 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaVa: Latent Reasoning via Compressed KV-Cache Distillation
Oct 02, 2025Large Language Models (LLMs) excel at multi-step reasoning problems with explicit chain-of-thought (CoT), but verbose traces incur significant computational costs and memory overhead, and often carry redundant, stylistic artifacts. Latent reasoning has emerged as an efficient alternative that internalizes the thought process, but it suffers from a critical lack of supervision, limiting its effectiveness on complex, natural-language reasoning traces. In this work, we propose KaVa, the first framework that bridges this gap by distilling knowledge directly from a compressed KV-cache of the teacher into a latent-reasoning student via self-distillation, leveraging the representational flexibility of continuous latent tokens to align stepwise KV trajectories. We show that the abstract, unstructured knowledge within compressed KV-cache, which lacks direct token correspondence, can serve as a rich supervisory signal for a latent reasoning student. Empirically, the approach consistently outperforms strong latent baselines, exhibits markedly smaller degradation from equation-only to natural-language traces, and scales to larger backbones while preserving efficiency. These results establish compressed KV-cache distillation as a scalable supervision signal for latent reasoning, combining the accuracy of CoT-trained teachers with the efficiency and deployability of latent inference.
AnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021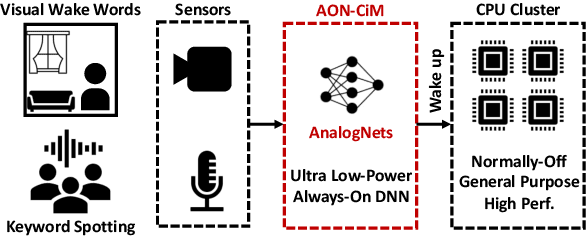
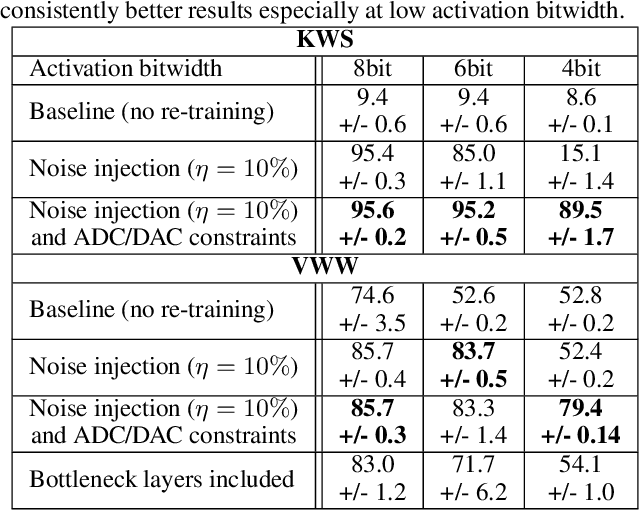
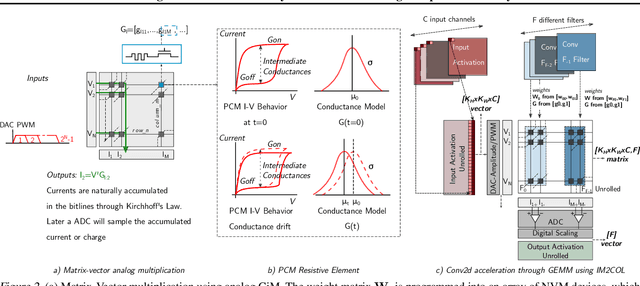
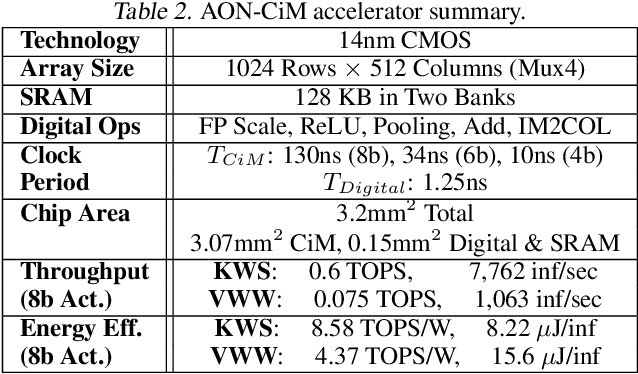
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.
