 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
Dec 17, 2025We present Gaussian Pixel Codec Avatars (GPiCA), photorealistic head avatars that can be generated from multi-view images and efficiently rendered on mobile devices. GPiCA utilizes a unique hybrid representation that combines a triangle mesh and anisotropic 3D Gaussians. This combination maximizes memory and rendering efficiency while maintaining a photorealistic appearance. The triangle mesh is highly efficient in representing surface areas like facial skin, while the 3D Gaussians effectively handle non-surface areas such as hair and beard. To this end, we develop a unified differentiable rendering pipeline that treats the mesh as a semi-transparent layer within the volumetric rendering paradigm of 3D Gaussian Splatting. We train neural networks to decode a facial expression code into three components: a 3D face mesh, an RGBA texture, and a set of 3D Gaussians. These components are rendered simultaneously in a unified rendering engine. The networks are trained using multi-view image supervision. Our results demonstrate that GPiCA achieves the realism of purely Gaussian-based avatars while matching the rendering performance of mesh-based avatars.
SqueezeMe: Efficient Gaussian Avatars for VR
Dec 19, 2024



Gaussian Splatting has enabled real-time 3D human avatars with unprecedented levels of visual quality. While previous methods require a desktop GPU for real-time inference of a single avatar, we aim to squeeze multiple Gaussian avatars onto a portable virtual reality headset with real-time drivable inference. We begin by training a previous work, Animatable Gaussians, on a high quality dataset captured with 512 cameras. The Gaussians are animated by controlling base set of Gaussians with linear blend skinning (LBS) motion and then further adjusting the Gaussians with a neural network decoder to correct their appearance. When deploying the model on a Meta Quest 3 VR headset, we find two major computational bottlenecks: the decoder and the rendering. To accelerate the decoder, we train the Gaussians in UV-space instead of pixel-space, and we distill the decoder to a single neural network layer. Further, we discover that neighborhoods of Gaussians can share a single corrective from the decoder, which provides an additional speedup. To accelerate the rendering, we develop a custom pipeline in Vulkan that runs on the mobile GPU. Putting it all together, we run 3 Gaussian avatars concurrently at 72 FPS on a VR headset. Demo videos are at https://forresti.github.io/squeezeme.
Make-A-Texture: Fast Shape-Aware Texture Generation in 3 Seconds
Dec 10, 2024



We present Make-A-Texture, a new framework that efficiently synthesizes high-resolution texture maps from textual prompts for given 3D geometries. Our approach progressively generates textures that are consistent across multiple viewpoints with a depth-aware inpainting diffusion model, in an optimized sequence of viewpoints determined by an automatic view selection algorithm. A significant feature of our method is its remarkable efficiency, achieving a full texture generation within an end-to-end runtime of just 3.07 seconds on a single NVIDIA H100 GPU, significantly outperforming existing methods. Such an acceleration is achieved by optimizations in the diffusion model and a specialized backprojection method. Moreover, our method reduces the artifacts in the backprojection phase, by selectively masking out non-frontal faces, and internal faces of open-surfaced objects. Experimental results demonstrate that Make-A-Texture matches or exceeds the quality of other state-of-the-art methods. Our work significantly improves the applicability and practicality of texture generation models for real-world 3D content creation, including interactive creation and text-guided texture editing.
Efficient Track Anything
Nov 28, 2024Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size. Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. We take vanilla lightweight ViTs and efficient memory module to build EfficientTAMs, and train the models on SA-1B and SA-V datasets for video object segmentation and track anything tasks. We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation, and find that our proposed EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction. On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Feb 22, 2024This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.
SteinDreamer: Variance Reduction for Text-to-3D Score Distillation via Stein Identity
Dec 31, 2023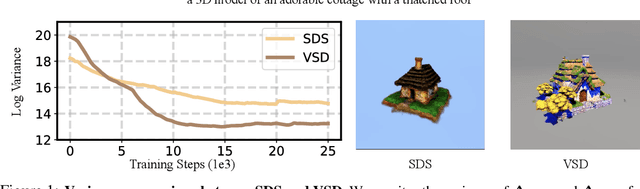
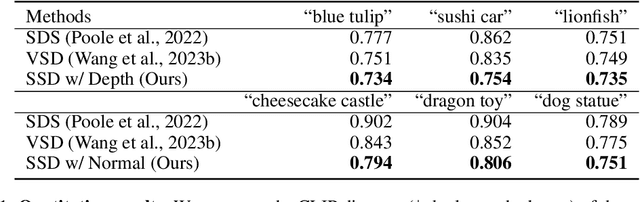
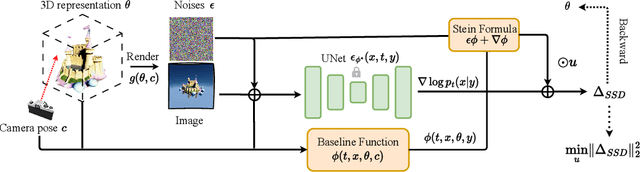
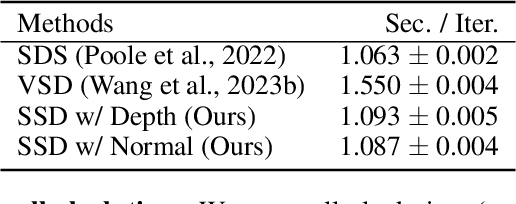
Score distillation has emerged as one of the most prevalent approaches for text-to-3D asset synthesis. Essentially, score distillation updates 3D parameters by lifting and back-propagating scores averaged over different views. In this paper, we reveal that the gradient estimation in score distillation is inherent to high variance. Through the lens of variance reduction, the effectiveness of SDS and VSD can be interpreted as applications of various control variates to the Monte Carlo estimator of the distilled score. Motivated by this rethinking and based on Stein's identity, we propose a more general solution to reduce variance for score distillation, termed Stein Score Distillation (SSD). SSD incorporates control variates constructed by Stein identity, allowing for arbitrary baseline functions. This enables us to include flexible guidance priors and network architectures to explicitly optimize for variance reduction. In our experiments, the overall pipeline, dubbed SteinDreamer, is implemented by instantiating the control variate with a monocular depth estimator. The results suggest that SSD can effectively reduce the distillation variance and consistently improve visual quality for both object- and scene-level generation. Moreover, we demonstrate that SteinDreamer achieves faster convergence than existing methods due to more stable gradient updates.
