 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
DεpS: Delayed ε-Shrinking for Faster Once-For-All Training
Jul 08, 2024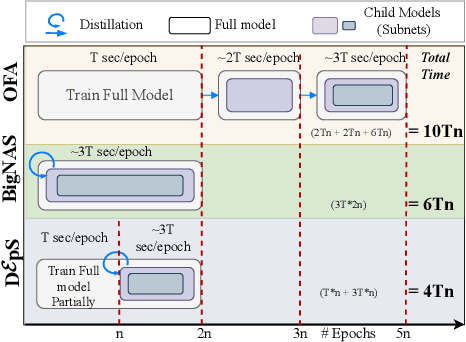

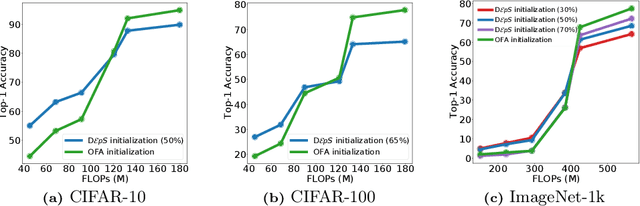

CNNs are increasingly deployed across different hardware, dynamic environments, and low-power embedded devices. This has led to the design and training of CNN architectures with the goal of maximizing accuracy subject to such variable deployment constraints. As the number of deployment scenarios grows, there is a need to find scalable solutions to design and train specialized CNNs. Once-for-all training has emerged as a scalable approach that jointly co-trains many models (subnets) at once with a constant training cost and finds specialized CNNs later. The scalability is achieved by training the full model and simultaneously reducing it to smaller subnets that share model weights (weight-shared shrinking). However, existing once-for-all training approaches incur huge training costs reaching 1200 GPU hours. We argue this is because they either start the process of shrinking the full model too early or too late. Hence, we propose Delayed $\epsilon$-Shrinking (D$\epsilon$pS) that starts the process of shrinking the full model when it is partially trained (~50%) which leads to training cost improvement and better in-place knowledge distillation to smaller models. The proposed approach also consists of novel heuristics that dynamically adjust subnet learning rates incrementally (E), leading to improved weight-shared knowledge distillation from larger to smaller subnets as well. As a result, DEpS outperforms state-of-the-art once-for-all training techniques across different datasets including CIFAR10/100, ImageNet-100, and ImageNet-1k on accuracy and cost. It achieves 1.83% higher ImageNet-1k top1 accuracy or the same accuracy with 1.3x reduction in FLOPs and 2.5x drop in training cost (GPU*hrs)
SpinQuant: LLM quantization with learned rotations
May 28, 2024



