 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalog Foundation Models
May 14, 2025Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models .
Kernel Approximation using Analog In-Memory Computing
Nov 05, 2024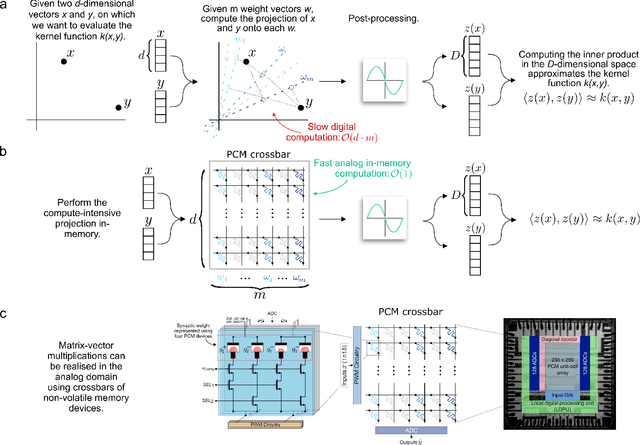
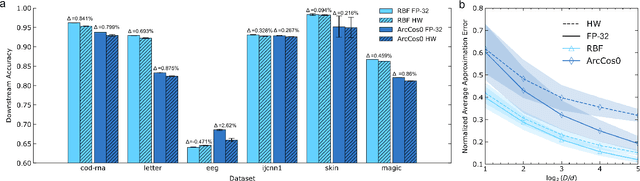
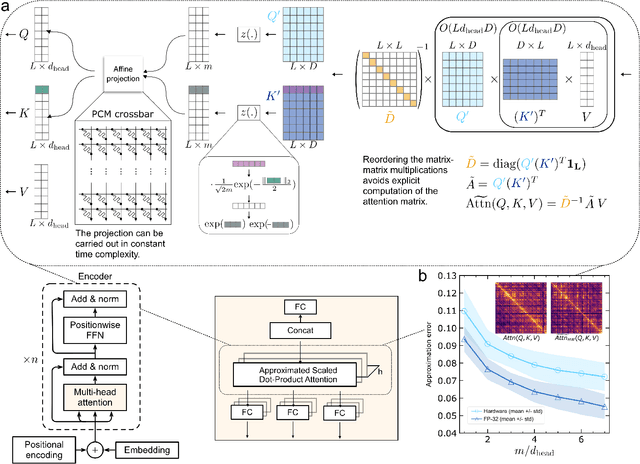
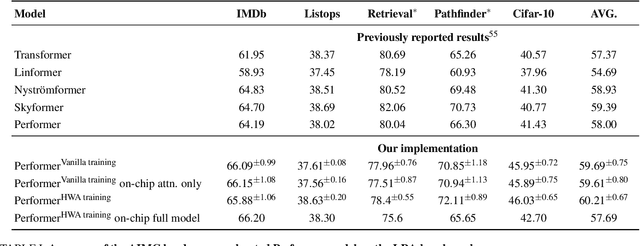
Kernel functions are vital ingredients of several machine learning algorithms, but often incur significant memory and computational costs. We introduce an approach to kernel approximation in machine learning algorithms suitable for mixed-signal Analog In-Memory Computing (AIMC) architectures. Analog In-Memory Kernel Approximation addresses the performance bottlenecks of conventional kernel-based methods by executing most operations in approximate kernel methods directly in memory. The IBM HERMES Project Chip, a state-of-the-art phase-change memory based AIMC chip, is utilized for the hardware demonstration of kernel approximation. Experimental results show that our method maintains high accuracy, with less than a 1% drop in kernel-based ridge classification benchmarks and within 1% accuracy on the Long Range Arena benchmark for kernelized attention in Transformer neural networks. Compared to traditional digital accelerators, our approach is estimated to deliver superior energy efficiency and lower power consumption. These findings highlight the potential of heterogeneous AIMC architectures to enhance the efficiency and scalability of machine learning applications.
