 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Principles for Lifelong Learning AI Accelerators
Oct 05, 2023Lifelong learning - an agent's ability to learn throughout its lifetime - is a hallmark of biological learning systems and a central challenge for artificial intelligence (AI). The development of lifelong learning algorithms could lead to a range of novel AI applications, but this will also require the development of appropriate hardware accelerators, particularly if the models are to be deployed on edge platforms, which have strict size, weight, and power constraints. Here, we explore the design of lifelong learning AI accelerators that are intended for deployment in untethered environments. We identify key desirable capabilities for lifelong learning accelerators and highlight metrics to evaluate such accelerators. We then discuss current edge AI accelerators and explore the future design of lifelong learning accelerators, considering the role that different emerging technologies could play.
UDC: Unified DNAS for Compressible TinyML Models
Jan 21, 2022
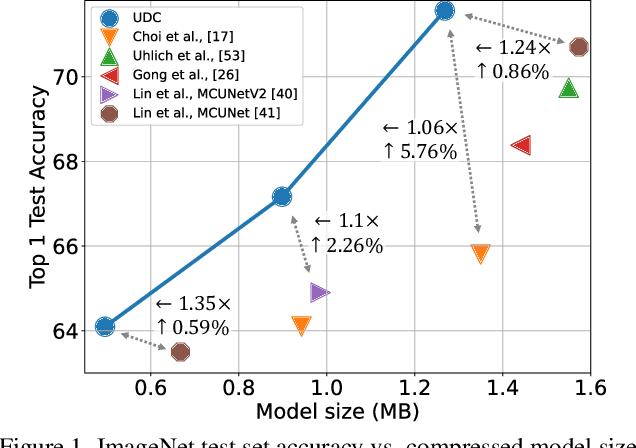
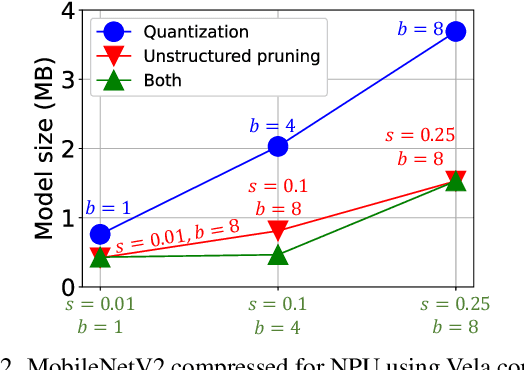
Emerging Internet-of-things (IoT) applications are driving deployment of neural networks (NNs) on heavily constrained low-cost hardware (HW) platforms, where accuracy is typically limited by memory capacity. To address this TinyML challenge, new HW platforms like neural processing units (NPUs) have support for model compression, which exploits aggressive network quantization and unstructured pruning optimizations. The combination of NPUs with HW compression and compressible models allows more expressive models in the same memory footprint. However, adding optimizations for compressibility on top of conventional NN architecture choices expands the design space across which we must make balanced trade-offs. This work bridges the gap between NPU HW capability and NN model design, by proposing a neural architecture search (NAS) algorithm to efficiently search a large design space, including: network depth, operator type, layer width, bitwidth, sparsity, and more. Building on differentiable NAS (DNAS) with several key improvements, we demonstrate Unified DNAS for Compressible models (UDC) on CIFAR100, ImageNet, and DIV2K super resolution tasks. On ImageNet, we find Pareto dominant compressible models, which are 1.9x smaller or 5.76% more accurate.
