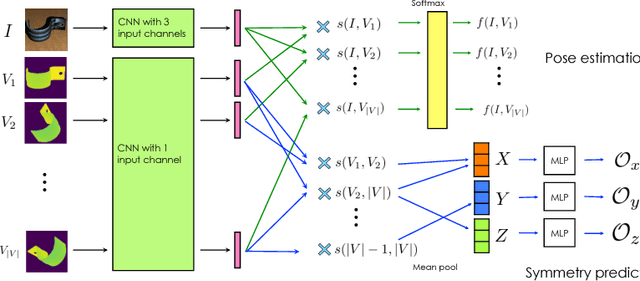
Pose estimation is a widely explored problem, enabling many robotic tasks such as grasping and manipulation. In this paper, we tackle the problem of pose estimation for objects that exhibit rotational symmetry, which are common in man-made and industrial environments. In particular, our aim is to infer poses for objects not seen at training time, but for which their 3D CAD models are available at test time. Previous work has tackled this problem by learning to compare captured views of real objects with the rendered views of their 3D CAD models, by embedding them in a joint latent space using neural networks. We show that sidestepping the issue of symmetry in this scenario during training leads to poor performance at test time. We propose a model that reasons about rotational symmetry during training by having access to only a small set of symmetry-labeled objects, whereby exploiting a large collection of unlabeled CAD models. We demonstrate that our approach significantly outperforms a naively trained neural network on a new pose dataset containing images of tools and hardware.
3D Object Proposals using Stereo Imagery for Accurate Object Class Detection
Apr 25, 2017

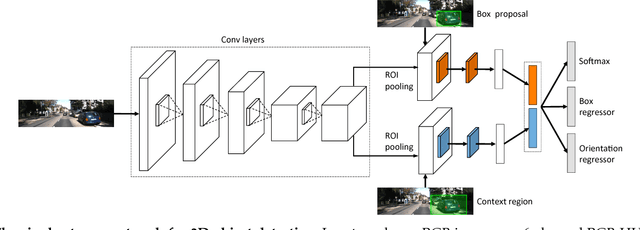
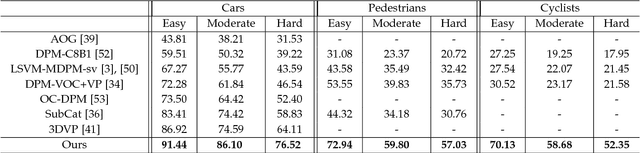
The goal of this paper is to perform 3D object detection in the context of autonomous driving. Our method first aims at generating a set of high-quality 3D object proposals by exploiting stereo imagery. We formulate the problem as minimizing an energy function that encodes object size priors, placement of objects on the ground plane as well as several depth informed features that reason about free space, point cloud densities and distance to the ground. We then exploit a CNN on top of these proposals to perform object detection. In particular, we employ a convolutional neural net (CNN) that exploits context and depth information to jointly regress to 3D bounding box coordinates and object pose. Our experiments show significant performance gains over existing RGB and RGB-D object proposal methods on the challenging KITTI benchmark. When combined with the CNN, our approach outperforms all existing results in object detection and orientation estimation tasks for all three KITTI object classes. Furthermore, we experiment also with the setting where LIDAR information is available, and show that using both LIDAR and stereo leads to the best result.