In-Materia Speech Recognition
Oct 14, 2024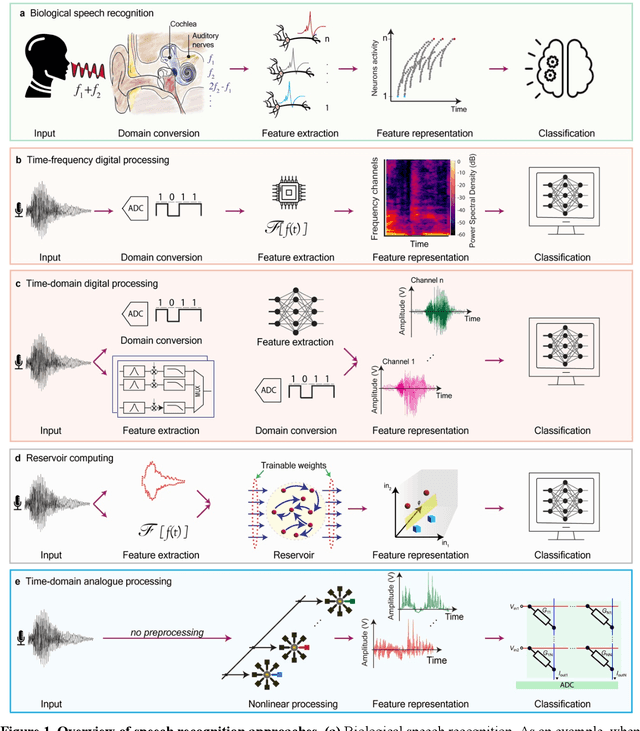
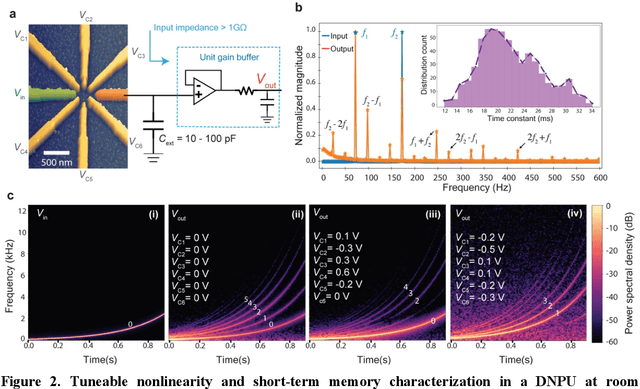
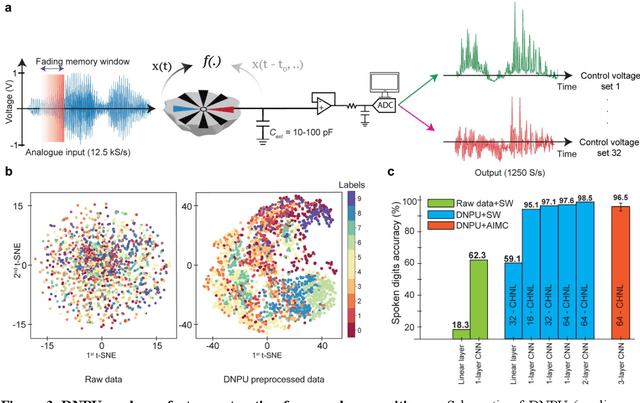
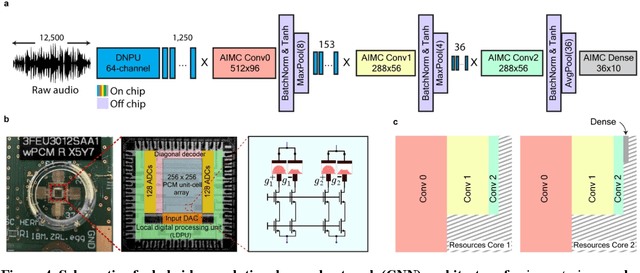
With the rise of decentralized computing, as in the Internet of Things, autonomous driving, and personalized healthcare, it is increasingly important to process time-dependent signals at the edge efficiently: right at the place where the temporal data are collected, avoiding time-consuming, insecure, and costly communication with a centralized computing facility (or cloud). However, modern-day processors often cannot meet the restrained power and time budgets of edge systems because of intrinsic limitations imposed by their architecture (von Neumann bottleneck) or domain conversions (analogue-to-digital and time-to-frequency). Here, we propose an edge temporal-signal processor based on two in-materia computing systems for both feature extraction and classification, reaching a software-level accuracy of 96.2% for the TI-46-Word speech-recognition task. First, a nonlinear, room-temperature dopant-network-processing-unit (DNPU) layer realizes analogue, time-domain feature extraction from the raw audio signals, similar to the human cochlea. Second, an analogue in-memory computing (AIMC) chip, consisting of memristive crossbar arrays, implements a compact neural network trained on the extracted features for classification. With the DNPU feature extraction consuming 100s nW and AIMC-based classification having the potential for less than 10 fJ per multiply-accumulate operation, our findings offer a promising avenue for advancing the compactness, efficiency, and performance of heterogeneous smart edge processors through in-materia computing hardware.
