 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2TA: Exploiting Structured Sparsity for Energy-Efficient Mobile CNN Acceleration
Jul 16, 2021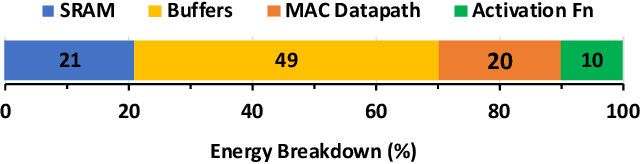
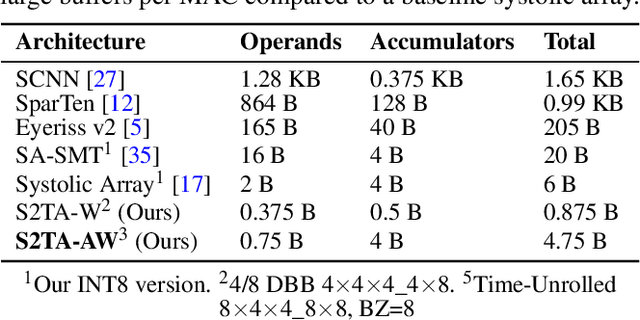
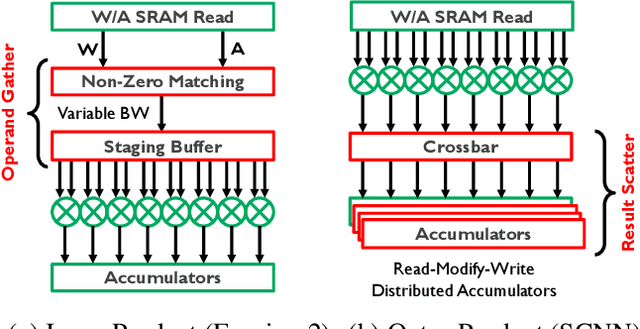
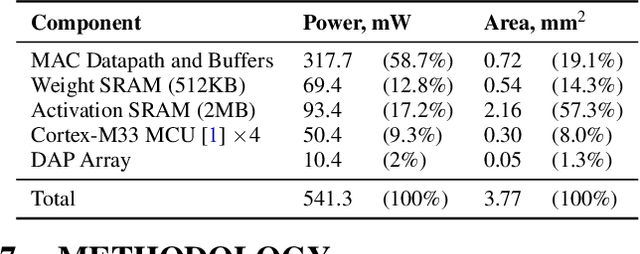
Exploiting sparsity is a key technique in accelerating quantized convolutional neural network (CNN) inference on mobile devices. Prior sparse CNN accelerators largely exploit un-structured sparsity and achieve significant speedups. Due to the unbounded, largely unpredictable sparsity patterns, however, exploiting unstructured sparsity requires complicated hardware design with significant energy and area overhead, which is particularly detrimental to mobile/IoT inference scenarios where energy and area efficiency are crucial. We propose to exploit structured sparsity, more specifically, Density Bound Block (DBB) sparsity for both weights and activations. DBB block tensors bound the maximum number of non-zeros per block. DBB thus exposes statically predictable sparsity patterns that enable lean sparsity-exploiting hardware. We propose new hardware primitives to implement DBB sparsity for (static) weights and (dynamic) activations, respectively, with very low overheads. Building on top of the primitives, we describe S2TA, a systolic array-based CNN accelerator that exploits joint weight and activation DBB sparsity and new dimensions of data reuse unavailable on the traditional systolic array. S2TA in 16nm achieves more than 2x speedup and energy reduction compared to a strong baseline of a systolic array with zero-value clock gating, over five popular CNN benchmarks. Compared to two recent non-systolic sparse accelerators, Eyeriss v2 (65nm) and SparTen (45nm), S2TA in 65nm uses about 2.2x and 3.1x less energy per inference, respectively.