Federated Learning Based on Dynamic Regularization
Nov 09, 2021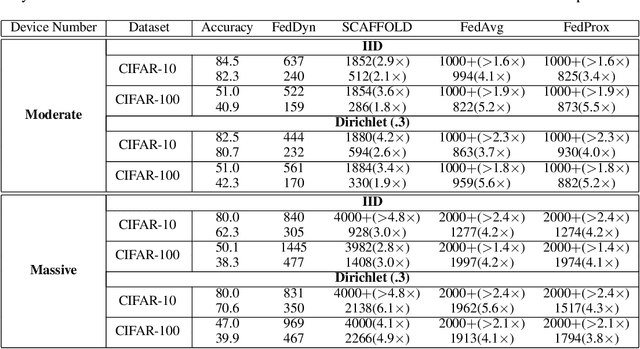
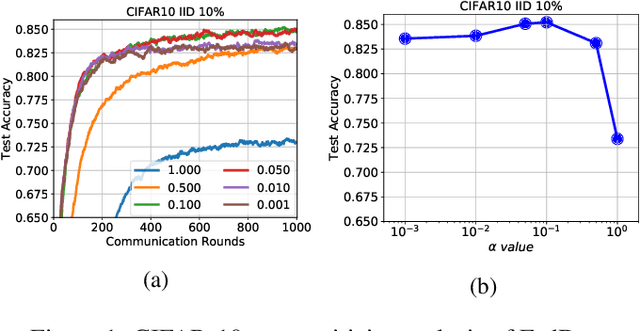
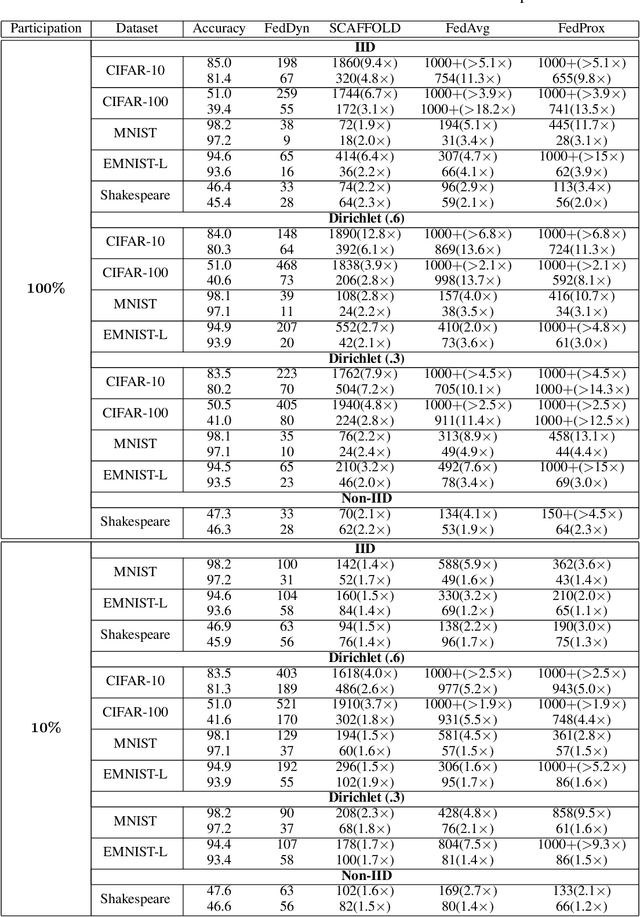
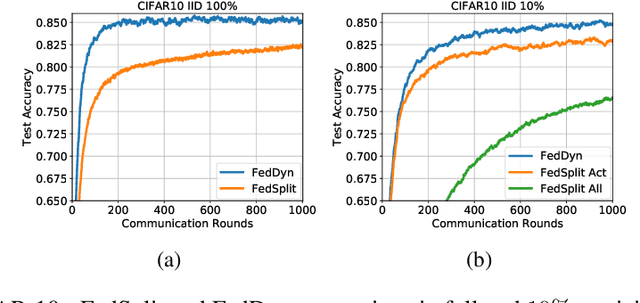
We propose a novel federated learning method for distributively training neural network models, where the server orchestrates cooperation between a subset of randomly chosen devices in each round. We view Federated Learning problem primarily from a communication perspective and allow more device level computations to save transmission costs. We point out a fundamental dilemma, in that the minima of the local-device level empirical loss are inconsistent with those of the global empirical loss. Different from recent prior works, that either attempt inexact minimization or utilize devices for parallelizing gradient computation, we propose a dynamic regularizer for each device at each round, so that in the limit the global and device solutions are aligned. We demonstrate both through empirical results on real and synthetic data as well as analytical results that our scheme leads to efficient training, in both convex and non-convex settings, while being fully agnostic to device heterogeneity and robust to large number of devices, partial participation and unbalanced data.