AnalogNets: ML-HW Co-Design of Noise-robust TinyML Models and Always-On Analog Compute-in-Memory Accelerator
Nov 10, 2021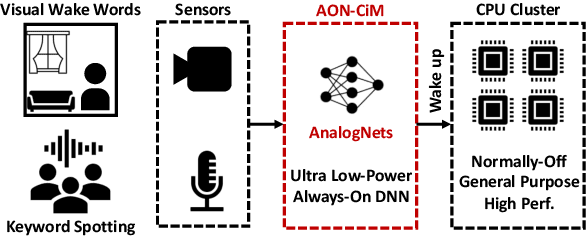
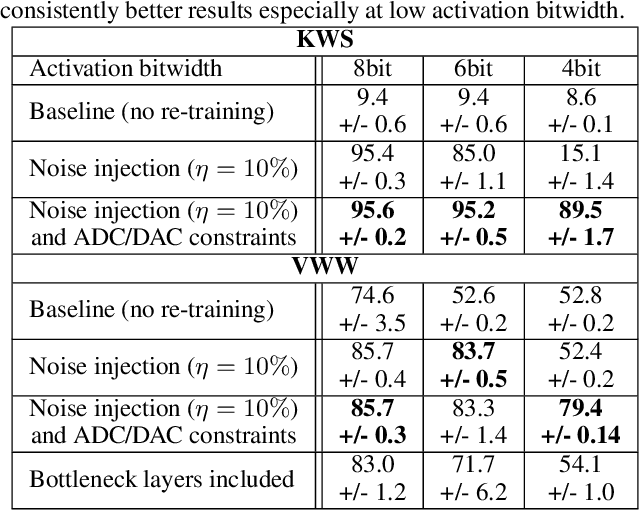
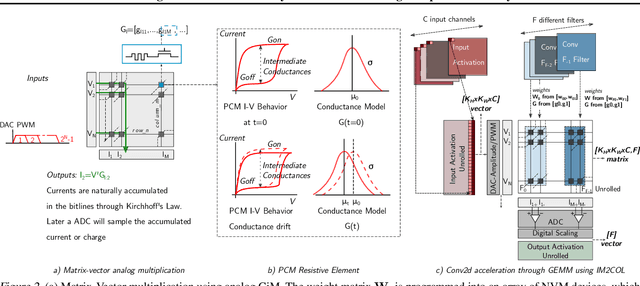
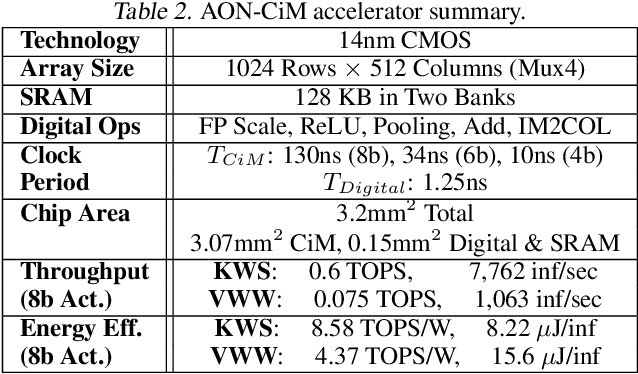
Always-on TinyML perception tasks in IoT applications require very high energy efficiency. Analog compute-in-memory (CiM) using non-volatile memory (NVM) promises high efficiency and also provides self-contained on-chip model storage. However, analog CiM introduces new practical considerations, including conductance drift, read/write noise, fixed analog-to-digital (ADC) converter gain, etc. These additional constraints must be addressed to achieve models that can be deployed on analog CiM with acceptable accuracy loss. This work describes $\textit{AnalogNets}$: TinyML models for the popular always-on applications of keyword spotting (KWS) and visual wake words (VWW). The model architectures are specifically designed for analog CiM, and we detail a comprehensive training methodology, to retain accuracy in the face of analog non-idealities, and low-precision data converters at inference time. We also describe AON-CiM, a programmable, minimal-area phase-change memory (PCM) analog CiM accelerator, with a novel layer-serial approach to remove the cost of complex interconnects associated with a fully-pipelined design. We evaluate the AnalogNets on a calibrated simulator, as well as real hardware, and find