Sparse Systolic Tensor Array for Efficient CNN Hardware Acceleration
Sep 04, 2020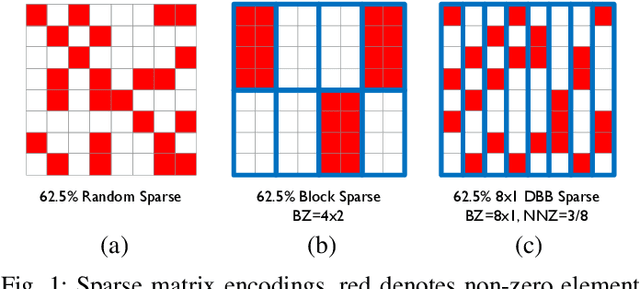
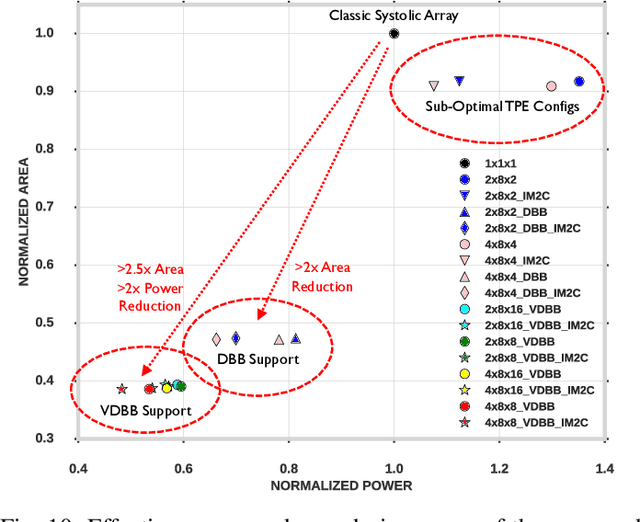

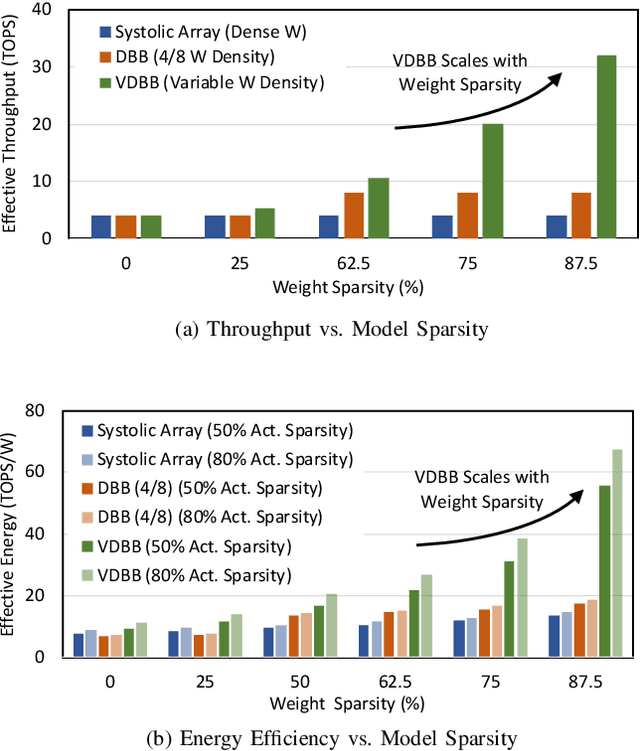
Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). Exploiting data sparsity is a common approach to further accelerate GEMM for CNN inference, and in particular, structural sparsity has the advantages of predictable load balancing and very low index overhead. In this paper, we address a key architectural challenge with structural sparsity: how to provide support for a range of sparsity levels while maintaining high utilization of the hardware. We describe a time unrolled formulation of variable density-bound block (VDBB) sparsity that allows for a configurable number of non-zero elements per block, at constant utilization. We then describe a systolic array microarchitecture that implements this scheme, with two data reuse optimizations. Firstly, we increase reuse in both operands and partial products by increasing the number of MACs per PE. Secondly, we introduce a novel approach of moving the IM2COL transform into the hardware, which allows us to achieve a 3x data bandwidth expansion just before the operands are consumed by the datapath, reducing the SRAM power consumption. The optimizations for weight sparsity, activation sparsity and data reuse are all interrelated and therefore the optimal combination is not obvious. Therefore, we perform an design space evaluation to find the pareto-optimal design characteristics. The resulting design achieves 16.8 TOPS/W in 16nm with modest 50% model sparsity and scales with model sparsity up to 55.7TOPS/W at 87.5%. As well as successfully demonstrating the variable DBB technique, this result significantly outperforms previously reported sparse CNN accelerators.
