 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-objective Evolutionary Algorithm Based on Bi-population with Uniform Sampling for Neural Architecture Search
Feb 09, 2026Neural architecture search (NAS) automates neural network design, improving efficiency over manual approaches. However, efficiently discovering high-performance neural network architectures that simultaneously optimize multiple objectives remains a significant challenge in NAS. Existing methods often suffer from limited population diversity and inadequate exploration of the search space, particularly in regions with extreme complexity values. To address these challenges, we propose MOEA-BUS, an innovative multi-objective evolutionary algorithm based on bi-population with uniform sampling for neural architecture search, aimed at simultaneously optimizing both accuracy and network complexity. In MOEA-BUS, a novel uniform sampling method is proposed to initialize the population, ensuring that architectures are distributed uniformly across the objective space. Furthermore, to enhance exploration, we deploy a bi-population framework where two populations evolve synergistically, facilitating comprehensive search space coverage. Experiments on CIFAR-10 and ImageNet demonstrate MOEA-BUS's superiority, achieving top-1 accuracies of 98.39% on CIFAR-10, and 80.03% on ImageNet. Notably, it achieves 78.28% accuracy on ImageNet with only 446M MAdds. Ablation studies confirm that both uniform sampling and bi-population mechanisms enhance population diversity and performance. Additionally, in terms of the Kendall's tau coefficient, the SVM achieves an improvement of at least 0.035 compared to the other three commonly used machine learning models, and uniform sampling provided an enhancement of approximately 0.07.
SCONE: A Practical, Constraint-Aware Plug-in for Latent Encoding in Learned DNA Storage
Feb 05, 2026DNA storage has matured from concept to practical stage, yet its integration with neural compression pipelines remains inefficient. Early DNA encoders applied redundancy-heavy constraint layers atop raw binary data - workable but primitive. Recent neural codecs compress data into learned latent representations with rich statistical structure, yet still convert these latents to DNA via naive binary-to-quaternary transcoding, discarding the entropy model's optimization. This mismatch undermines compression efficiency and complicates the encoding stack. A plug-in module that collapses latent compression and DNA encoding into a single step. SCONE performs quaternary arithmetic coding directly on the latent space in DNA bases. Its Constraint-Aware Adaptive Coding module dynamically steers the entropy encoder's learned probability distribution to enforce biochemical constraints - Guanine-Cytosine (GC) balance and homopolymer suppression - deterministically during encoding, eliminating post-hoc correction. The design preserves full reversibility and exploits the hyperprior model's learned priors without modification. Experiments show SCONE achieves near-perfect constraint satisfaction with negligible computational overhead (<2% latency), establishing a latent-agnostic interface for end-to-end DNA-compatible learned codecs.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
EdgeTAM: On-Device Track Anything Model
Jan 13, 2025On top of Segment Anything Model (SAM), SAM 2 further extends its capability from image to video inputs through a memory bank mechanism and obtains a remarkable performance compared with previous methods, making it a foundation model for video segmentation task. In this paper, we aim at making SAM 2 much more efficient so that it even runs on mobile devices while maintaining a comparable performance. Despite several works optimizing SAM for better efficiency, we find they are not sufficient for SAM 2 because they all focus on compressing the image encoder, while our benchmark shows that the newly introduced memory attention blocks are also the latency bottleneck. Given this observation, we propose EdgeTAM, which leverages a novel 2D Spatial Perceiver to reduce the computational cost. In particular, the proposed 2D Spatial Perceiver encodes the densely stored frame-level memories with a lightweight Transformer that contains a fixed set of learnable queries. Given that video segmentation is a dense prediction task, we find preserving the spatial structure of the memories is essential so that the queries are split into global-level and patch-level groups. We also propose a distillation pipeline that further improves the performance without inference overhead. As a result, EdgeTAM achieves 87.7, 70.0, 72.3, and 71.7 J&F on DAVIS 2017, MOSE, SA-V val, and SA-V test, while running at 16 FPS on iPhone 15 Pro Max.
Efficient Track Anything
Nov 28, 2024Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size. Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. We take vanilla lightweight ViTs and efficient memory module to build EfficientTAMs, and train the models on SA-1B and SA-V datasets for video object segmentation and track anything tasks. We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation, and find that our proposed EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction. On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Oct 22, 2024