that accuracy degradation is limited to 0.8$\%$/1.2$\%$ after 24 hours of PCM drift (8-bit) for KWS/VWW. AnalogNets running on the 14nm AON-CiM accelerator demonstrate 8.58/4.37 TOPS/W for KWS/VWW workloads using 8-bit activations, respectively, and increasing to 57.39/25.69 TOPS/W with $4$-bit activations.
Adversarial Attacks on Spiking Convolutional Networks for Event-based Vision
Oct 06, 2021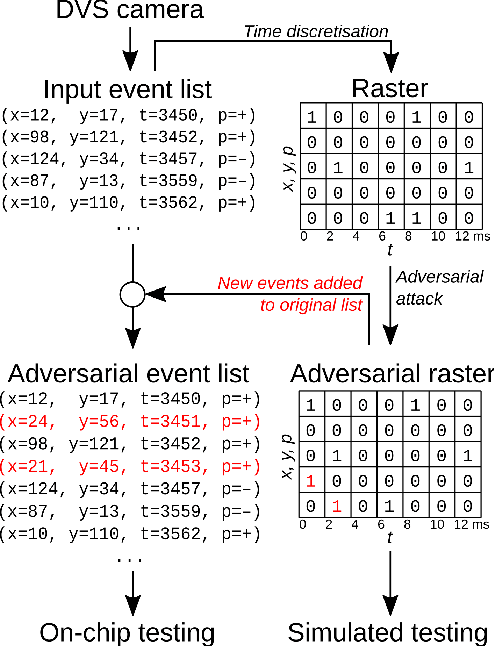
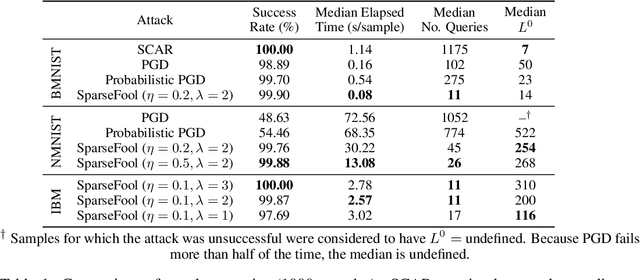


Event-based sensing using dynamic vision sensors is gaining traction in low-power vision applications. Spiking neural networks work well with the sparse nature of event-based data and suit deployment on low-power neuromorphic hardware. Being a nascent field, the sensitivity of spiking neural networks to potentially malicious adversarial attacks has received very little attention so far. In this work, we show how white-box adversarial attack algorithms can be adapted to the discrete and sparse nature of event-based visual data, and to the continuous-time setting of spiking neural networks. We test our methods on the N-MNIST and IBM Gestures neuromorphic vision datasets and show adversarial perturbations achieve a high success rate, by injecting a relatively small number of appropriately placed events. We also verify, for the first time, the effectiveness of these perturbations directly on neuromorphic hardware. Finally, we discuss the properties of the resulting perturbations and possible future directions.