Taming Mode Collapse in Score Distillation for Text-to-3D Generation
Dec 31, 2023
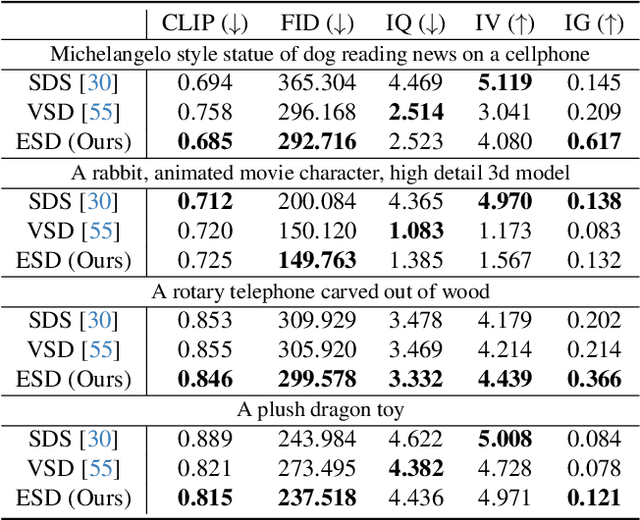
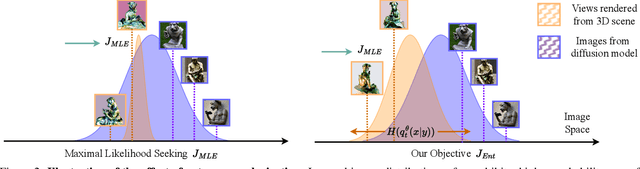
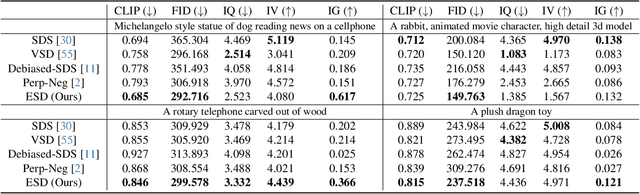
Despite the remarkable performance of score distillation in text-to-3D generation, such techniques notoriously suffer from view inconsistency issues, also known as "Janus" artifact, where the generated objects fake each view with multiple front faces. Although empirically effective methods have approached this problem via score debiasing or prompt engineering, a more rigorous perspective to explain and tackle this problem remains elusive. In this paper, we reveal that the existing score distillation-based text-to-3D generation frameworks degenerate to maximal likelihood seeking on each view independently and thus suffer from the mode collapse problem, manifesting as the Janus artifact in practice. To tame mode collapse, we improve score distillation by re-establishing in entropy term in the corresponding variational objective, which is applied to the distribution of rendered images. Maximizing the entropy encourages diversity among different views in generated 3D assets, thereby mitigating the Janus problem. Based on this new objective, we derive a new update rule for 3D score distillation, dubbed Entropic Score Distillation (ESD). We theoretically reveal that ESD can be simplified and implemented by just adopting the classifier-free guidance trick upon variational score distillation. Although embarrassingly straightforward, our extensive experiments successfully demonstrate that ESD can be an effective treatment for Janus artifacts in score distillation.
