 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning
May 28, 2026Vision-Language Models (VLMs) often struggle with robust 3D spatial reasoning. Prevailing methods that rely on fine-tuning with 3D visual question-answering (VQA) datasets may overfit dataset-specific biases, while integrating specialized 3D visual encoders is often inflexible and cumbersome. In this paper, we argue that genuine spatial understanding should emerge from learning fundamental geometric priors, not only from high-level VQA supervision. We propose GASP (Geometric-Aware Spatial Priors), a framework that injects these priors directly into the LLM's transformer layers. GASP employs a small correspondence head, applied as a deep supervision signal across all layers, and is trained with a dual objective leveraging ground-truth geometry from large-scale video scenes: a contrastive loss on ground-truth point correspondences enforces 2D view-invariance, while a depth consistency supervision resolves 3D geometric ambiguities. Our analysis first provides a diagnostic showing that standard VLMs' internal correspondence matching accuracy is very low (often below 5%). We then demonstrate that our training substantially improves this behavior, boosting peak layer-wise correspondence to over 70% and maintaining over 85% temporal robustness while baselines remain below 5%. These internal improvements translate to significant gains on downstream spatial benchmarks including +18.2% on All-Angles Bench and +29.0% on VSI-Bench, all without training on any 3D VQA data. Our findings indicate that learning from fundamental geometric priors is a promising and generalizable pathway towards VLMs with more reliable 3D spatial reasoning.
Sparse CLIP: Co-Optimizing Interpretability and Performance in Contrastive Learning
Jan 27, 2026Contrastive Language-Image Pre-training (CLIP) has become a cornerstone in vision-language representation learning, powering diverse downstream tasks and serving as the default vision backbone in multimodal large language models (MLLMs). Despite its success, CLIP's dense and opaque latent representations pose significant interpretability challenges. A common assumption is that interpretability and performance are in tension: enforcing sparsity during training degrades accuracy, motivating recent post-hoc approaches such as Sparse Autoencoders (SAEs). However, these post-hoc approaches often suffer from degraded downstream performance and loss of CLIP's inherent multimodal capabilities, with most learned features remaining unimodal. We propose a simple yet effective approach that integrates sparsity directly into CLIP training, yielding representations that are both interpretable and performant. Compared to SAEs, our Sparse CLIP representations preserve strong downstream task performance, achieve superior interpretability, and retain multimodal capabilities. We show that multimodal sparse features enable straightforward semantic concept alignment and reveal training dynamics of how cross-modal knowledge emerges. Finally, as a proof of concept, we train a vision-language model on sparse CLIP representations that enables interpretable, vision-based steering capabilities. Our findings challenge conventional wisdom that interpretability requires sacrificing accuracy and demonstrate that interpretability and performance can be co-optimized, offering a promising design principle for future models.
Benchmarking Egocentric Multimodal Goal Inference for Assistive Wearable Agents
Oct 25, 2025There has been a surge of interest in assistive wearable agents: agents embodied in wearable form factors (e.g., smart glasses) who take assistive actions toward a user's goal/query (e.g. "Where did I leave my keys?"). In this work, we consider the important complementary problem of inferring that goal from multi-modal contextual observations. Solving this "goal inference" problem holds the promise of eliminating the effort needed to interact with such an agent. This work focuses on creating WAGIBench, a strong benchmark to measure progress in solving this problem using vision-language models (VLMs). Given the limited prior work in this area, we collected a novel dataset comprising 29 hours of multimodal data from 348 participants across 3,477 recordings, featuring ground-truth goals alongside accompanying visual, audio, digital, and longitudinal contextual observations. We validate that human performance exceeds model performance, achieving 93% multiple-choice accuracy compared with 84% for the best-performing VLM. Generative benchmark results that evaluate several families of modern vision-language models show that larger models perform significantly better on the task, yet remain far from practical usefulness, as they produce relevant goals only 55% of the time. Through a modality ablation, we show that models benefit from extra information in relevant modalities with minimal performance degradation from irrelevant modalities.
EdgeTAM: On-Device Track Anything Model
Jan 13, 2025On top of Segment Anything Model (SAM), SAM 2 further extends its capability from image to video inputs through a memory bank mechanism and obtains a remarkable performance compared with previous methods, making it a foundation model for video segmentation task. In this paper, we aim at making SAM 2 much more efficient so that it even runs on mobile devices while maintaining a comparable performance. Despite several works optimizing SAM for better efficiency, we find they are not sufficient for SAM 2 because they all focus on compressing the image encoder, while our benchmark shows that the newly introduced memory attention blocks are also the latency bottleneck. Given this observation, we propose EdgeTAM, which leverages a novel 2D Spatial Perceiver to reduce the computational cost. In particular, the proposed 2D Spatial Perceiver encodes the densely stored frame-level memories with a lightweight Transformer that contains a fixed set of learnable queries. Given that video segmentation is a dense prediction task, we find preserving the spatial structure of the memories is essential so that the queries are split into global-level and patch-level groups. We also propose a distillation pipeline that further improves the performance without inference overhead. As a result, EdgeTAM achieves 87.7, 70.0, 72.3, and 71.7 J&F on DAVIS 2017, MOSE, SA-V val, and SA-V test, while running at 16 FPS on iPhone 15 Pro Max.
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Oct 22, 2024