Federated Learning Based on Dynamic Regularization
Nov 09, 2021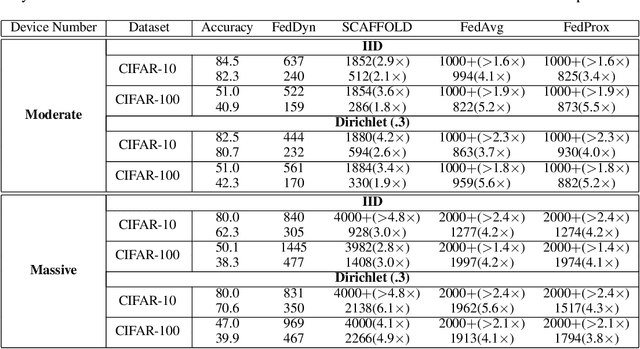
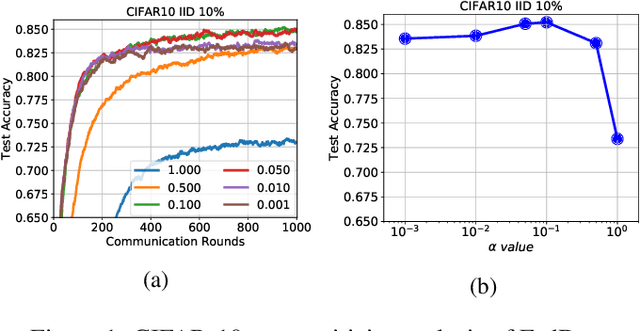
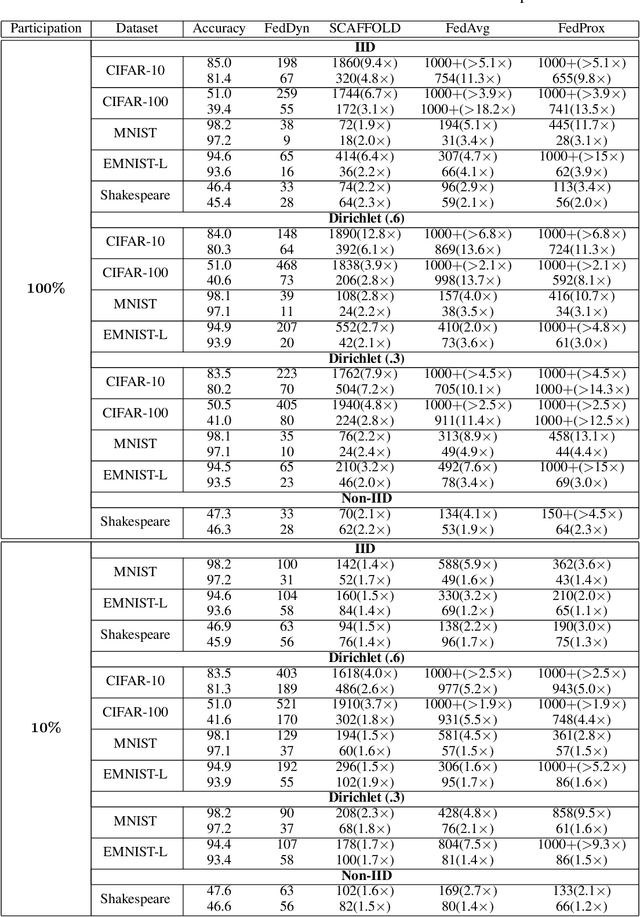
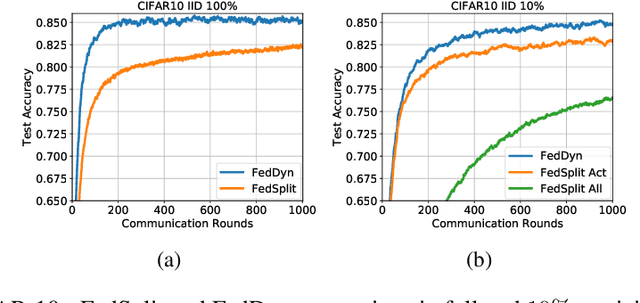
We propose a novel federated learning method for distributively training neural network models, where the server orchestrates cooperation between a subset of randomly chosen devices in each round. We view Federated Learning problem primarily from a communication perspective and allow more device level computations to save transmission costs. We point out a fundamental dilemma, in that the minima of the local-device level empirical loss are inconsistent with those of the global empirical loss. Different from recent prior works, that either attempt inexact minimization or utilize devices for parallelizing gradient computation, we propose a dynamic regularizer for each device at each round, so that in the limit the global and device solutions are aligned. We demonstrate both through empirical results on real and synthetic data as well as analytical results that our scheme leads to efficient training, in both convex and non-convex settings, while being fully agnostic to device heterogeneity and robust to large number of devices, partial participation and unbalanced data.