S2TA: Exploiting Structured Sparsity for Energy-Efficient Mobile CNN Acceleration
Jul 16, 2021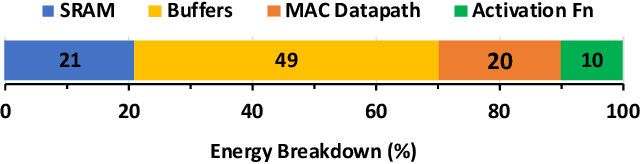
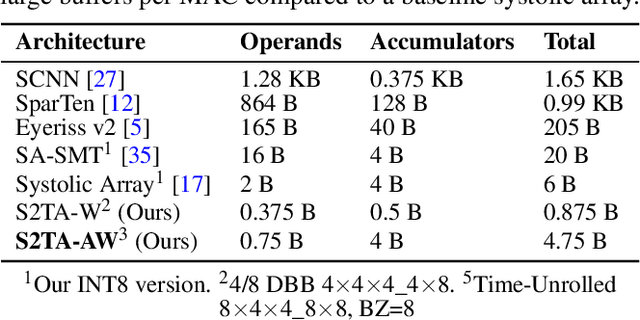
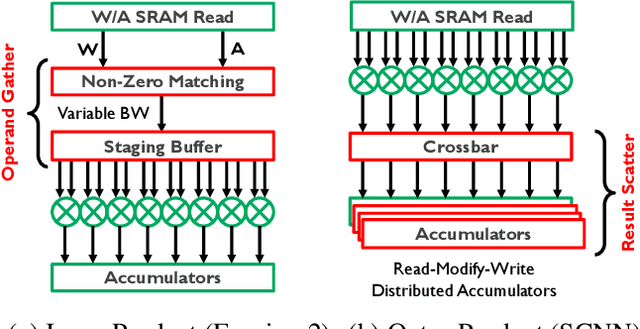
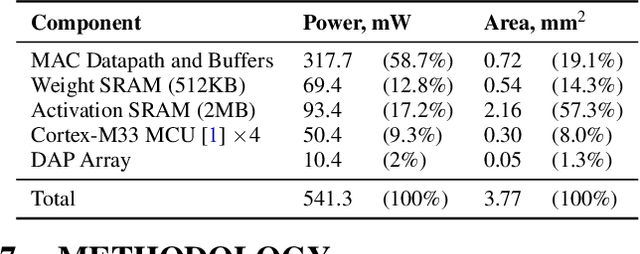
Exploiting sparsity is a key technique in accelerating quantized convolutional neural network (CNN) inference on mobile devices. Prior sparse CNN accelerators largely exploit un-structured sparsity and achieve significant speedups. Due to the unbounded, largely unpredictable sparsity patterns, however, exploiting unstructured sparsity requires complicated hardware design with significant energy and area overhead, which is particularly detrimental to mobile/IoT inference scenarios where energy and area efficiency are crucial. We propose to exploit structured sparsity, more specifically, Density Bound Block (DBB) sparsity for both weights and activations. DBB block tensors bound the maximum number of non-zeros per block. DBB thus exposes statically predictable sparsity patterns that enable lean sparsity-exploiting hardware. We propose new hardware primitives to implement DBB sparsity for (static) weights and (dynamic) activations, respectively, with very low overheads. Building on top of the primitives, we describe S2TA, a systolic array-based CNN accelerator that exploits joint weight and activation DBB sparsity and new dimensions of data reuse unavailable on the traditional systolic array. S2TA in 16nm achieves more than 2x speedup and energy reduction compared to a strong baseline of a systolic array with zero-value clock gating, over five popular CNN benchmarks. Compared to two recent non-systolic sparse accelerators, Eyeriss v2 (65nm) and SparTen (45nm), S2TA in 65nm uses about 2.2x and 3.1x less energy per inference, respectively.