Multimodal Large Language Models (MLLMs) have shown promising progress in understanding and analyzing video content. However, processing long videos remains a significant challenge constrained by LLM's context size. To address this limitation, we propose LongVU, a spatiotemporal adaptive compression mechanism thats reduces the number of video tokens while preserving visual details of long videos. Our idea is based on leveraging cross-modal query and inter-frame dependencies to adaptively reduce temporal and spatial redundancy in videos. Specifically, we leverage DINOv2 features to remove redundant frames that exhibit high similarity. Then we utilize text-guided cross-modal query for selective frame feature reduction. Further, we perform spatial token reduction across frames based on their temporal dependencies. Our adaptive compression strategy effectively processes a large number of frames with little visual information loss within given context length. Our LongVU consistently surpass existing methods across a variety of video understanding benchmarks, especially on hour-long video understanding tasks such as VideoMME and MLVU. Given a light-weight LLM, our LongVU also scales effectively into a smaller size with state-of-the-art video understanding performance.
Gen2Det: Generate to Detect
Dec 07, 2023Recently diffusion models have shown improvement in synthetic image quality as well as better control in generation. We motivate and present Gen2Det, a simple modular pipeline to create synthetic training data for object detection for free by leveraging state-of-the-art grounded image generation methods. Unlike existing works which generate individual object instances, require identifying foreground followed by pasting on other images, we simplify to directly generating scene-centric images. In addition to the synthetic data, Gen2Det also proposes a suite of techniques to best utilize the generated data, including image-level filtering, instance-level filtering, and better training recipe to account for imperfections in the generation. Using Gen2Det, we show healthy improvements on object detection and segmentation tasks under various settings and agnostic to detection methods. In the long-tailed detection setting on LVIS, Gen2Det improves the performance on rare categories by a large margin while also significantly improving the performance on other categories, e.g. we see an improvement of 2.13 Box AP and 1.84 Mask AP over just training on real data on LVIS with Mask R-CNN. In the low-data regime setting on COCO, Gen2Det consistently improves both Box and Mask AP by 2.27 and 1.85 points. In the most general detection setting, Gen2Det still demonstrates robust performance gains, e.g. it improves the Box and Mask AP on COCO by 0.45 and 0.32 points.
Diversify, Don't Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Dec 04, 2023

