 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Free Group-Wise Fully Quantized Winograd Convolution via Learnable Scales
Dec 27, 2024



Despite the revolutionary breakthroughs of large-scale textto-image diffusion models for complex vision and downstream tasks, their extremely high computational and storage costs limit their usability. Quantization of diffusion models has been explored in recent works to reduce compute costs and memory bandwidth usage. To further improve inference time, fast convolution algorithms such as Winograd can be used for convolution layers, which account for a significant portion of computations in diffusion models. However, the significant quality loss of fully quantized Winograd using existing coarser-grained post-training quantization methods, combined with the complexity and cost of finetuning the Winograd transformation matrices for such large models to recover quality, makes them unsuitable for large-scale foundation models. Motivated by the presence of a large range of values in them, we investigate the impact of finer-grained group-wise quantization in quantizing diffusion models. While group-wise quantization can largely handle the fully quantized Winograd convolution, it struggles to deal with the large distribution imbalance in a sizable portion of the Winograd domain computation. To reduce range differences in the Winograd domain, we propose finetuning only the scale parameters of the Winograd transform matrices without using any domain-specific training data. Because our method does not depend on any training data, the generalization performance of quantized diffusion models is safely guaranteed. For text-to-image generation task, the 8-bit fully-quantized diffusion model with Winograd provides near-lossless quality (FID and CLIP scores) in comparison to the full-precision model. For image classification, our method outperforms the state-of-the-art Winograd PTQ method by 1.62% and 2.56% in top-1 ImageNet accuracy on ResNet18 and ResNet-34, respectively, with Winograd F(6, 3).
Jumping through Local Minima: Quantization in the Loss Landscape of Vision Transformers
Aug 21, 2023Quantization scale and bit-width are the most important parameters when considering how to quantize a neural network. Prior work focuses on optimizing quantization scales in a global manner through gradient methods (gradient descent \& Hessian analysis). Yet, when applying perturbations to quantization scales, we observe a very jagged, highly non-smooth test loss landscape. In fact, small perturbations in quantization scale can greatly affect accuracy, yielding a $0.5-0.8\%$ accuracy boost in 4-bit quantized vision transformers (ViTs). In this regime, gradient methods break down, since they cannot reliably reach local minima. In our work, dubbed Evol-Q, we use evolutionary search to effectively traverse the non-smooth landscape. Additionally, we propose using an infoNCE loss, which not only helps combat overfitting on the small calibration dataset ($1,000$ images) but also makes traversing such a highly non-smooth surface easier. Evol-Q improves the top-1 accuracy of a fully quantized ViT-Base by $10.30\%$, $0.78\%$, and $0.15\%$ for $3$-bit, $4$-bit, and $8$-bit weight quantization levels. Extensive experiments on a variety of CNN and ViT architectures further demonstrate its robustness in extreme quantization scenarios. Our code is available at https://github.com/enyac-group/evol-q
PerfSAGE: Generalized Inference Performance Predictor for Arbitrary Deep Learning Models on Edge Devices
Jan 26, 2023The ability to accurately predict deep neural network (DNN) inference performance metrics, such as latency, power, and memory footprint, for an arbitrary DNN on a target hardware platform is essential to the design of DNN based models. This ability is critical for the (manual or automatic) design, optimization, and deployment of practical DNNs for a specific hardware deployment platform. Unfortunately, these metrics are slow to evaluate using simulators (where available) and typically require measurement on the target hardware. This work describes PerfSAGE, a novel graph neural network (GNN) that predicts inference latency, energy, and memory footprint on an arbitrary DNN TFlite graph (TFL, 2017). In contrast, previously published performance predictors can only predict latency and are restricted to pre-defined construction rules or search spaces. This paper also describes the EdgeDLPerf dataset of 134,912 DNNs randomly sampled from four task search spaces and annotated with inference performance metrics from three edge hardware platforms. Using this dataset, we train PerfSAGE and provide experimental results that demonstrate state-of-the-art prediction accuracy with a Mean Absolute Percentage Error of <5% across all targets and model search spaces. These results: (1) Outperform previous state-of-art GNN-based predictors (Dudziak et al., 2020), (2) Accurately predict performance on accelerators (a shortfall of non-GNN-based predictors (Zhang et al., 2021)), and (3) Demonstrate predictions on arbitrary input graphs without modifications to the feature extractor.