Post-training quantization (PTQ) techniques applied to weights, activations, and the KV cache greatly reduce memory usage, latency, and power consumption of Large Language Models (LLMs), but may lead to large quantization errors when outliers are present. Recent findings suggest that rotating activation or weight matrices helps remove outliers and benefits quantization. In this work, we identify a collection of applicable rotation parameterizations that lead to identical outputs in full-precision Transformer architectures, and find that some random rotations lead to much better quantization than others, with an up to 13 points difference in downstream zero-shot reasoning performance. As a result, we propose SpinQuant that optimizes (or learns) the rotation matrices with Cayley optimization on a small validation set. With 4-bit quantization of weight, activation, and KV-cache, SpinQuant narrows the accuracy gap on zero-shot reasoning tasks with full precision to merely 2.9 points on the LLaMA-2 7B model, surpassing LLM-QAT by 19.1 points and SmoothQuant by 25.0 points. SpinQuant also outperforms concurrent work QuaRot, which applies random rotations to remove outliers. In particular, for LLaMA-2 7B/LLaMA-3 8B models that are hard to quantize, SpinQuant reduces the gap to full precision by 30.2%/34.1% relative to QuaRot.
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Feb 22, 2024This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.
SiGeo: Sub-One-Shot NAS via Information Theory and Geometry of Loss Landscape
Nov 22, 2023Neural Architecture Search (NAS) has become a widely used tool for automating neural network design. While one-shot NAS methods have successfully reduced computational requirements, they often require extensive training. On the other hand, zero-shot NAS utilizes training-free proxies to evaluate a candidate architecture's test performance but has two limitations: (1) inability to use the information gained as a network improves with training and (2) unreliable performance, particularly in complex domains like RecSys, due to the multi-modal data inputs and complex architecture configurations. To synthesize the benefits of both methods, we introduce a "sub-one-shot" paradigm that serves as a bridge between zero-shot and one-shot NAS. In sub-one-shot NAS, the supernet is trained using only a small subset of the training data, a phase we refer to as "warm-up." Within this framework, we present SiGeo, a proxy founded on a novel theoretical framework that connects the supernet warm-up with the efficacy of the proxy. Extensive experiments have shown that SiGeo, with the benefit of warm-up, consistently outperforms state-of-the-art NAS proxies on various established NAS benchmarks. When a supernet is warmed up, it can achieve comparable performance to weight-sharing one-shot NAS methods, but with a significant reduction ($\sim 60$\%) in computational costs.
Rankitect: Ranking Architecture Search Battling World-class Engineers at Meta Scale
Nov 14, 2023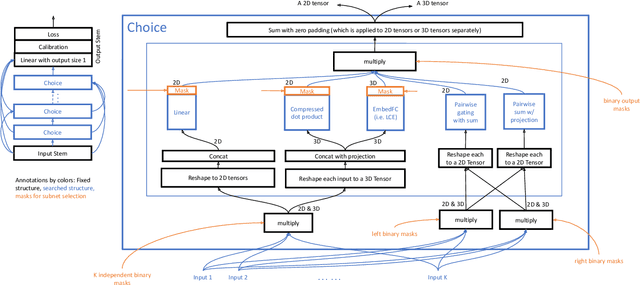
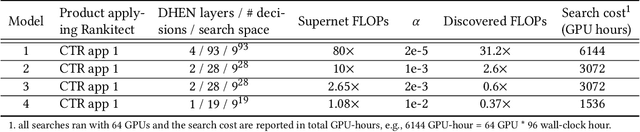
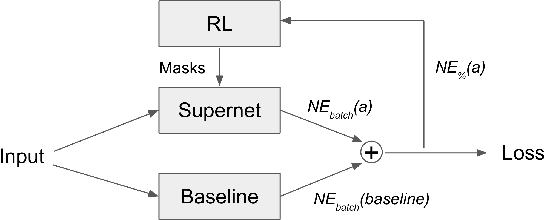
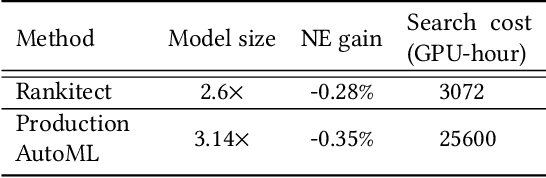
Neural Architecture Search (NAS) has demonstrated its efficacy in computer vision and potential for ranking systems. However, prior work focused on academic problems, which are evaluated at small scale under well-controlled fixed baselines. In industry system, such as ranking system in Meta, it is unclear whether NAS algorithms from the literature can outperform production baselines because of: (1) scale - Meta ranking systems serve billions of users, (2) strong baselines - the baselines are production models optimized by hundreds to thousands of world-class engineers for years since the rise of deep learning, (3) dynamic baselines - engineers may have established new and stronger baselines during NAS search, and (4) efficiency - the search pipeline must yield results quickly in alignment with the productionization life cycle. In this paper, we present Rankitect, a NAS software framework for ranking systems at Meta. Rankitect seeks to build brand new architectures by composing low level building blocks from scratch. Rankitect implements and improves state-of-the-art (SOTA) NAS methods for comprehensive and fair comparison under the same search space, including sampling-based NAS, one-shot NAS, and Differentiable NAS (DNAS). We evaluate Rankitect by comparing to multiple production ranking models at Meta. We find that Rankitect can discover new models from scratch achieving competitive tradeoff between Normalized Entropy loss and FLOPs. When utilizing search space designed by engineers, Rankitect can generate better models than engineers, achieving positive offline evaluation and online A/B test at Meta scale.
DistDNAS: Search Efficient Feature Interactions within 2 Hours
Nov 01, 2023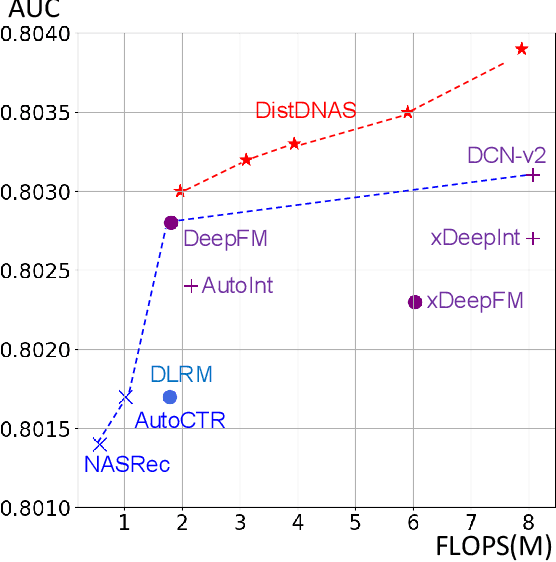