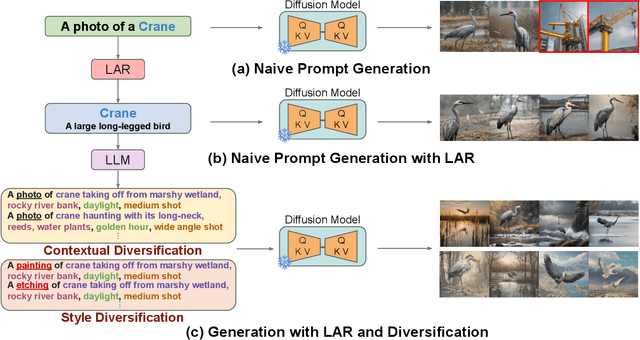

Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier's performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023



Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
EgoObjects: A Large-Scale Egocentric Dataset for Fine-Grained Object Understanding
Sep 15, 2023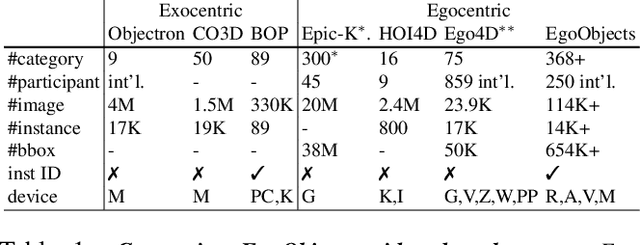

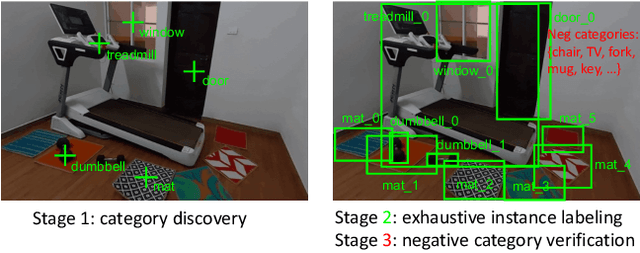
Object understanding in egocentric visual data is arguably a fundamental research topic in egocentric vision. However, existing object datasets are either non-egocentric or have limitations in object categories, visual content, and annotation granularities. In this work, we introduce EgoObjects, a large-scale egocentric dataset for fine-grained object understanding. Its Pilot version contains over 9K videos collected by 250 participants from 50+ countries using 4 wearable devices, and over 650K object annotations from 368 object categories. Unlike prior datasets containing only object category labels, EgoObjects also annotates each object with an instance-level identifier, and includes over 14K unique object instances. EgoObjects was designed to capture the same object under diverse background complexities, surrounding objects, distance, lighting and camera motion. In parallel to the data collection, we conducted data annotation by developing a multi-stage federated annotation process to accommodate the growing nature of the dataset. To bootstrap the research on EgoObjects, we present a suite of 4 benchmark tasks around the egocentric object understanding, including a novel instance level- and the classical category level object detection. Moreover, we also introduce 2 novel continual learning object detection tasks. The dataset and API are available at https://github.com/facebookresearch/EgoObjects.
Exploring Open-Vocabulary Semantic Segmentation without Human Labels
Jun 01, 2023Semantic segmentation is a crucial task in computer vision that involves segmenting images into semantically meaningful regions at the pixel level. However, existing approaches often rely on expensive human annotations as supervision for model training, limiting their scalability to large, unlabeled datasets. To address this challenge, we present ZeroSeg, a novel method that leverages the existing pretrained vision-language (VL) model (e.g. CLIP) to train open-vocabulary zero-shot semantic segmentation models. Although acquired extensive knowledge of visual concepts, it is non-trivial to exploit knowledge from these VL models to the task of semantic segmentation, as they are usually trained at an image level. ZeroSeg overcomes this by distilling the visual concepts learned by VL models into a set of segment tokens, each summarizing a localized region of the target image. We evaluate ZeroSeg on multiple popular segmentation benchmarks, including PASCAL VOC 2012, PASCAL Context, and COCO, in a zero-shot manner (i.e., no training or adaption on target segmentation datasets). Our approach achieves state-of-the-art performance when compared to other zero-shot segmentation methods under the same training data, while also performing competitively compared to strongly supervised methods. Finally, we also demonstrated the effectiveness of ZeroSeg on open-vocabulary segmentation, through both human studies and qualitative visualizations.