CPT-V: A Contrastive Approach to Post-Training Quantization of Vision Transformers
Nov 17, 2022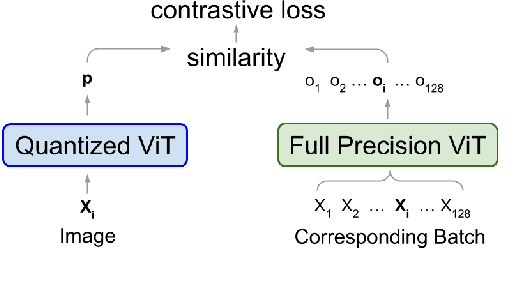
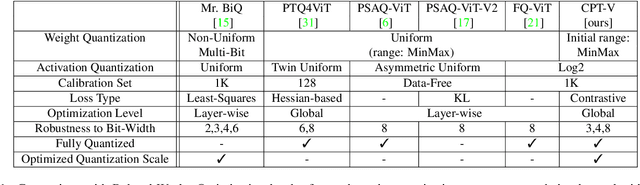
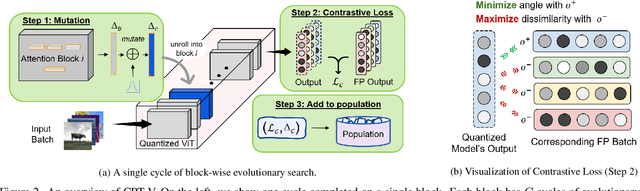
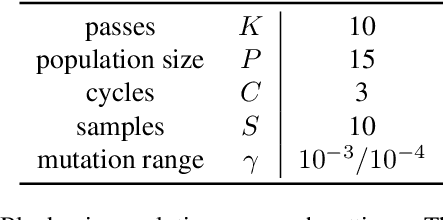
When considering post-training quantization, prior work has typically focused on developing a mixed precision scheme or learning the best way to partition a network for quantization. In our work, CPT-V, we look at a general way to improve the accuracy of networks that have already been quantized, simply by perturbing the quantization scales. Borrowing the idea of contrastive loss from self-supervised learning, we find a robust way to jointly minimize a loss function using just 1,000 calibration images. In order to determine the best performing quantization scale, CPT-V contrasts the features of quantized and full precision models in a self-supervised fashion. Unlike traditional reconstruction-based loss functions, the use of a contrastive loss function not only rewards similarity between the quantized and full precision outputs but also helps in distinguishing the quantized output from other outputs within a given batch. In addition, in contrast to prior works, CPT-V proposes a block-wise evolutionary search to minimize a global contrastive loss objective, allowing for accuracy improvement of existing vision transformer (ViT) quantization schemes. For example, CPT-V improves the top-1 accuracy of a fully quantized ViT-Base by 10.30%, 0.78%, and 0.15% for 3-bit, 4-bit, and 8-bit weight quantization levels. Extensive experiments on a variety of other ViT architectures further demonstrate its robustness in extreme quantization scenarios. Our code is available at <link>.