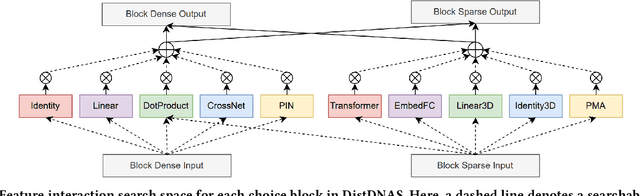

Search efficiency and serving efficiency are two major axes in building feature interactions and expediting the model development process in recommender systems. On large-scale benchmarks, searching for the optimal feature interaction design requires extensive cost due to the sequential workflow on the large volume of data. In addition, fusing interactions of various sources, orders, and mathematical operations introduces potential conflicts and additional redundancy toward recommender models, leading to sub-optimal trade-offs in performance and serving cost. In this paper, we present DistDNAS as a neat solution to brew swift and efficient feature interaction design. DistDNAS proposes a supernet to incorporate interaction modules of varying orders and types as a search space. To optimize search efficiency, DistDNAS distributes the search and aggregates the choice of optimal interaction modules on varying data dates, achieving over 25x speed-up and reducing search cost from 2 days to 2 hours. To optimize serving efficiency, DistDNAS introduces a differentiable cost-aware loss to penalize the selection of redundant interaction modules, enhancing the efficiency of discovered feature interactions in serving. We extensively evaluate the best models crafted by DistDNAS on a 1TB Criteo Terabyte dataset. Experimental evaluations demonstrate 0.001 AUC improvement and 60% FLOPs saving over current state-of-the-art CTR models.
PerfSAGE: Generalized Inference Performance Predictor for Arbitrary Deep Learning Models on Edge Devices
Jan 26, 2023The ability to accurately predict deep neural network (DNN) inference performance metrics, such as latency, power, and memory footprint, for an arbitrary DNN on a target hardware platform is essential to the design of DNN based models. This ability is critical for the (manual or automatic) design, optimization, and deployment of practical DNNs for a specific hardware deployment platform. Unfortunately, these metrics are slow to evaluate using simulators (where available) and typically require measurement on the target hardware. This work describes PerfSAGE, a novel graph neural network (GNN) that predicts inference latency, energy, and memory footprint on an arbitrary DNN TFlite graph (TFL, 2017). In contrast, previously published performance predictors can only predict latency and are restricted to pre-defined construction rules or search spaces. This paper also describes the EdgeDLPerf dataset of 134,912 DNNs randomly sampled from four task search spaces and annotated with inference performance metrics from three edge hardware platforms. Using this dataset, we train PerfSAGE and provide experimental results that demonstrate state-of-the-art prediction accuracy with a Mean Absolute Percentage Error of <5% across all targets and model search spaces. These results: (1) Outperform previous state-of-art GNN-based predictors (Dudziak et al., 2020), (2) Accurately predict performance on accelerators (a shortfall of non-GNN-based predictors (Zhang et al., 2021)), and (3) Demonstrate predictions on arbitrary input graphs without modifications to the feature extractor.