Annotating Object Instances with a Polygon-RNN
Apr 18, 2017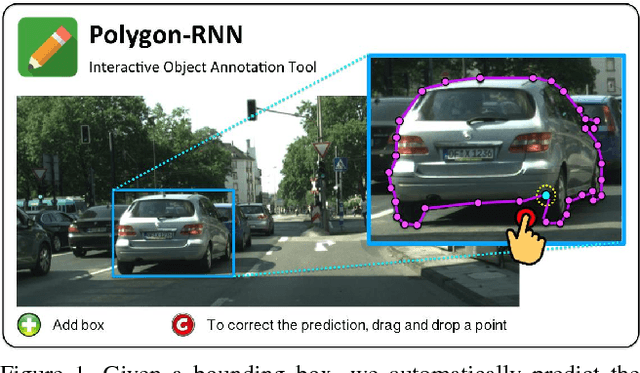
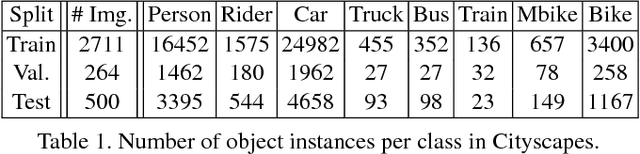
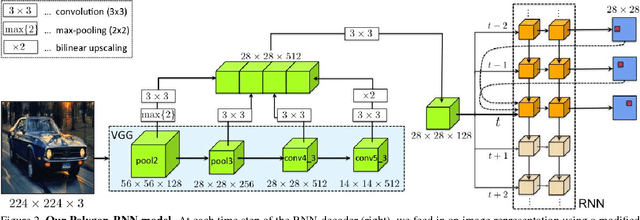
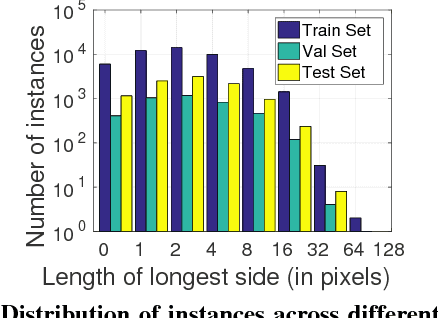
We propose an approach for semi-automatic annotation of object instances. While most current methods treat object segmentation as a pixel-labeling problem, we here cast it as a polygon prediction task, mimicking how most current datasets have been annotated. In particular, our approach takes as input an image crop and sequentially produces vertices of the polygon outlining the object. This allows a human annotator to interfere at any time and correct a vertex if needed, producing as accurate segmentation as desired by the annotator. We show that our approach speeds up the annotation process by a factor of 4.7 across all classes in Cityscapes, while achieving 78.4% agreement in IoU with original ground-truth, matching the typical agreement between human annotators. For cars, our speed-up factor is 7.3 for an agreement of 82.2%. We further show generalization capabilities of our approach to unseen datasets.
Exploiting Semantic Information and Deep Matching for Optical Flow
Aug 23, 2016
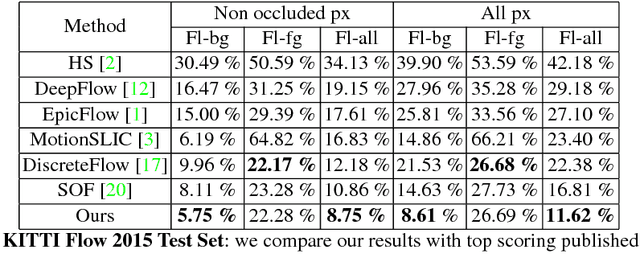
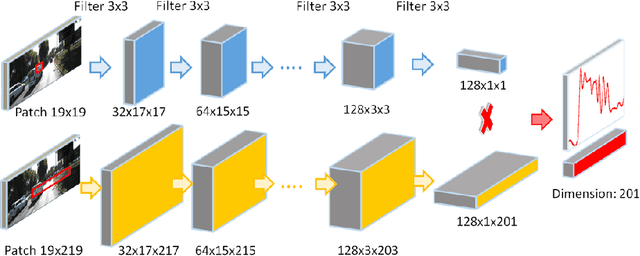
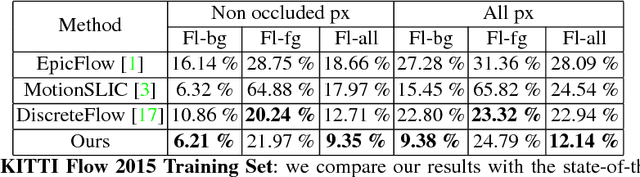
We tackle the problem of estimating optical flow from a monocular camera in the context of autonomous driving. We build on the observation that the scene is typically composed of a static background, as well as a relatively small number of traffic participants which move rigidly in 3D. We propose to estimate the traffic participants using instance-level segmentation. For each traffic participant, we use the epipolar constraints that govern each independent motion for faster and more accurate estimation. Our second contribution is a new convolutional net that learns to perform flow matching, and is able to estimate the uncertainty of its matches. This is a core element of our flow estimation pipeline. We demonstrate the effectiveness of our approach in the challenging KITTI 2015 flow benchmark, and show that our approach outperforms published approaches by a large margin.