Towards Efficient Point Cloud Graph Neural Networks Through Architectural Simplification
Aug 13, 2021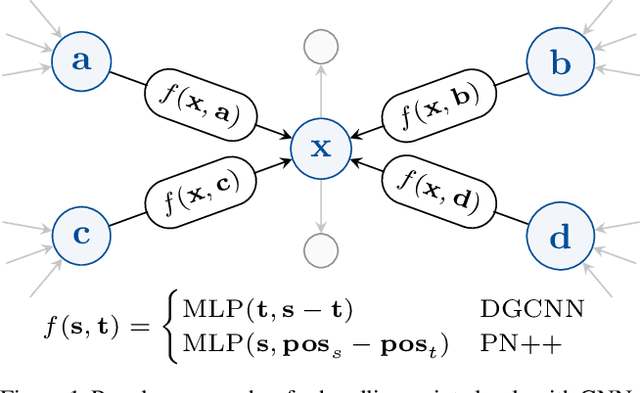
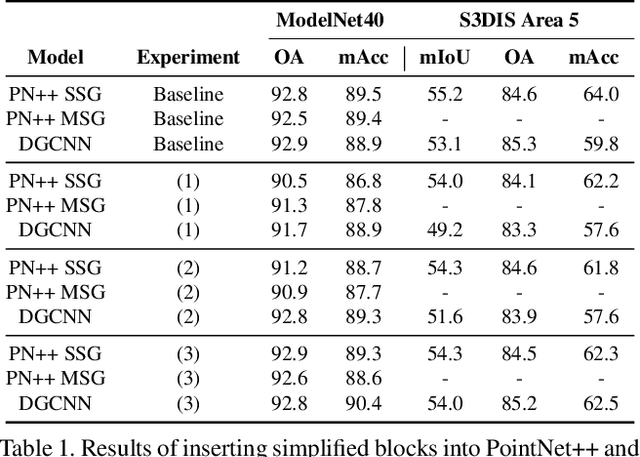

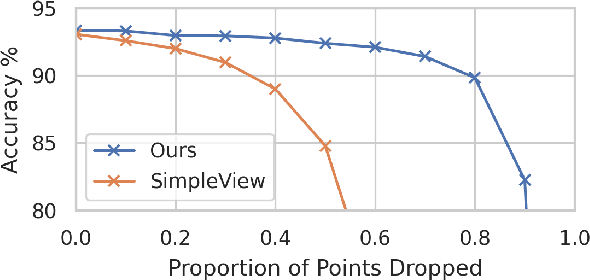
In recent years graph neural network (GNN)-based approaches have become a popular strategy for processing point cloud data, regularly achieving state-of-the-art performance on a variety of tasks. To date, the research community has primarily focused on improving model expressiveness, with secondary thought given to how to design models that can run efficiently on resource constrained mobile devices including smartphones or mixed reality headsets. In this work we make a step towards improving the efficiency of these models by making the observation that these GNN models are heavily limited by the representational power of their first, feature extracting, layer. We find that it is possible to radically simplify these models so long as the feature extraction layer is retained with minimal degradation to model performance; further, we discover that it is possible to improve performance overall on ModelNet40 and S3DIS by improving the design of the feature extractor. Our approach reduces memory consumption by 20$\times$ and latency by up to 9.9$\times$ for graph layers in models such as DGCNN; overall, we achieve speed-ups of up to 4.5$\times$ and peak memory reductions of 72.5%.