A LiDAR-Guided Framework for Video Enhancement
Mar 15, 2021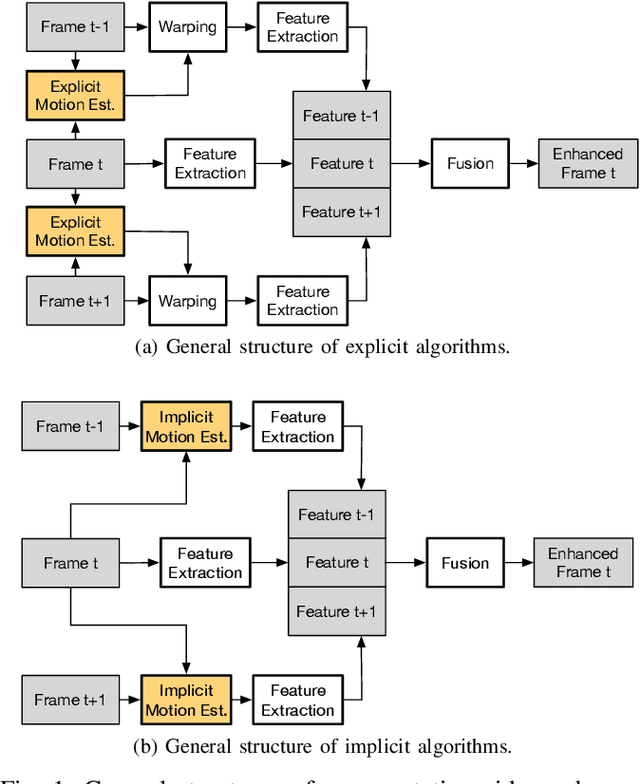

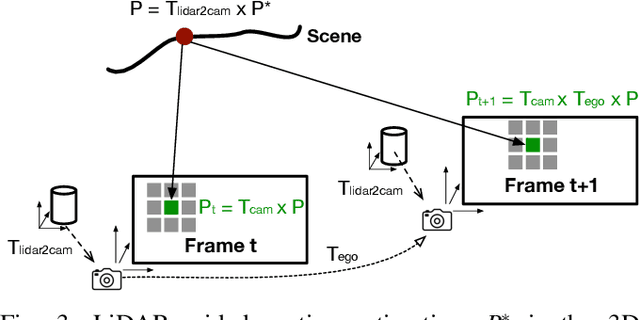

This paper presents a general framework that simultaneously improves the quality and the execution speed of a range of video enhancement tasks, such as super-sampling, deblurring, and denoising. The key to our framework is a pixel motion estimation algorithm that generates accurate motion from low-quality videos while being computationally very lightweight. Our motion estimation algorithm leverages point cloud information, which is readily available in today's autonomous devices and will only become more common in the future. We demonstrate a generic framework that leverages the motion information to guide high-quality image reconstruction. Experiments show that our framework consistently outperforms the state-of-the-art video enhancement algorithms while improving the execution speed by an order of magnitude.
Doping: A technique for efficient compression of LSTM models using sparse structured additive matrices
Feb 14, 2021
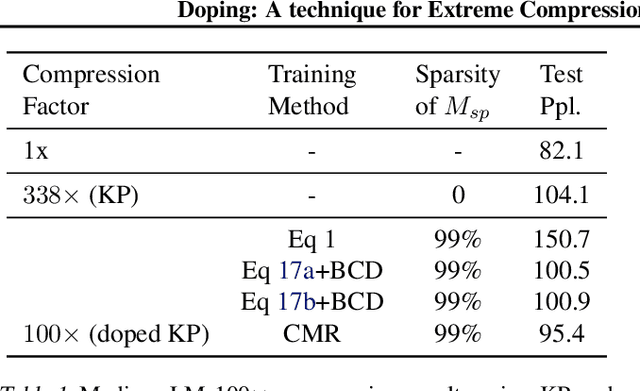

Structured matrices, such as those derived from Kronecker products (KP), are effective at compressing neural networks, but can lead to unacceptable accuracy loss when applied to large models. In this paper, we propose the notion of doping -- addition of an extremely sparse matrix to a structured matrix. Doping facilitates additional degrees of freedom for a small number of parameters, allowing them to independently diverge from the fixed structure. To train LSTMs with doped structured matrices, we introduce the additional parameter matrix while slowly annealing its sparsity level. However, we find that performance degrades as we slowly sparsify the doping matrix, due to co-matrix adaptation (CMA) between the structured and the sparse matrices. We address this over dependence on the sparse matrix using a co-matrix dropout regularization (CMR) scheme. We provide empirical evidence to show that doping, CMA and CMR are concepts generally applicable to multiple structured matrices (Kronecker Product, LMF, Hybrid Matrix Decomposition). Additionally, results with doped kronecker product matrices demonstrate state-of-the-art accuracy at large compression factors (10 - 25x) across 4 natural language processing applications with minor loss in accuracy. Doped KP compression technique outperforms previous state-of-the art compression results by achieving 1.3 - 2.4x higher compression factor at a similar accuracy, while also beating strong alternatives like pruning and low-rank methods by a large margin (8% or more). Additionally, we show that doped KP can be deployed on commodity hardware using the current software stack and achieve 2.5 - 5.5x inference run-time speed-up over baseline.