Network insensitivity to parameter noise via adversarial regularization
Jun 22, 2021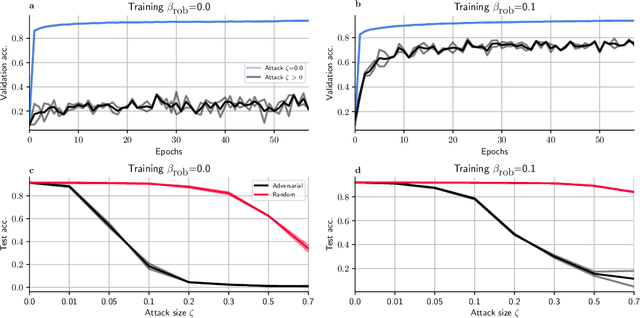
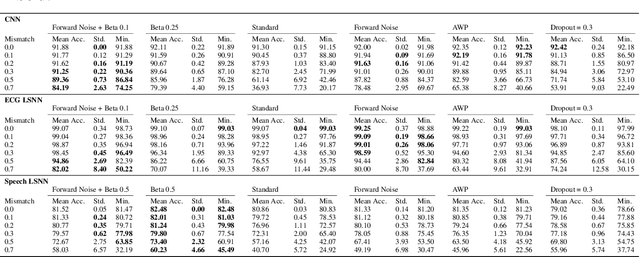

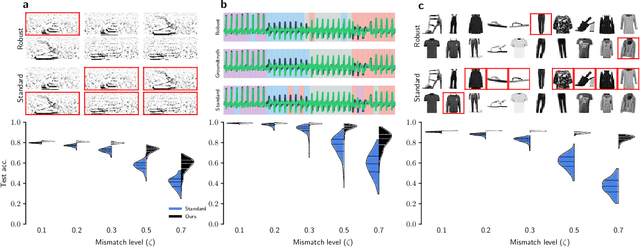
Neuromorphic neural network processors, in the form of compute-in-memory crossbar arrays of memristors, or in the form of subthreshold analog and mixed-signal ASICs, promise enormous advantages in compute density and energy efficiency for NN-based ML tasks. However, these technologies are prone to computational non-idealities, due to process variation and intrinsic device physics. This degrades the task performance of networks deployed to the processor, by introducing parameter noise into the deployed model. While it is possible to calibrate each device, or train networks individually for each processor, these approaches are expensive and impractical for commercial deployment. Alternative methods are therefore needed to train networks that are inherently robust against parameter variation, as a consequence of network architecture and parameters. We present a new adversarial network optimisation algorithm that attacks network parameters during training, and promotes robust performance during inference in the face of parameter variation. Our approach introduces a regularization term penalising the susceptibility of a network to weight perturbation. We compare against previous approaches for producing parameter insensitivity such as dropout, weight smoothing and introducing parameter noise during training. We show that our approach produces models that are more robust to targeted parameter variation, and equally robust to random parameter variation. Our approach finds minima in flatter locations in the weight-loss landscape compared with other approaches, highlighting that the networks found by our technique are less sensitive to parameter perturbation. Our work provides an approach to deploy neural network architectures to inference devices that suffer from computational non-idealities, with minimal loss of performance. ...