Efficient Residue Number System Based Winograd Convolution
Jul 23, 2020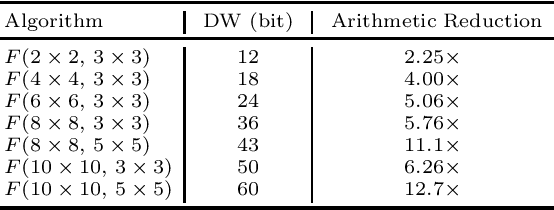
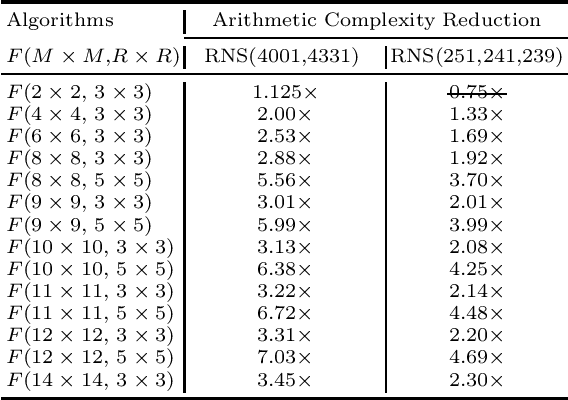
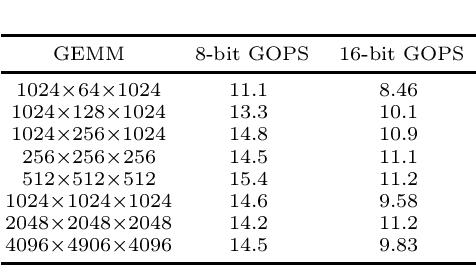
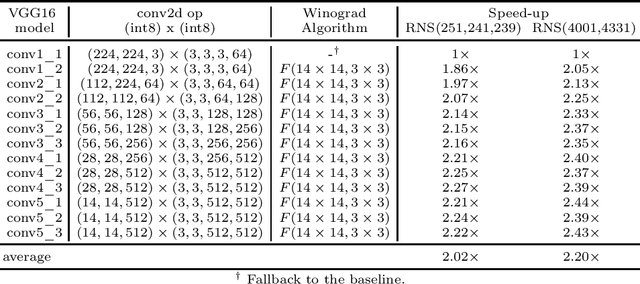
Prior research has shown that Winograd algorithm can reduce the computational complexity of convolutional neural networks (CNN) with weights and activations represented in floating point. However it is difficult to apply the scheme to the inference of low-precision quantized (e.g. INT8) networks. Our work extends the Winograd algorithm to Residue Number System (RNS). The minimal complexity convolution is computed precisely over large transformation tile (e.g. 10 x 10 to 16 x 16) of filters and activation patches using the Winograd transformation and low cost (e.g. 8-bit) arithmetic without degrading the prediction accuracy of the networks during inference. The arithmetic complexity reduction is up to 7.03x while the performance improvement is up to 2.30x to 4.69x for 3 x 3 and 5 x 5 filters respectively.
Systolic Tensor Array: An Efficient Structured-Sparse GEMM Accelerator for Mobile CNN Inference
May 16, 2020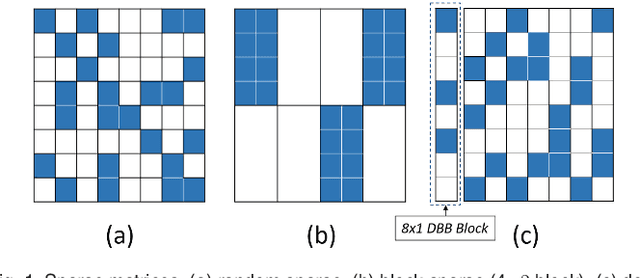
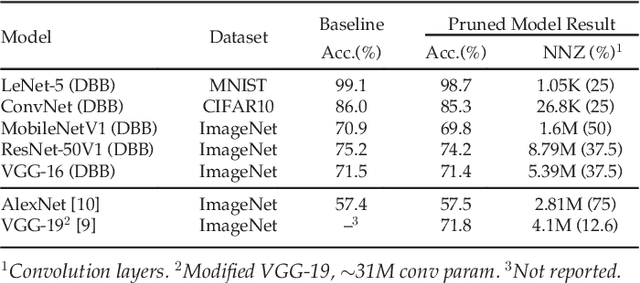
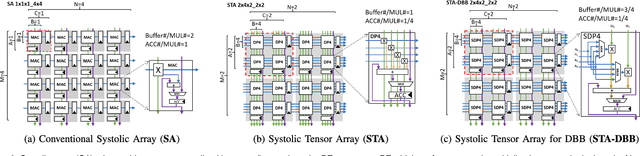

Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). The systolic array (SA) is a pipelined 2D array of processing elements (PEs), with very efficient local data movement, well suited to accelerating GEMM, and widely deployed in industry. In this work, we describe two significant improvements to the traditional SA architecture, to specifically optimize for CNN inference. Firstly, we generalize the traditional scalar PE, into a Tensor-PE, which gives rise to a family of new Systolic Tensor Array (STA) microarchitectures. The STA family increases intra-PE operand reuse and datapath efficiency, resulting in circuit area and power