S2TA: Exploiting Structured Sparsity for Energy-Efficient Mobile CNN Acceleration
Jul 16, 2021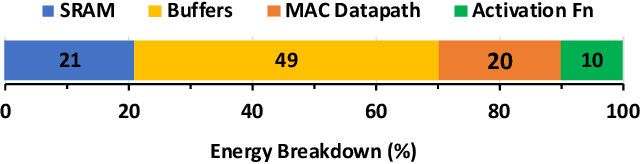
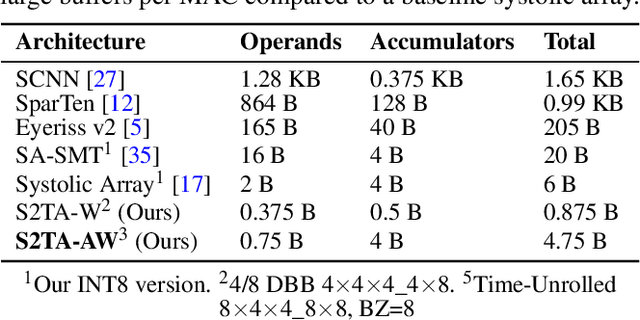
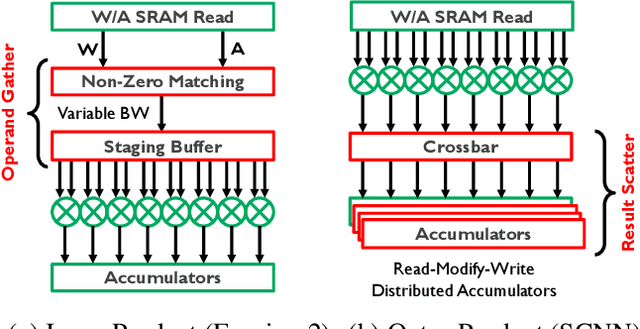
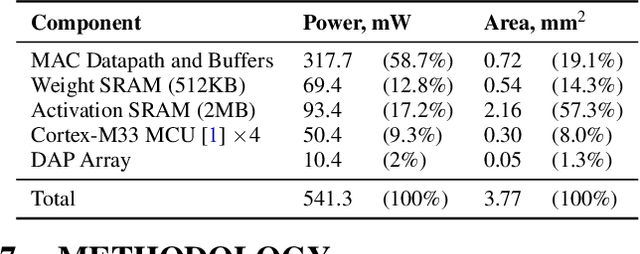
Exploiting sparsity is a key technique in accelerating quantized convolutional neural network (CNN) inference on mobile devices. Prior sparse CNN accelerators largely exploit un-structured sparsity and achieve significant speedups. Due to the unbounded, largely unpredictable sparsity patterns, however, exploiting unstructured sparsity requires complicated hardware design with significant energy and area overhead, which is particularly detrimental to mobile/IoT inference scenarios where energy and area efficiency are crucial. We propose to exploit structured sparsity, more specifically, Density Bound Block (DBB) sparsity for both weights and activations. DBB block tensors bound the maximum number of non-zeros per block. DBB thus exposes statically predictable sparsity patterns that enable lean sparsity-exploiting hardware. We propose new hardware primitives to implement DBB sparsity for (static) weights and (dynamic) activations, respectively, with very low overheads. Building on top of the primitives, we describe S2TA, a systolic array-based CNN accelerator that exploits joint weight and activation DBB sparsity and new dimensions of data reuse unavailable on the traditional systolic array. S2TA in 16nm achieves more than 2x speedup and energy reduction compared to a strong baseline of a systolic array with zero-value clock gating, over five popular CNN benchmarks. Compared to two recent non-systolic sparse accelerators, Eyeriss v2 (65nm) and SparTen (45nm), S2TA in 65nm uses about 2.2x and 3.1x less energy per inference, respectively.
On the Effects of Quantisation on Model Uncertainty in Bayesian Neural Networks
Feb 22, 2021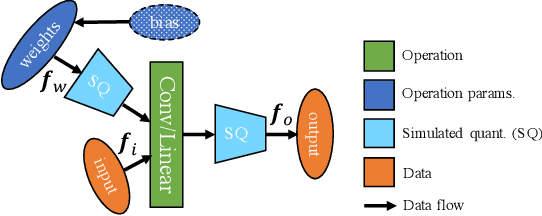


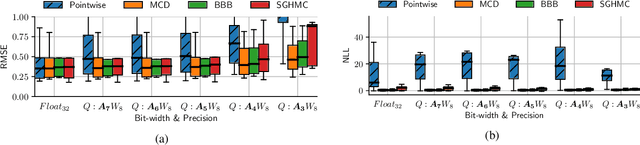
Bayesian neural networks (BNNs) are making significant progress in many research areas where decision making needs to be accompanied by uncertainty estimation. Being able to quantify uncertainty while making decisions is essential for understanding when the model is over-/under-confident, and hence BNNs are attracting interest in safety-critical applications, such as autonomous driving, healthcare and robotics. Nevertheless, BNNs have not been as widely used in industrial practice, mainly because of their increased memory and compute costs. In this work, we investigate quantisation of BNNs by compressing 32-bit floating-point weights and activations to their integer counterparts, that has already been successful in reducing the compute demand in standard pointwise neural networks. We study three types of quantised BNNs, we evaluate them under a wide range of different settings, and we empirically demonstrate that an uniform quantisation scheme applied to BNNs does not substantially decrease their quality of uncertainty estimation.
