 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Self-supervised Representation Learning for Movie Understanding
Paper and Code
Apr 06, 2022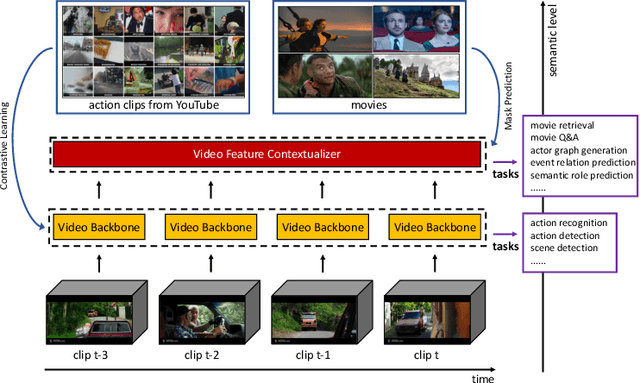
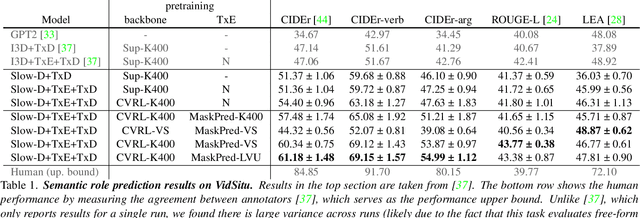
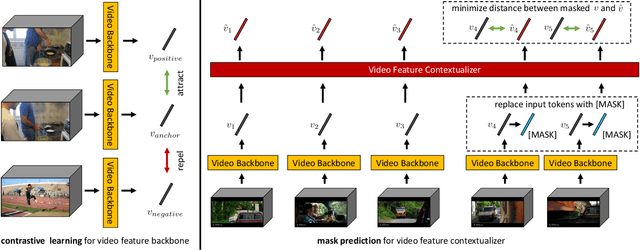
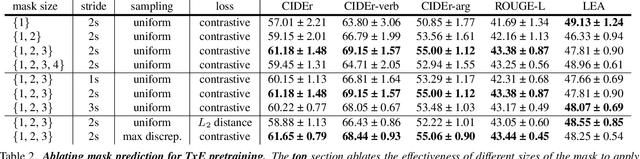
Most self-supervised video representation learning approaches focus on action recognition. In contrast, in this paper we focus on self-supervised video learning for movie understanding and propose a novel hierarchical self-supervised pretraining strategy that separately pretrains each level of our hierarchical movie understanding model (based on [37]). Specifically, we propose to pretrain the low-level video backbone using a contrastive learning objective, while pretrain the higher-level video contextualizer using an event mask prediction task, which enables the usage of different data sources for pretraining different levels of the hierarchy. We first show that our self-supervised pretraining strategies are effective and lead to improved performance on all tasks and metrics on VidSitu benchmark [37] (e.g., improving on semantic role prediction from 47% to 61% CIDEr scores). We further demonstrate the effectiveness of our contextualized event features on LVU tasks [54], both when used alone and when combined with instance features, showing their complementarity.