Supervised training of spiking neural networks for robust deployment on mixed-signal neuromorphic processors
Feb 17, 2021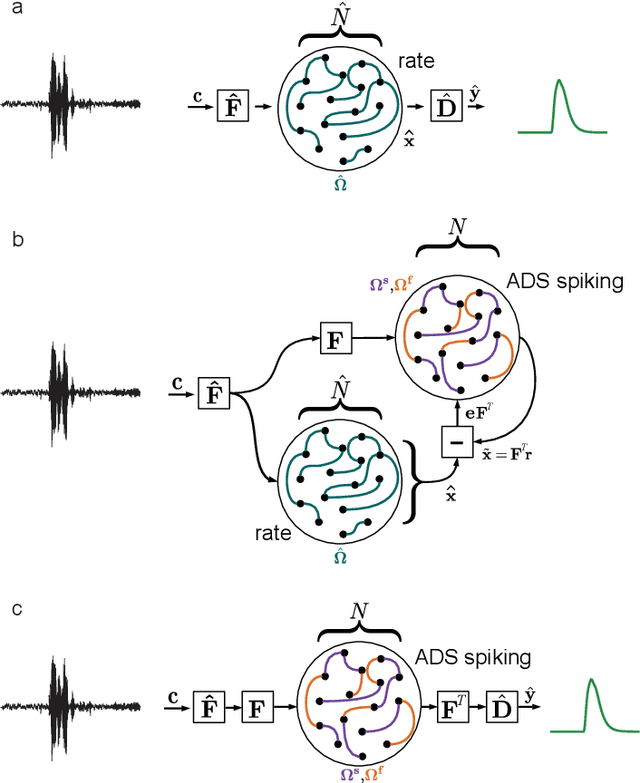
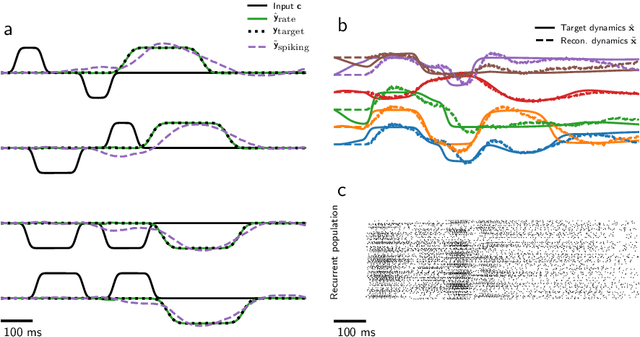
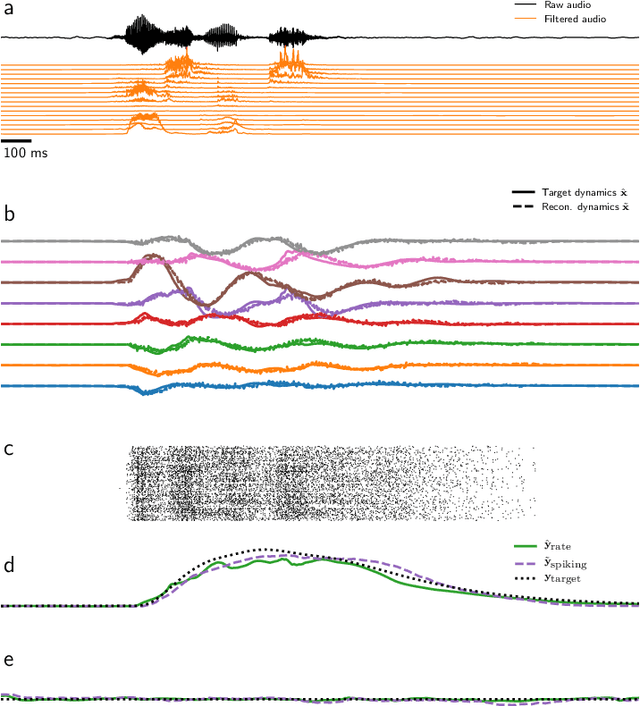
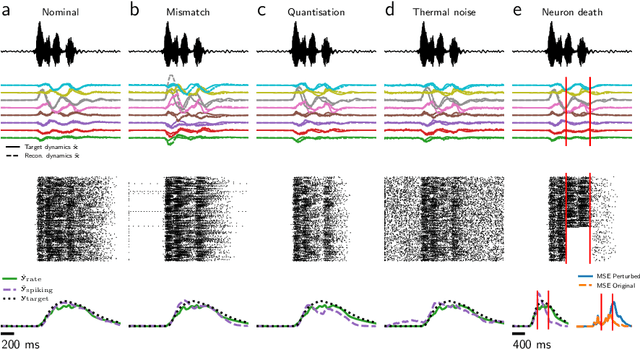
Mixed-signal analog/digital circuits can emulate spiking neurons and synapses with extremely high energy efficiency, an approach known as "neuromorphic engineering". However, analog circuits are sensitive to process-induced variation among transistors in a chip ("device mismatch"). For neuromorphic implementation of Spiking Neural Networks (SNNs), mismatch causes parameter variation between identically-configured neurons and synapses. Each chip therefore exhibits a different distribution of neural parameters, causing deployed networks to respond differently between chips. Current solutions to mitigate mismatch based on per-chip calibration or on-chip learning entail increased design complexity, area and cost, making deployment of neuromorphic devices expensive and difficult. Here we present a supervised learning approach that addresses this challenge by maximizing robustness to mismatch and other common sources of noise. Our method trains SNNs to perform temporal classification tasks by mimicking a pre-trained dynamical system, using a local learning rule adapted from non-linear control theory. We demonstrate our method on two tasks requiring memory, and measure the robustness of our approach to several forms of noise and mismatch. We show that our approach is more robust than several common alternatives for training SNNs. Our method provides a viable way to robustly deploy pre-trained networks on mixed-signal neuromorphic hardware, without requiring per-device training or calibration.