Restructurable Activation Networks
Aug 17, 2022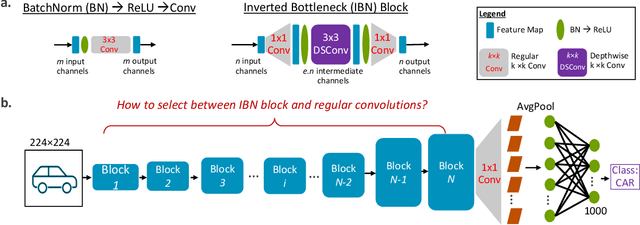
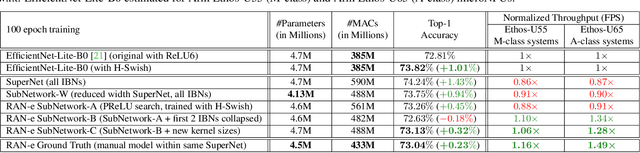
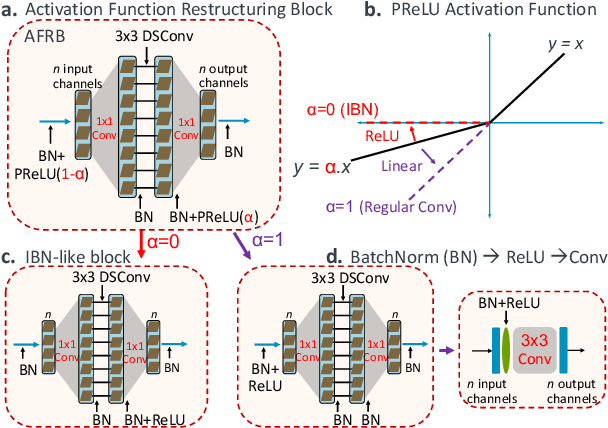
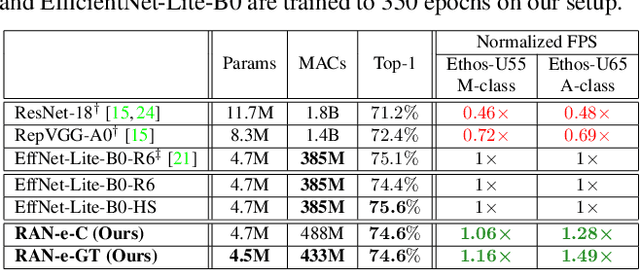
Is it possible to restructure the non-linear activation functions in a deep network to create hardware-efficient models? To address this question, we propose a new paradigm called Restructurable Activation Networks (RANs) that manipulate the amount of non-linearity in models to improve their hardware-awareness and efficiency. First, we propose RAN-explicit (RAN-e) -- a new hardware-aware search space and a semi-automatic search algorithm -- to replace inefficient blocks with hardware-aware blocks. Next, we propose a training-free model scaling method called RAN-implicit (RAN-i) where we theoretically prove the link between network topology and its expressivity in terms of number of non-linear units. We demonstrate that our networks achieve state-of-the-art results on ImageNet at different scales and for several types of hardware. For example, compared to EfficientNet-Lite-B0, RAN-e achieves a similar accuracy while improving Frames-Per-Second (FPS) by 1.5x on Arm micro-NPUs. On the other hand, RAN-i demonstrates up to 2x reduction in #MACs over ConvNexts with a similar or better accuracy. We also show that RAN-i achieves nearly 40% higher FPS than ConvNext on Arm-based datacenter CPUs. Finally, RAN-i based object detection networks achieve a similar or higher mAP and up to 33% higher FPS on datacenter CPUs compared to ConvNext based models.
Super-Efficient Super Resolution for Fast Adversarial Defense at the Edge
Dec 29, 2021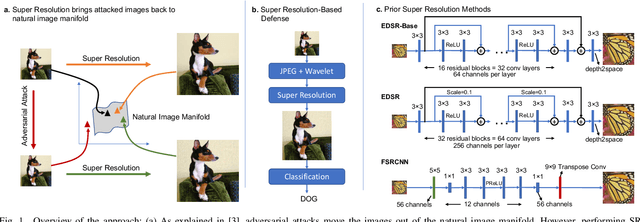
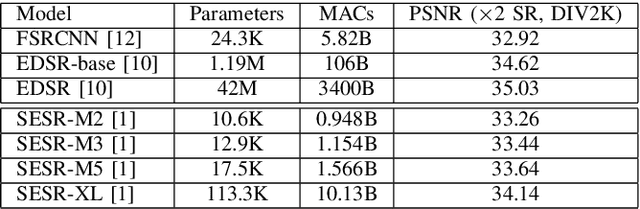
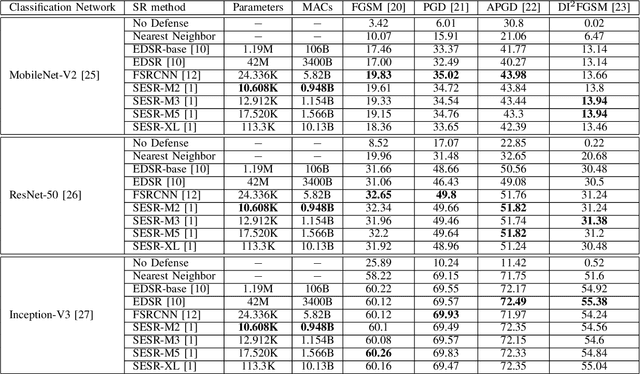
Autonomous systems are highly vulnerable to a variety of adversarial attacks on Deep Neural Networks (DNNs). Training-free model-agnostic defenses have recently gained popularity due to their speed, ease of deployment, and ability to work across many DNNs. To this end, a new technique has emerged for mitigating attacks on image classification DNNs, namely, preprocessing adversarial images using super resolution -- upscaling low-quality inputs into high-resolution images. This defense requires running both image classifiers and super resolution models on constrained autonomous systems. However, super resolution incurs a heavy computational cost. Therefore, in this paper, we investigate the following question: Does the robustness of image classifiers suffer if we use tiny super resolution models? To answer this, we first review a recent work called Super-Efficient Super Resolution (SESR) that achieves similar or better image quality than prior art while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. We demonstrate that despite being orders of magnitude smaller than existing models, SESR achieves the same level of robustness as significantly larger networks. Finally, we estimate end-to-end performance of super resolution-based defenses on a commercial Arm Ethos-U55 micro-NPU. Our findings show that SESR achieves nearly 3x higher FPS than a baseline while achieving similar robustness.