Doping: A technique for efficient compression of LSTM models using sparse structured additive matrices
Feb 14, 2021
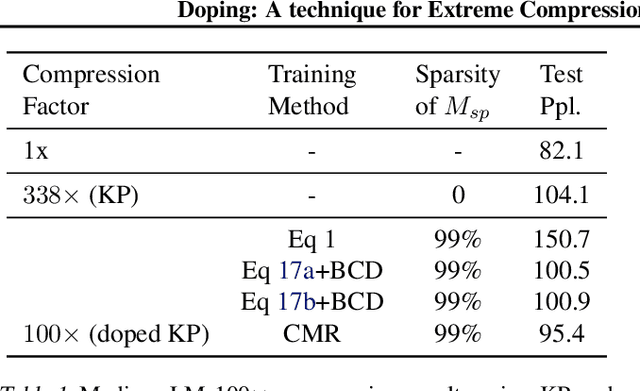
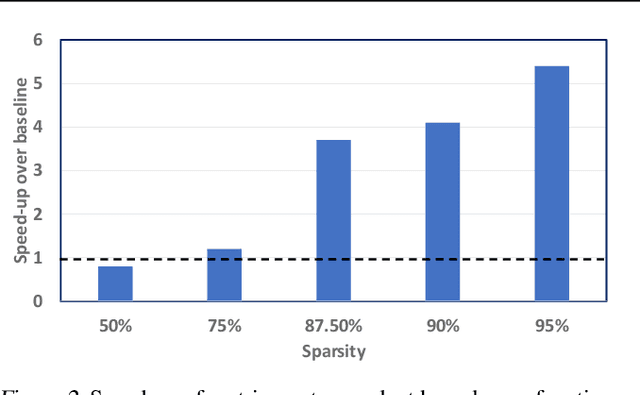

Structured matrices, such as those derived from Kronecker products (KP), are effective at compressing neural networks, but can lead to unacceptable accuracy loss when applied to large models. In this paper, we propose the notion of doping -- addition of an extremely sparse matrix to a structured matrix. Doping facilitates additional degrees of freedom for a small number of parameters, allowing them to independently diverge from the fixed structure. To train LSTMs with doped structured matrices, we introduce the additional parameter matrix while slowly annealing its sparsity level. However, we find that performance degrades as we slowly sparsify the doping matrix, due to co-matrix adaptation (CMA) between the structured and the sparse matrices. We address this over dependence on the sparse matrix using a co-matrix dropout regularization (CMR) scheme. We provide empirical evidence to show that doping, CMA and CMR are concepts generally applicable to multiple structured matrices (Kronecker Product, LMF, Hybrid Matrix Decomposition). Additionally, results with doped kronecker product matrices demonstrate state-of-the-art accuracy at large compression factors (10 - 25x) across 4 natural language processing applications with minor loss in accuracy. Doped KP compression technique outperforms previous state-of-the art compression results by achieving 1.3 - 2.4x higher compression factor at a similar accuracy, while also beating strong alternatives like pruning and low-rank methods by a large margin (8% or more). Additionally, we show that doped KP can be deployed on commodity hardware using the current software stack and achieve 2.5 - 5.5x inference run-time speed-up over baseline.