dissipation reduction of as much as 2.08x and 1.36x respectively, compared to the conventional SA at iso-throughput with INT8 operands. Secondly, we extend this design to support a novel block-sparse data format called density-bound block (DBB). This variant (STA-DBB) achieves a 3.14x and 1.97x improvement over the SA baseline at iso-throughput in area and power respectively, when processing specially-trained DBB-sparse models, while remaining fully backwards compatible with dense models.
Learning low-precision neural networks without Straight-Through Estimator(STE)
Mar 04, 2019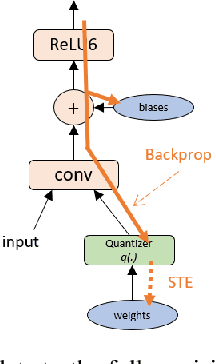
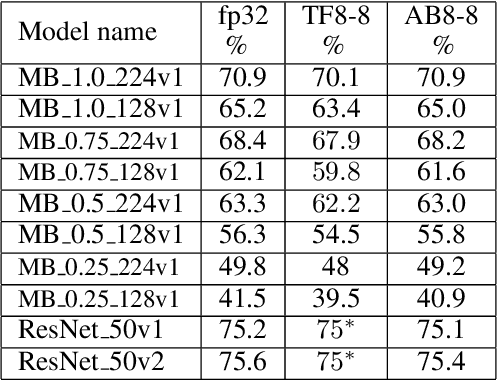
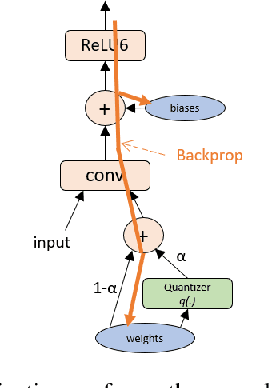
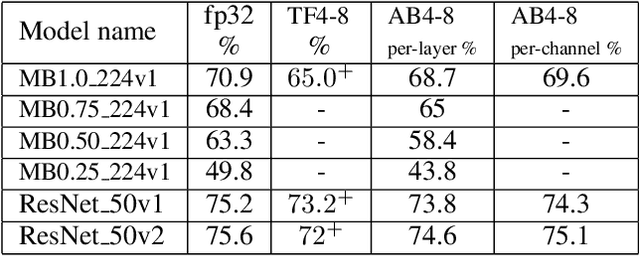
The Straight-Through Estimator (STE) is widely used for back-propagating gradients through the quantization function, but the STE technique lacks a complete theoretical understanding. We propose an alternative methodology called alpha-blending (AB), which quantizes neural networks to low-precision using stochastic gradient descent (SGD). Our method (AB) avoids STE approximation by replacing the quantized weight in the loss function by an affine combination of the quantized weight w_q and the corresponding full-precision weight w with non-trainable scalar coefficient $\alpha$ and $1-\alpha$. During training, $\alpha$ is gradually increased from 0 to 1; the gradient updates to the weights are through the full-precision term, $(1-\alpha)w$, of the affine combination; the model is converted from full-precision to low-precision progressively. To evaluate the method, a 1-bit BinaryNet on CIFAR10 dataset and 8-bits, 4-bits MobileNet v1, ResNet_50 v1/2 on ImageNet dataset are trained using the alpha-blending approach, and the evaluation indicates that AB improves top-1 accuracy by 0.9%, 0.82% and 2.93% respectively compared to the results of STE based quantization.