Multimodal Large Language Models (MLLMs) have shown promising progress in understanding and analyzing video content. However, processing long videos remains a significant challenge constrained by LLM's context size. To address this limitation, we propose LongVU, a spatiotemporal adaptive compression mechanism thats reduces the number of video tokens while preserving visual details of long videos. Our idea is based on leveraging cross-modal query and inter-frame dependencies to adaptively reduce temporal and spatial redundancy in videos. Specifically, we leverage DINOv2 features to remove redundant frames that exhibit high similarity. Then we utilize text-guided cross-modal query for selective frame feature reduction. Further, we perform spatial token reduction across frames based on their temporal dependencies. Our adaptive compression strategy effectively processes a large number of frames with little visual information loss within given context length. Our LongVU consistently surpass existing methods across a variety of video understanding benchmarks, especially on hour-long video understanding tasks such as VideoMME and MLVU. Given a light-weight LLM, our LongVU also scales effectively into a smaller size with state-of-the-art video understanding performance.
A Pairwise Comparison Relation-assisted Multi-objective Evolutionary Neural Architecture Search Method with Multi-population Mechanism
Jul 22, 2024Neural architecture search (NAS) enables re-searchers to automatically explore vast search spaces and find efficient neural networks. But NAS suffers from a key bottleneck, i.e., numerous architectures need to be evaluated during the search process, which requires a lot of computing resources and time. In order to improve the efficiency of NAS, a series of methods have been proposed to reduce the evaluation time of neural architectures. However, they are not efficient enough and still only focus on the accuracy of architectures. In addition to the classification accuracy, more efficient and smaller network architectures are required in real-world applications. To address the above problems, we propose the SMEM-NAS, a pairwise com-parison relation-assisted multi-objective evolutionary algorithm based on a multi-population mechanism. In the SMEM-NAS, a surrogate model is constructed based on pairwise compari-son relations to predict the accuracy ranking of architectures, rather than the absolute accuracy. Moreover, two populations cooperate with each other in the search process, i.e., a main population guides the evolution, while a vice population expands the diversity. Our method aims to provide high-performance models that take into account multiple optimization objectives. We conduct a series of experiments on the CIFAR-10, CIFAR-100 and ImageNet datasets to verify its effectiveness. With only a single GPU searching for 0.17 days, competitive architectures can be found by SMEM-NAS which achieves 78.91% accuracy with the MAdds of 570M on the ImageNet. This work makes a significant advance in the important field of NAS.
SqueezeSAM: User friendly mobile interactive segmentation
Dec 11, 2023Segment Anything Model (SAM) is a foundation model for interactive segmentation, and it has catalyzed major advances in generative AI, computational photography, and medical imaging. This model takes in an arbitrary user input and provides segmentation masks of the corresponding objects. It is our goal to develop a version of SAM that is appropriate for use in a photography app. The original SAM model has a few challenges in this setting. First, original SAM a 600 million parameter based on ViT-H, and its high computational cost and large model size that are not suitable for todays mobile hardware. We address this by proposing the SqueezeSAM model architecture, which is 50x faster and 100x smaller than SAM. Next, when a user takes a photo on their phone, it might not occur to them to click on the image and get a mask. Our solution is to use salient object detection to generate the first few clicks. This produces an initial segmentation mask that the user can interactively edit. Finally, when a user clicks on an object, they typically expect all related pieces of the object to be segmented. For instance, if a user clicks on a person t-shirt in a photo, they expect the whole person to be segmented, but SAM typically segments just the t-shirt. We address this with a new data augmentation scheme, and the end result is that if the user clicks on a person holding a basketball, the person and the basketball are all segmented together.
Gen2Det: Generate to Detect
Dec 07, 2023Recently diffusion models have shown improvement in synthetic image quality as well as better control in generation. We motivate and present Gen2Det, a simple modular pipeline to create synthetic training data for object detection for free by leveraging state-of-the-art grounded image generation methods. Unlike existing works which generate individual object instances, require identifying foreground followed by pasting on other images, we simplify to directly generating scene-centric images. In addition to the synthetic data, Gen2Det also proposes a suite of techniques to best utilize the generated data, including image-level filtering, instance-level filtering, and better training recipe to account for imperfections in the generation. Using Gen2Det, we show healthy improvements on object detection and segmentation tasks under various settings and agnostic to detection methods. In the long-tailed detection setting on LVIS, Gen2Det improves the performance on rare categories by a large margin while also significantly improving the performance on other categories, e.g. we see an improvement of 2.13 Box AP and 1.84 Mask AP over just training on real data on LVIS with Mask R-CNN. In the low-data regime setting on COCO, Gen2Det consistently improves both Box and Mask AP by 2.27 and 1.85 points. In the most general detection setting, Gen2Det still demonstrates robust performance gains, e.g. it improves the Box and Mask AP on COCO by 0.45 and 0.32 points.
Diversify, Don't Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Dec 04, 2023

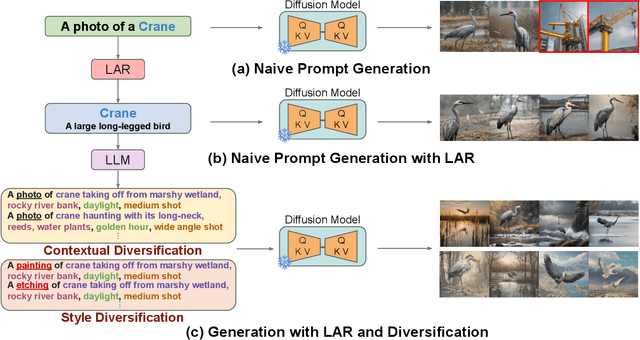

Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier's performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.