Information contraction in noisy binary neural networks and its implications
Feb 01, 2021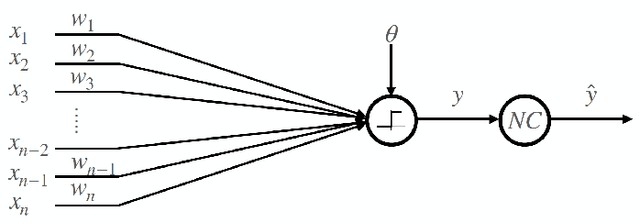
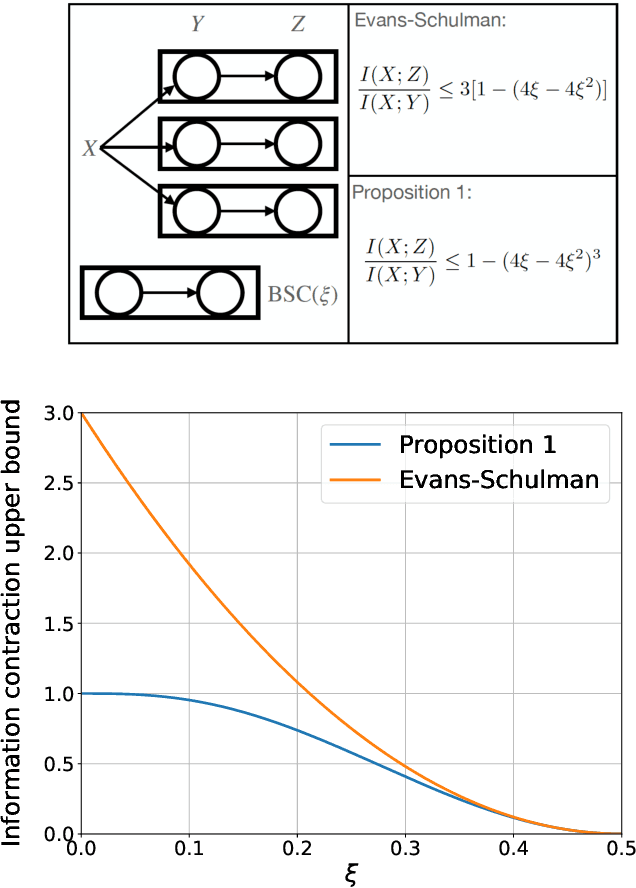
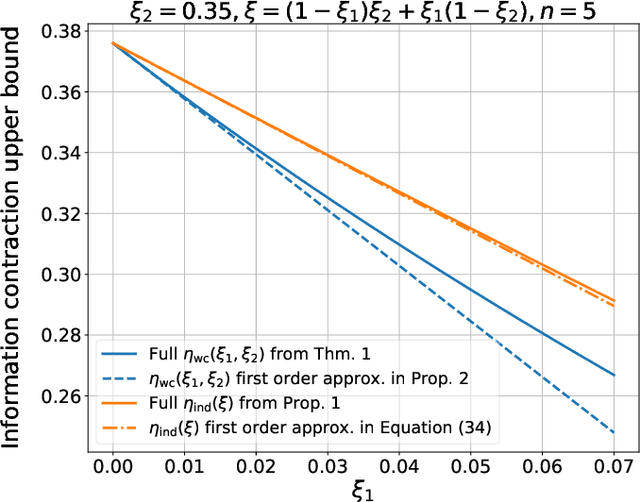
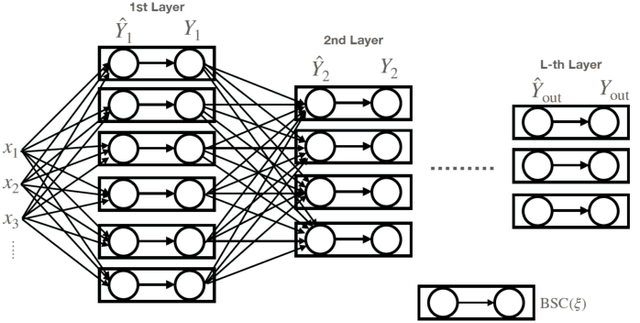
Neural networks have gained importance as the machine learning models that achieve state-of-the-art performance on large-scale image classification, object detection and natural language processing tasks. In this paper, we consider noisy binary neural networks, where each neuron has a non-zero probability of producing an incorrect output. These noisy models may arise from biological, physical and electronic contexts and constitute an important class of models that are relevant to the physical world. Intuitively, the number of neurons in such systems has to grow to compensate for the noise while maintaining the same level of expressive power and computation reliability. Our key finding is a lower bound for the required number of neurons in noisy neural networks, which is first of its kind. To prove this lower bound, we take an information theoretic approach and obtain a novel strong data processing inequality (SDPI), which not only generalizes the Evans-Schulman results for binary symmetric channels to general channels, but also improves the tightness drastically when applied to estimate end-to-end information contraction in networks. Our SDPI can be applied to various information processing systems, including neural networks and cellular automata. Applying the SDPI in noisy binary neural networks, we obtain our key lower bound and investigate its implications on network depth-width trade-offs, our results suggest a depth-width trade-off for noisy neural networks that is very different from the established understanding regarding noiseless neural networks. Furthermore, we apply the SDPI to study fault-tolerant cellular automata and obtain bounds on the error correction overheads and the relaxation time. This paper offers new understanding of noisy information processing systems through the lens of information theory.
MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers
Oct 25, 2020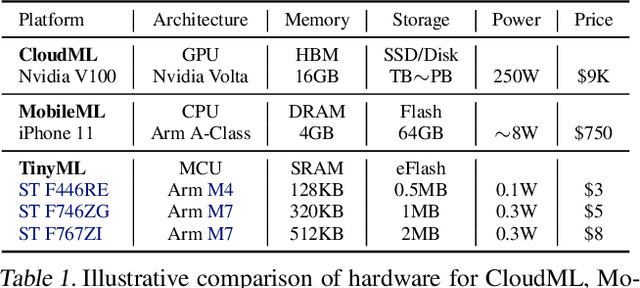
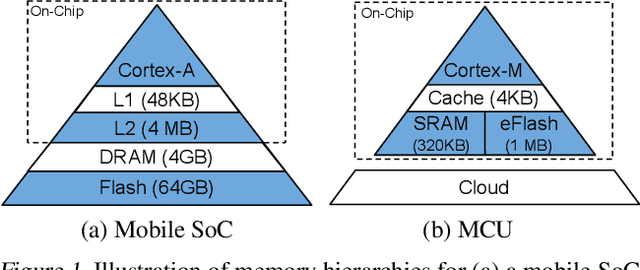
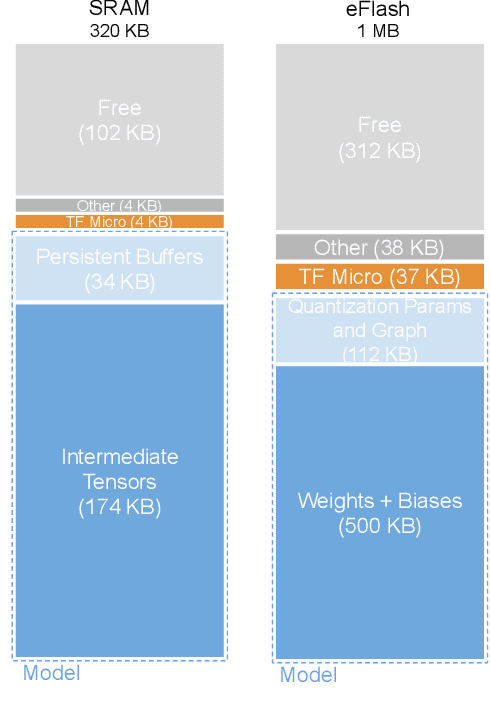
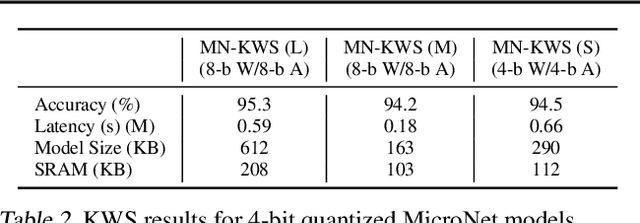
Executing machine learning workloads locally on resource constrained microcontrollers (MCUs) promises to drastically expand the application space of IoT. However, so-called TinyML presents severe technical challenges, as deep neural network inference demands a large compute and memory budget. To address this challenge, neural architecture search (NAS) promises to help design accurate ML models that meet the tight MCU memory, latency and energy constraints. A key component of NAS algorithms is their latency/energy model, i.e., the mapping from a given neural network architecture to its inference latency/energy on an MCU. In this paper, we observe an intriguing property of NAS search spaces for MCU model design: on average, model latency varies linearly with model operation (op) count under a uniform prior over models in the search space. Exploiting this insight, we employ differentiable NAS (DNAS) to search for models with low memory usage and low op count, where op count is treated as a viable proxy to latency. Experimental results validate our methodology, yielding our MicroNet models, which we deploy on MCUs using Tensorflow Lite Micro, a standard open-source NN inference runtime widely used in the TinyML community. MicroNets demonstrate state-of-the-art results for all three TinyMLperf industry-standard benchmark tasks: visual wake words, audio keyword spotting, and anomaly detection.