Information contraction in noisy binary neural networks and its implications
Feb 01, 2021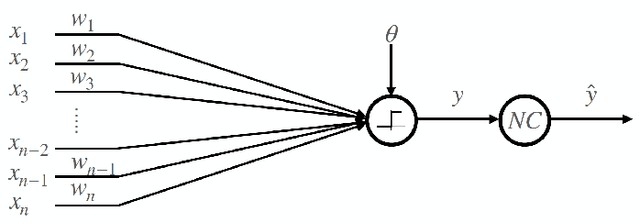
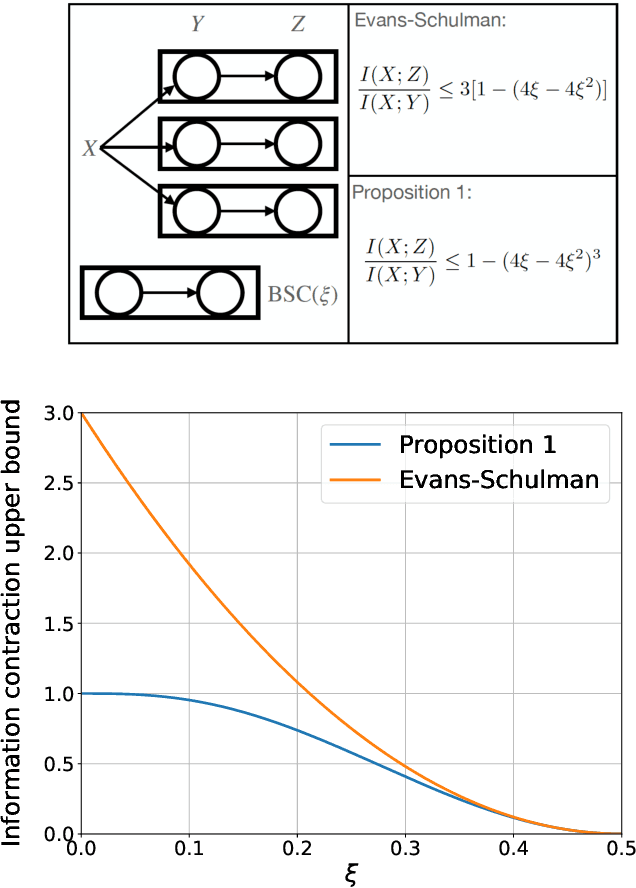
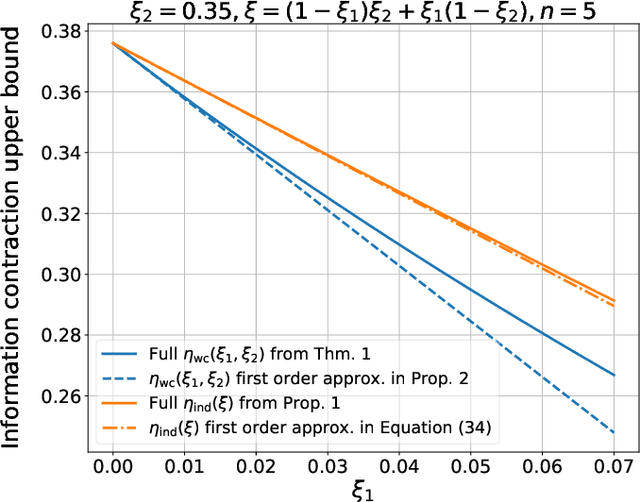
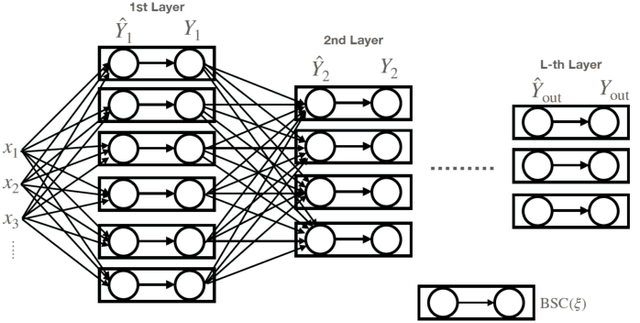
Neural networks have gained importance as the machine learning models that achieve state-of-the-art performance on large-scale image classification, object detection and natural language processing tasks. In this paper, we consider noisy binary neural networks, where each neuron has a non-zero probability of producing an incorrect output. These noisy models may arise from biological, physical and electronic contexts and constitute an important class of models that are relevant to the physical world. Intuitively, the number of neurons in such systems has to grow to compensate for the noise while maintaining the same level of expressive power and computation reliability. Our key finding is a lower bound for the required number of neurons in noisy neural networks, which is first of its kind. To prove this lower bound, we take an information theoretic approach and obtain a novel strong data processing inequality (SDPI), which not only generalizes the Evans-Schulman results for binary symmetric channels to general channels, but also improves the tightness drastically when applied to estimate end-to-end information contraction in networks. Our SDPI can be applied to various information processing systems, including neural networks and cellular automata. Applying the SDPI in noisy binary neural networks, we obtain our key lower bound and investigate its implications on network depth-width trade-offs, our results suggest a depth-width trade-off for noisy neural networks that is very different from the established understanding regarding noiseless neural networks. Furthermore, we apply the SDPI to study fault-tolerant cellular automata and obtain bounds on the error correction overheads and the relaxation time. This paper offers new understanding of noisy information processing systems through the lens of information theory.
MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers
Oct 25, 2020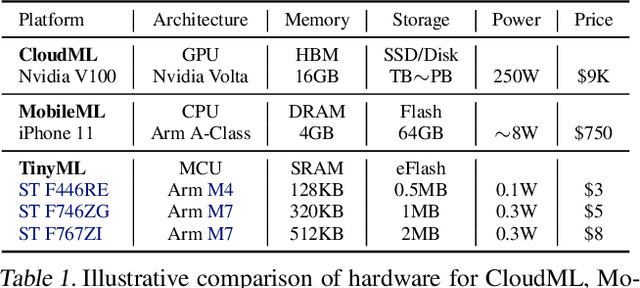
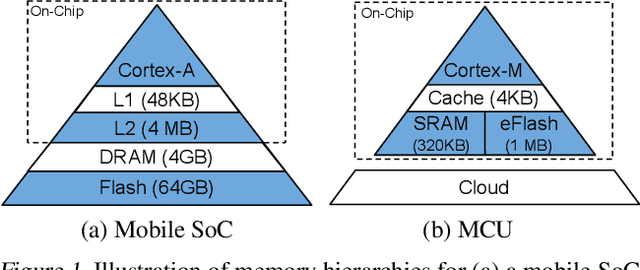
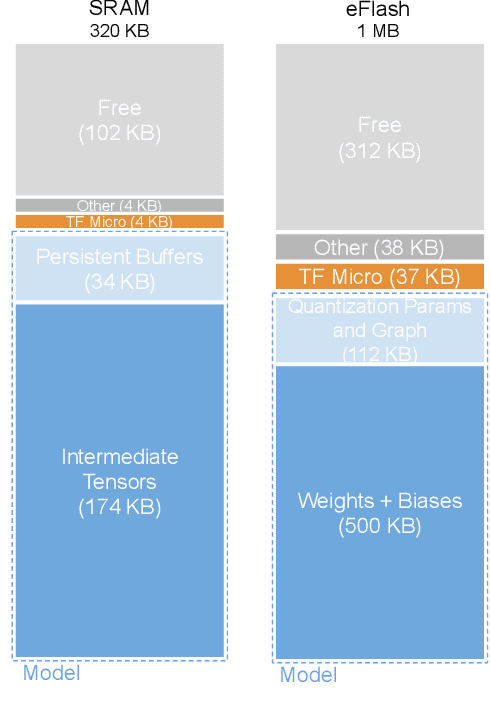
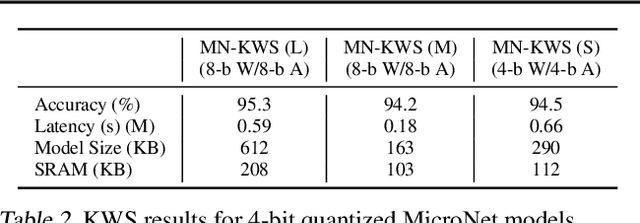
Executing machine learning workloads locally on resource constrained microcontrollers (MCUs) promises to drastically expand the application space of IoT. However, so-called TinyML presents severe technical challenges, as deep neural network inference demands a large compute and memory budget. To address this challenge, neural architecture search (NAS) promises to help design accurate ML models that meet the tight MCU memory, latency and energy constraints. A key component of NAS algorithms is their latency/energy model, i.e., the mapping from a given neural network architecture to its inference latency/energy on an MCU. In this paper, we observe an intriguing property of NAS search spaces for MCU model design: on average, model latency varies linearly with model operation (op) count under a uniform prior over models in the search space. Exploiting this insight, we employ differentiable NAS (DNAS) to search for models with low memory usage and low op count, where op count is treated as a viable proxy to latency. Experimental results validate our methodology, yielding our MicroNet models, which we deploy on MCUs using Tensorflow Lite Micro, a standard open-source NN inference runtime widely used in the TinyML community. MicroNets demonstrate state-of-the-art results for all three TinyMLperf industry-standard benchmark tasks: visual wake words, audio keyword spotting, and anomaly detection.