SqueezeSAM: User friendly mobile interactive segmentation
Dec 11, 2023Segment Anything Model (SAM) is a foundation model for interactive segmentation, and it has catalyzed major advances in generative AI, computational photography, and medical imaging. This model takes in an arbitrary user input and provides segmentation masks of the corresponding objects. It is our goal to develop a version of SAM that is appropriate for use in a photography app. The original SAM model has a few challenges in this setting. First, original SAM a 600 million parameter based on ViT-H, and its high computational cost and large model size that are not suitable for todays mobile hardware. We address this by proposing the SqueezeSAM model architecture, which is 50x faster and 100x smaller than SAM. Next, when a user takes a photo on their phone, it might not occur to them to click on the image and get a mask. Our solution is to use salient object detection to generate the first few clicks. This produces an initial segmentation mask that the user can interactively edit. Finally, when a user clicks on an object, they typically expect all related pieces of the object to be segmented. For instance, if a user clicks on a person t-shirt in a photo, they expect the whole person to be segmented, but SAM typically segments just the t-shirt. We address this with a new data augmentation scheme, and the end result is that if the user clicks on a person holding a basketball, the person and the basketball are all segmented together.
EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
Dec 01, 2023



Segment Anything Model (SAM) has emerged as a powerful tool for numerous vision applications. A key component that drives the impressive performance for zero-shot transfer and high versatility is a super large Transformer model trained on the extensive high-quality SA-1B dataset. While beneficial, the huge computation cost of SAM model has limited its applications to wider real-world applications. To address this limitation, we propose EfficientSAMs, light-weight SAM models that exhibits decent performance with largely reduced complexity. Our idea is based on leveraging masked image pretraining, SAMI, which learns to reconstruct features from SAM image encoder for effective visual representation learning. Further, we take SAMI-pretrained light-weight image encoders and mask decoder to build EfficientSAMs, and finetune the models on SA-1B for segment anything task. We perform evaluations on multiple vision tasks including image classification, object detection, instance segmentation, and semantic object detection, and find that our proposed pretraining method, SAMI, consistently outperforms other masked image pretraining methods. On segment anything task such as zero-shot instance segmentation, our EfficientSAMs with SAMI-pretrained lightweight image encoders perform favorably with a significant gain (e.g., ~4 AP on COCO/LVIS) over other fast SAM models.
On The Open Prompt Challenge In Conditional Audio Generation
Nov 01, 2023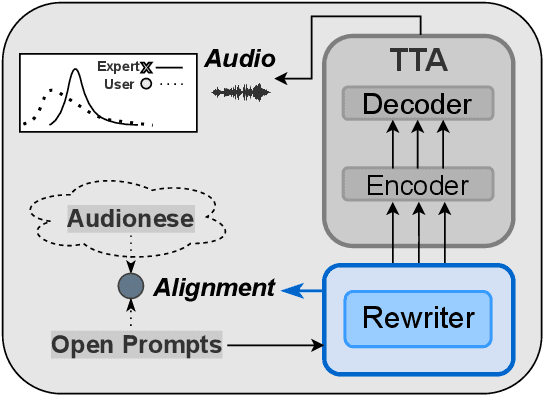
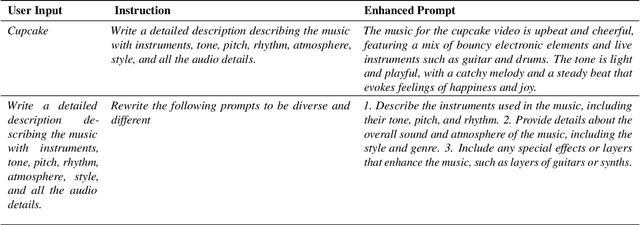
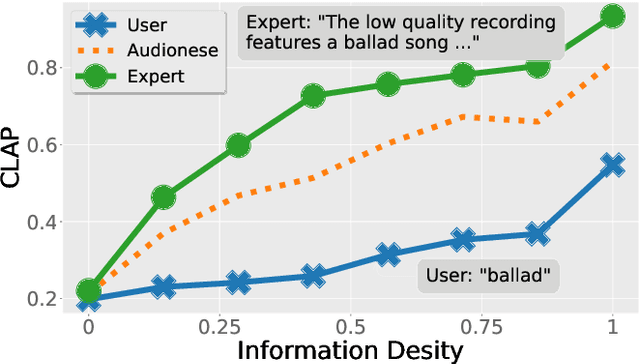
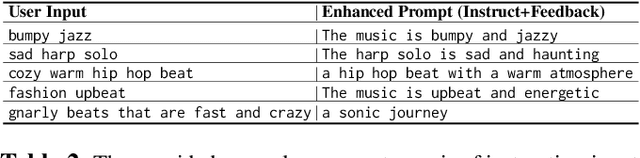
Text-to-audio generation (TTA) produces audio from a text description, learning from pairs of audio samples and hand-annotated text. However, commercializing audio generation is challenging as user-input prompts are often under-specified when compared to text descriptions used to train TTA models. In this work, we treat TTA models as a ``blackbox'' and address the user prompt challenge with two key insights: (1) User prompts are generally under-specified, leading to a large alignment gap between user prompts and training prompts. (2) There is a distribution of audio descriptions for which TTA models are better at generating higher quality audio, which we refer to as ``audionese''. To this end, we rewrite prompts with instruction-tuned models and propose utilizing text-audio alignment as feedback signals via margin ranking learning for audio improvements. On both objective and subjective human evaluations, we observed marked improvements in both text-audio alignment and music audio quality.