Implementing efficient balanced networks with mixed-signal spike-based learning circuits
Oct 27, 2020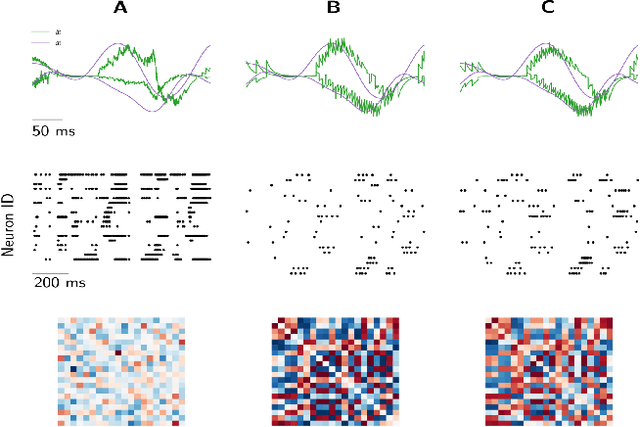
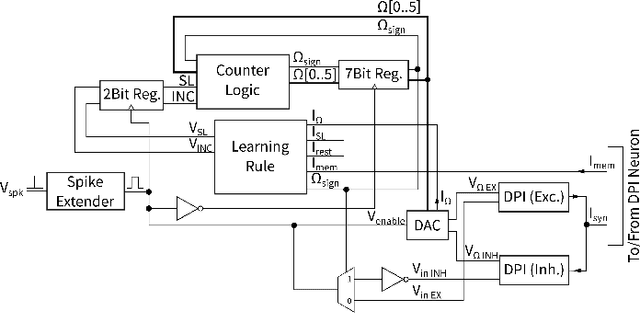
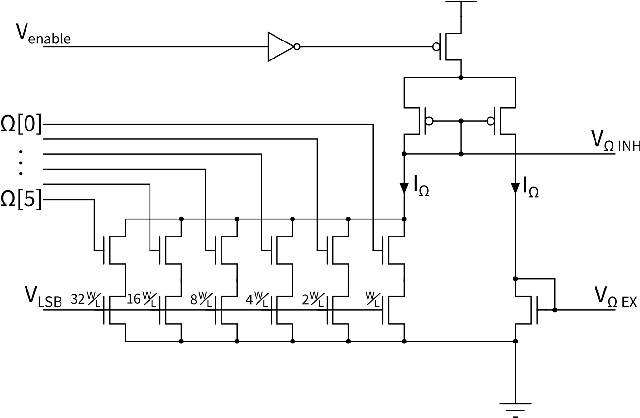
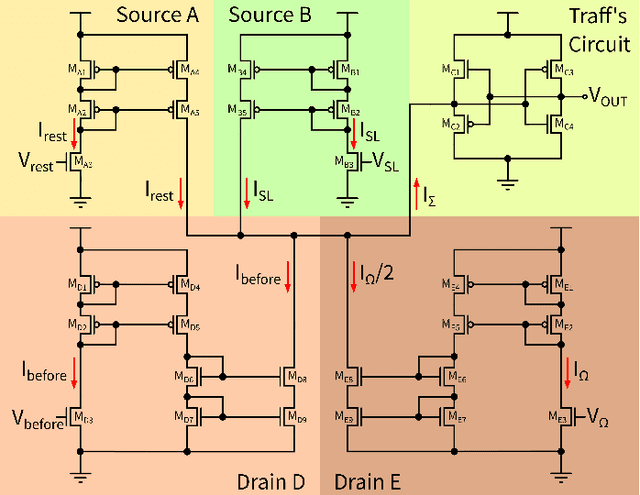
Efficient Balanced Networks (EBNs) are networks of spiking neurons in which excitatory and inhibitory synaptic currents are balanced on a short timescale, leading to desirable coding properties such as high encoding precision, low firing rates, and distributed information representation. It is for these benefits that it would be desirable to implement such networks in low-power neuromorphic processors. However, the degree of device mismatch in analog mixed-signal neuromorphic circuits renders the use of pre-trained EBNs challenging, if not impossible. To overcome this issue, we developed a novel local learning rule suitable for on-chip implementation that drives a randomly connected network of spiking neurons into a tightly balanced regime. Here we present the integrated circuits that implement this rule and demonstrate their expected behaviour in low-level circuit simulations. Our proposed method paves the way towards a system-level implementation of tightly balanced networks on analog mixed-signal neuromorphic hardware. Thanks to their coding properties and sparse activity, neuromorphic electronic EBNs will be ideally suited for extreme-edge computing applications that require low-latency, ultra-low power consumption and which cannot rely on cloud computing for data processing.