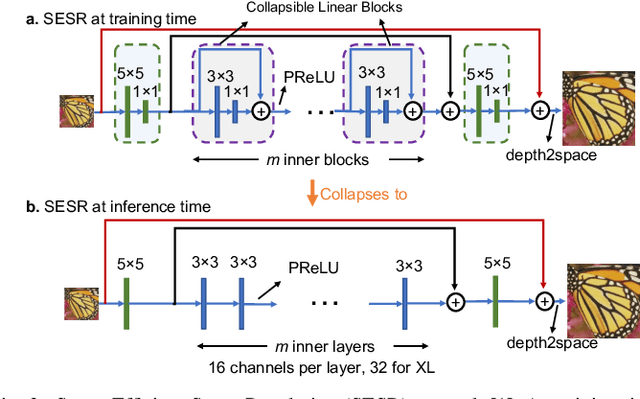
Collapsible Linear Blocks for Super-Efficient Super Resolution
Mar 17, 2021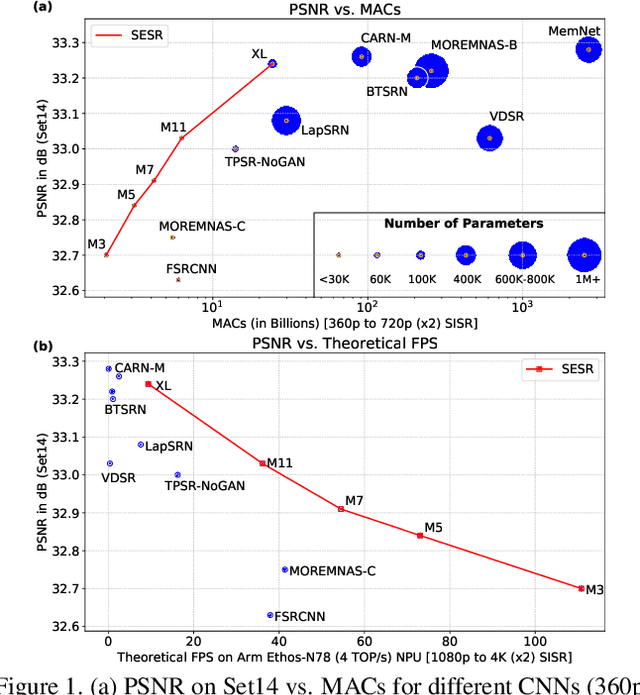
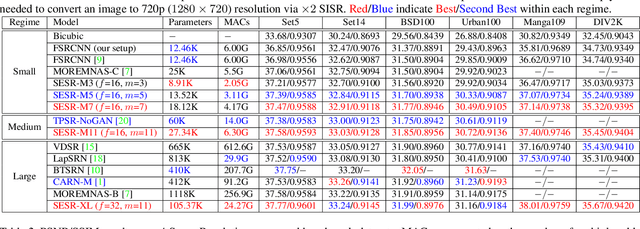
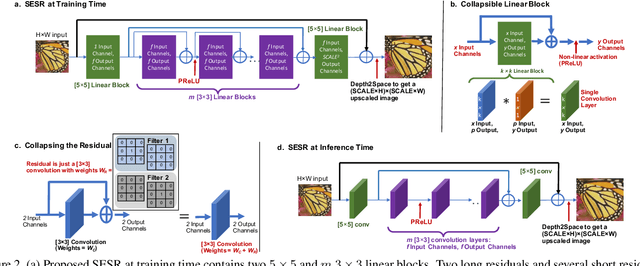
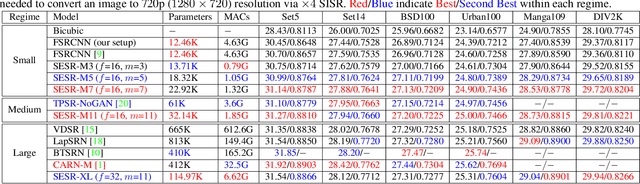
With the advent of smart devices that support 4K and 8K resolution, Single Image Super Resolution (SISR) has become an important computer vision problem. However, most super resolution deep networks are computationally very expensive. In this paper, we propose SESR, a new class of Super-Efficient Super Resolution networks that significantly improve image quality and reduce computational complexity. Detailed experiments across six benchmark datasets demonstrate that SESR achieves similar or better image quality than state-of-the-art models while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. As a result, SESR can be used on constrained hardware to perform x2 (1080p to 4K) and x4 SISR (1080p to 8K). Towards this, we simulate hardware performance numbers for a commercial mobile Neural Processing Unit (NPU) for 1080p to 4K (x2) and 1080p to 8K (x4) SISR. Our results highlight the challenges faced by super resolution on AI accelerators and demonstrate that SESR is significantly faster than existing models. Overall, SESR establishes a new Pareto frontier on the quality (PSNR)-computation relationship for the super resolution task.
MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers
Oct 25, 2020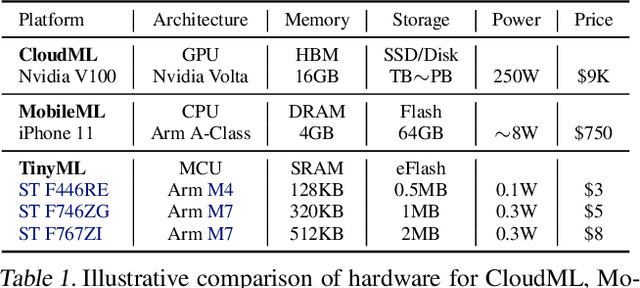
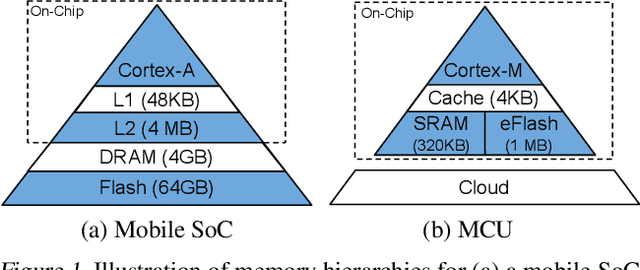
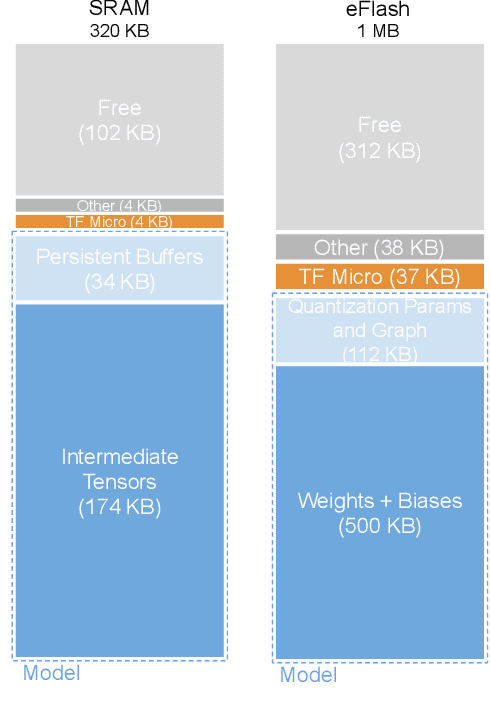
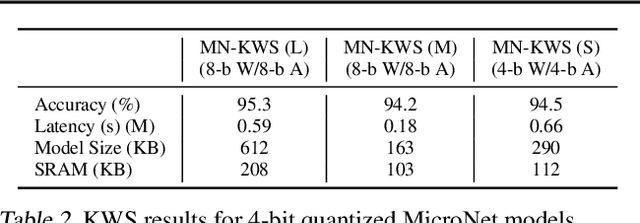
Executing machine learning workloads locally on resource constrained microcontrollers (MCUs) promises to drastically expand the application space of IoT. However, so-called TinyML presents severe technical challenges, as deep neural network inference demands a large compute and memory budget. To address this challenge, neural architecture search (NAS) promises to help design accurate ML models that meet the tight MCU memory, latency and energy constraints. A key component of NAS algorithms is their latency/energy model, i.e., the mapping from a given neural network architecture to its inference latency/energy on an MCU. In this paper, we observe an intriguing property of NAS search spaces for MCU model design: on average, model latency varies linearly with model operation (op) count under a uniform prior over models in the search space. Exploiting this insight, we employ differentiable NAS (DNAS) to search for models with low memory usage and low op count, where op count is treated as a viable proxy to latency. Experimental results validate our methodology, yielding our MicroNet models, which we deploy on MCUs using Tensorflow Lite Micro, a standard open-source NN inference runtime widely used in the TinyML community. MicroNets demonstrate state-of-the-art results for all three TinyMLperf industry-standard benchmark tasks: visual wake words, audio keyword spotting, and anomaly detection.