Sparse Systolic Tensor Array for Efficient CNN Hardware Acceleration
Sep 04, 2020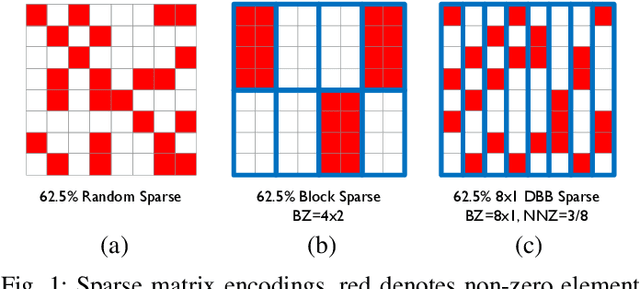
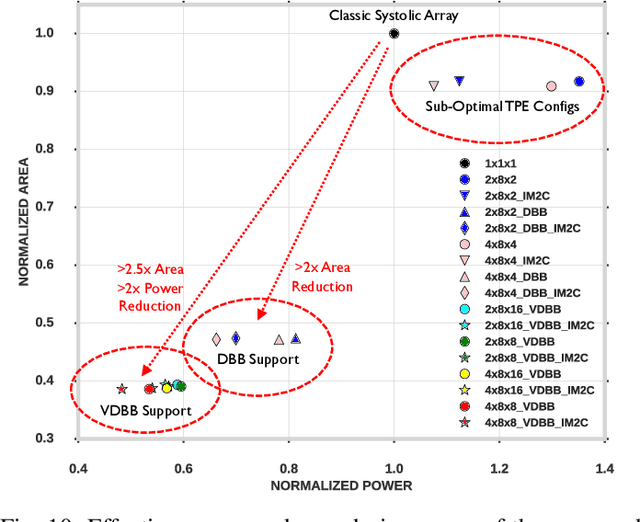

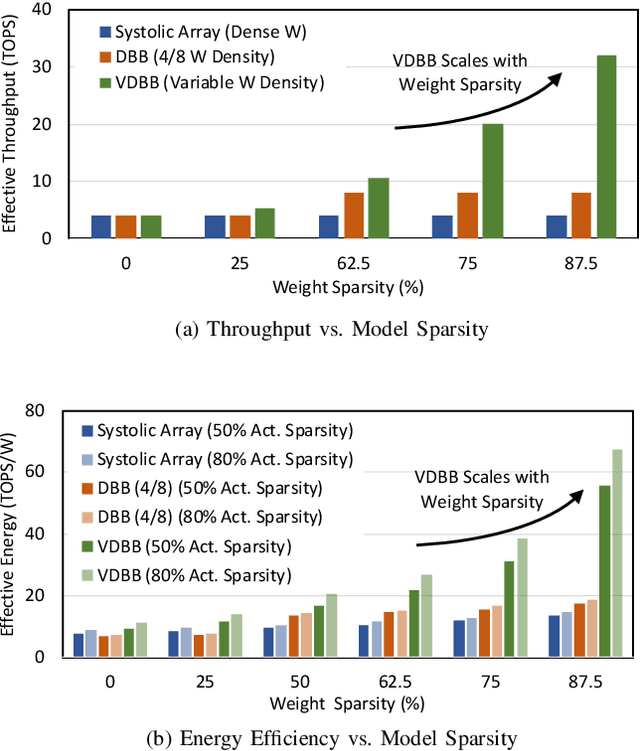
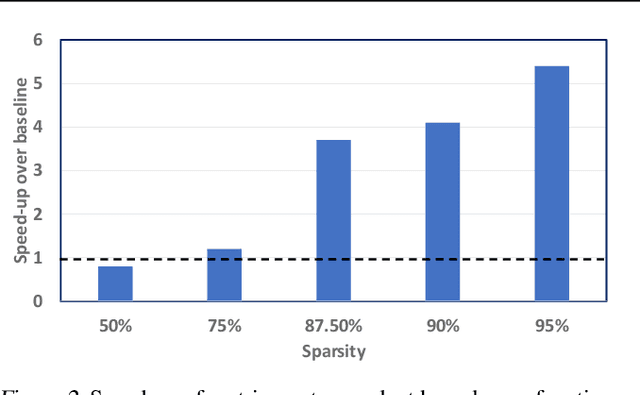
Convolutional neural network (CNN) inference on mobile devices demands efficient hardware acceleration of low-precision (INT8) general matrix multiplication (GEMM). Exploiting data sparsity is a common approach to further accelerate GEMM for CNN inference, and in particular, structural sparsity has the advantages of predictable load balancing and very low index overhead. In this paper, we address a key architectural challenge with structural sparsity: how to provide support for a range of sparsity levels while maintaining high utilization of the hardware. We describe a time unrolled formulation of variable density-bound block (VDBB) sparsity that allows for a configurable number of non-zero elements per block, at constant utilization. We then describe a systolic array microarchitecture that implements this scheme, with two data reuse optimizations. Firstly, we increase reuse in both operands and partial products by increasing the number of MACs per PE. Secondly, we introduce a novel approach of moving the IM2COL transform into the hardware, which allows us to achieve a 3x data bandwidth expansion just before the operands are consumed by the datapath, reducing the SRAM power consumption. The optimizations for weight sparsity, activation sparsity and data reuse are all interrelated and therefore the optimal combination is not obvious. Therefore, we perform an design space evaluation to find the pareto-optimal design characteristics. The resulting design achieves 16.8 TOPS/W in 16nm with modest 50% model sparsity and scales with model sparsity up to 55.7TOPS/W at 87.5%. As well as successfully demonstrating the variable DBB technique, this result significantly outperforms previously reported sparse CNN accelerators.
TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids
May 20, 2020
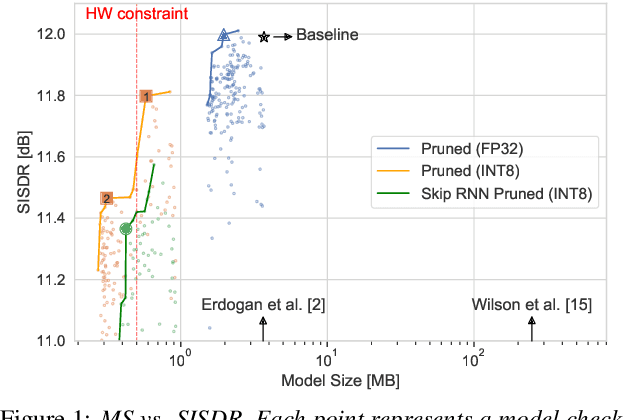
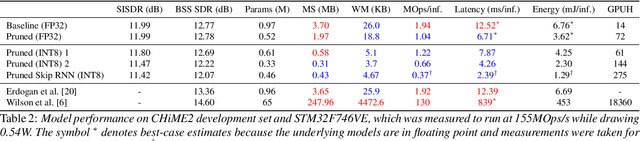
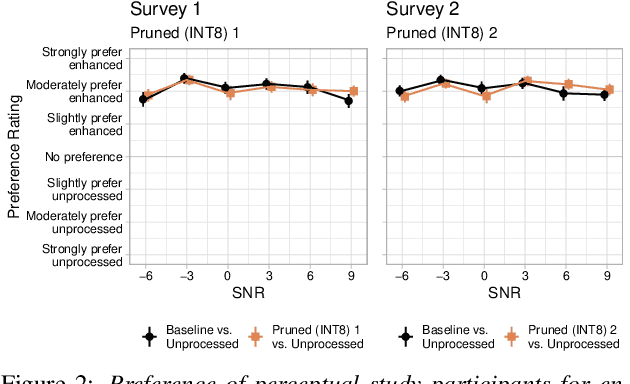
Modern speech enhancement algorithms achieve remarkable noise suppression by means of large recurrent neural networks (RNNs). However, large RNNs limit practical deployment in hearing aid hardware (HW) form-factors, which are battery powered and run on resource-constrained microcontroller units (MCUs) with limited memory capacity and compute capability. In this work, we use model compression techniques to bridge this gap. We define the constraints imposed on the RNN by the HW and describe a method to satisfy them. Although model compression techniques are an active area of research, we are the first to demonstrate their efficacy for RNN speech enhancement, using pruning and integer quantization of weights/activations. We also demonstrate state update skipping, which reduces the computational load. Finally, we conduct a perceptual evaluation of the compressed models to verify audio quality on human raters. Results show a reduction in model size and operations of 11.9$\times$ and 2.9$\times$, respectively, over the baseline for compressed models, without a statistical difference in listening preference and only exhibiting a loss of 0.55dB SDR. Our model achieves a computational latency of 2.39ms, well within the 10ms target and 351$\times$ better than previous work.