Rank and run-time aware compression of NLP Applications
Oct 06, 2020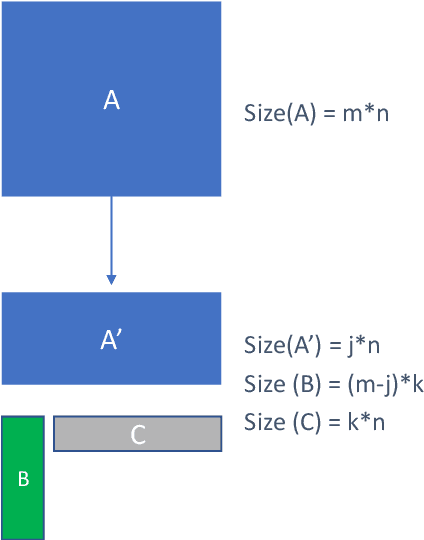
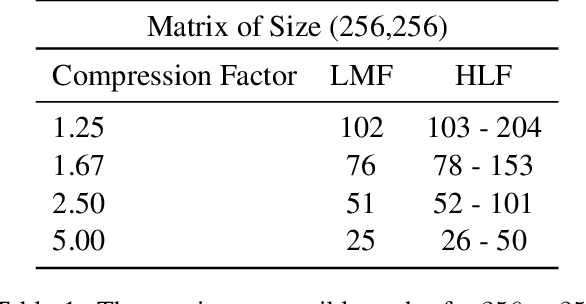
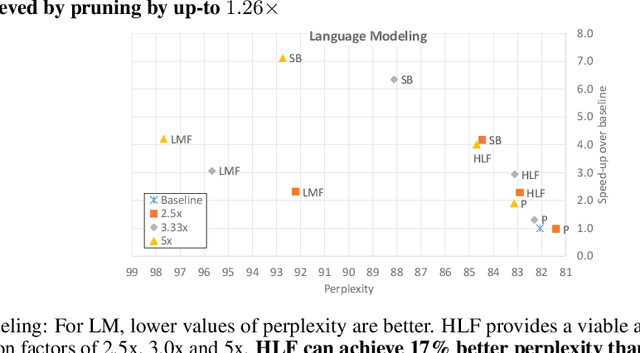
Sequence model based NLP applications can be large. Yet, many applications that benefit from them run on small devices with very limited compute and storage capabilities, while still having run-time constraints. As a result, there is a need for a compression technique that can achieve significant compression without negatively impacting inference run-time and task accuracy. This paper proposes a new compression technique called Hybrid Matrix Factorization that achieves this dual objective. HMF improves low-rank matrix factorization (LMF) techniques by doubling the rank of the matrix using an intelligent hybrid-structure leading to better accuracy than LMF. Further, by preserving dense matrices, it leads to faster inference run-time than pruning or structure matrix based compression technique. We evaluate the impact of this technique on 5 NLP benchmarks across multiple tasks (Translation, Intent Detection, Language Modeling) and show that for similar accuracy values and compression factors, HMF can achieve more than 2.32x faster inference run-time than pruning and 16.77% better accuracy than LMF.