Rank and run-time aware compression of NLP Applications
Oct 06, 2020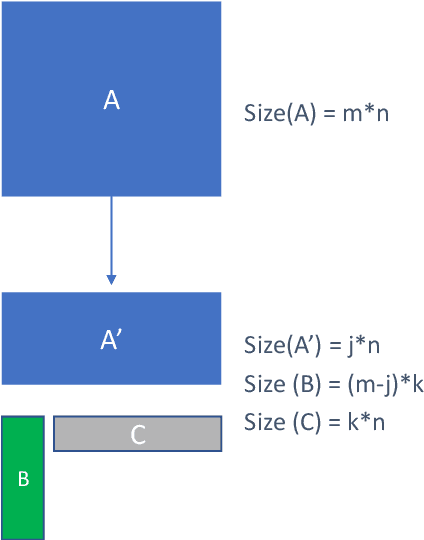
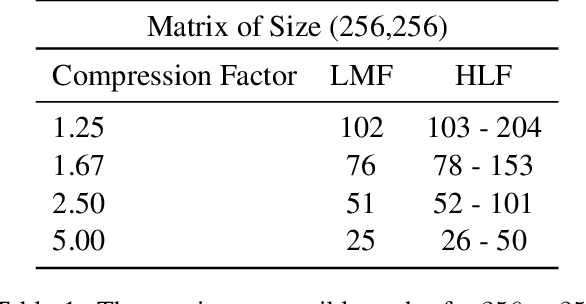
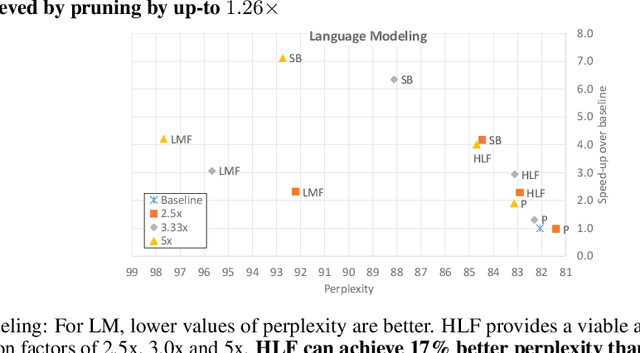
Sequence model based NLP applications can be large. Yet, many applications that benefit from them run on small devices with very limited compute and storage capabilities, while still having run-time constraints. As a result, there is a need for a compression technique that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper proposes a new compression technique called Hybrid Matrix Factorization that achieves this dual objective. HMF improves low-rank matrix factorization (LMF) techniques by doubling the rank of the matrix using an intelligent hybrid-structure leading to better accuracy than LMF. Further, by preserving dense matrices, it leads to faster inference run-time than pruning or structure matrix based compression technique. We evaluate the impact of this technique on 5 NLP benchmarks across multiple tasks (Translation, Intent Detection, Language Modeling) and show that for similar accuracy values and compression factors, HMF can achieve more than 2.32x faster inference run-time than pruning and 16.77% better accuracy than LMF.