Ladder Networks for Semi-Supervised Hyperspectral Image Classification
Dec 04, 2018
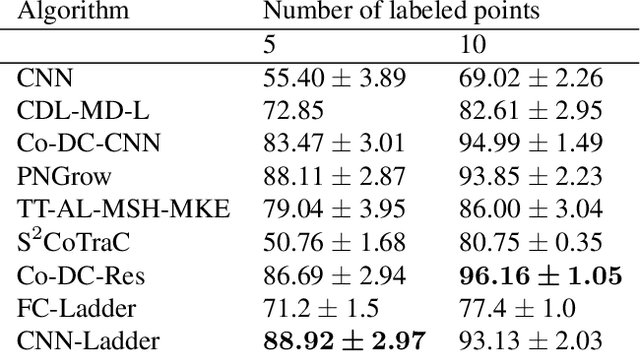
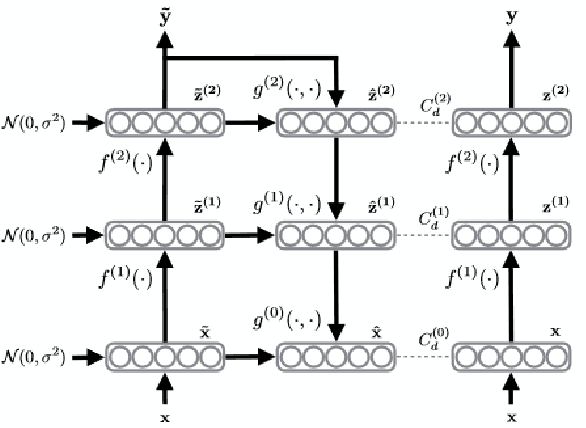
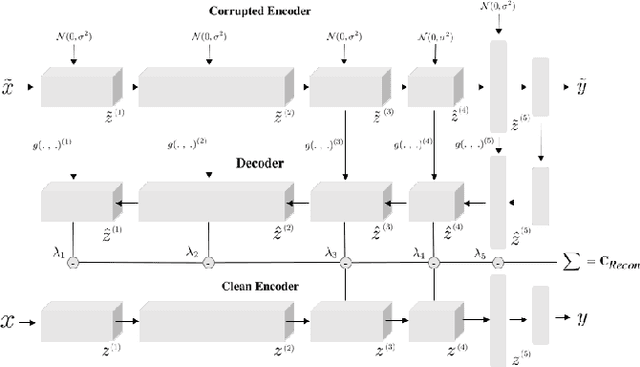
We used the Ladder Network [Rasmus et al. (2015)] to perform Hyperspectral Image Classification in a semi-supervised setting. The Ladder Network distinguishes itself from other semi-supervised methods by jointly optimizing a supervised and unsupervised cost. In many settings this has proven to be more successful than other semi-supervised techniques, such as pretraining using unlabeled data. We furthermore show that the convolutional Ladder Network outperforms most of the current techniques used in hyperspectral image classification and achieves new state-of-the-art performance on the Pavia University dataset given only 5 labeled data points per class.