High Throughput Matrix-Matrix Multiplication between Asymmetric Bit-Width Operands
Aug 03, 2020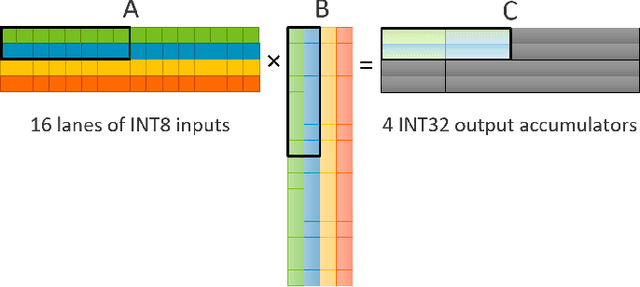
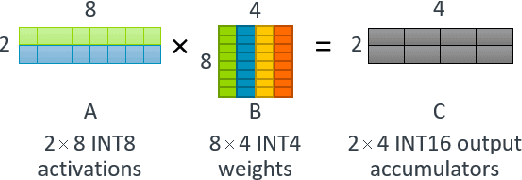
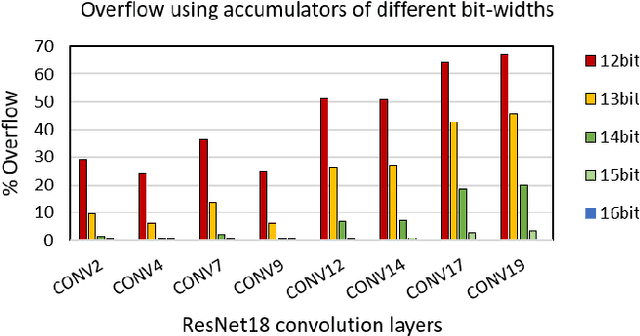
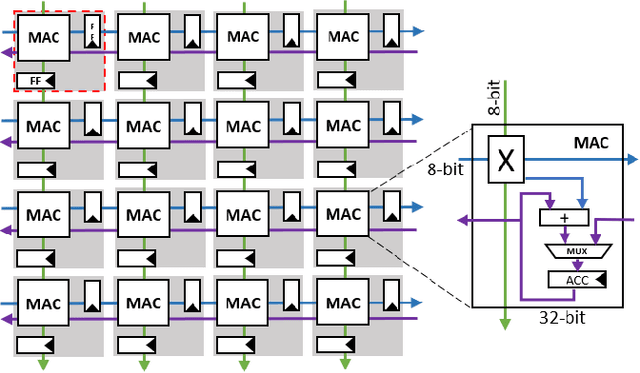
Matrix multiplications between asymmetric bit-width operands, especially between 8- and 4-bit operands are likely to become a fundamental kernel of many important workloads including neural networks and machine learning. While existing SIMD matrix multiplication instructions for symmetric bit-width operands can support operands of mixed precision by zero- or sign-extending the narrow operand to match the size of the other operands, they cannot exploit the benefit of narrow bit-width of one of the operands. We propose a new SIMD matrix multiplication instruction that uses mixed precision on its inputs (8- and 4-bit operands) and accumulates product values into narrower 16-bit output accumulators, in turn allowing the SIMD operation at 128-bit vector width to process a greater number of data elements per instruction to improve processing throughput and memory bandwidth utilization without increasing the register read- and write-port bandwidth in CPUs. The proposed asymmetric-operand-size SIMD instruction offers 2x improvement in throughput of matrix multiplication in comparison to throughput obtained using existing symmetric-operand-size instructions while causing negligible (0.05%) overflow from 16-bit accumulators for representative machine learning workloads. The asymmetric-operand-size instruction not only can improve matrix multiplication throughput in CPUs, but also can be effective to support multiply-and-accumulate (MAC) operation between 8- and 4-bit operands in state-of-the-art DNN hardware accelerators (e.g., systolic array microarchitecture in Google TPU, etc.) and offer similar improvement in matrix multiply performance seamlessly without violating the various implementation constraints. We demonstrate how a systolic array architecture designed for symmetric-operand-size instructions could be modified to support an asymmetric-operand-sized instruction.