 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel, Self Organizing, Consensus Neural Networks
Jul 30, 2020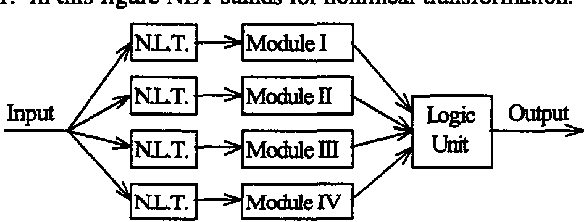
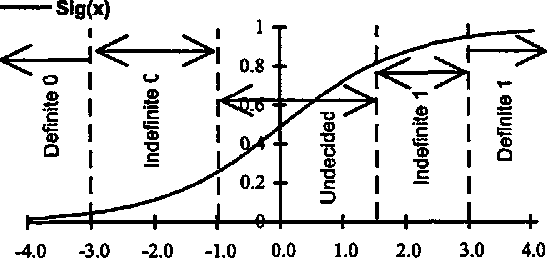
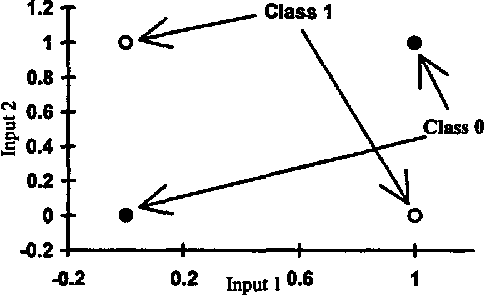
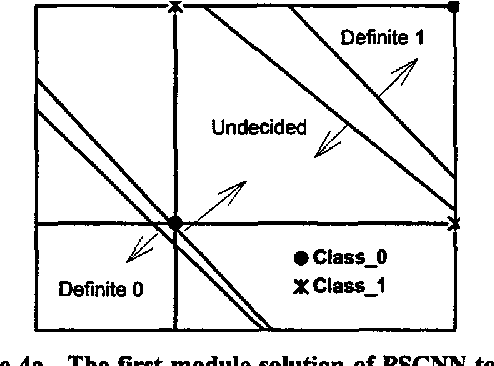
A new neural network architecture (PSCNN) is developed to improve performance and speed of such networks. The architecture has all the advantages of the previous models such as self-organization and possesses some other superior characteristics such as input parallelism and decision making based on consensus. Due to the properties of this network, it was studied with respect to implementation on a Parallel Processor (Ncube Machine) as well as a regular sequential machine. The architecture self organizes its own modules in a way to maximize performance. Since it is completely parallel, both recall and learning procedures are very fast. The performance of the network was compared to the Backpropagation networks in problems of language perception, remote sensing and binary logic (Exclusive-Or). PSCNN showed superior performance in all cases studied.
* 4 pages
Probabilistic Diagnostic Tests for Degradation Problems in Supervised Learning
Apr 15, 2020
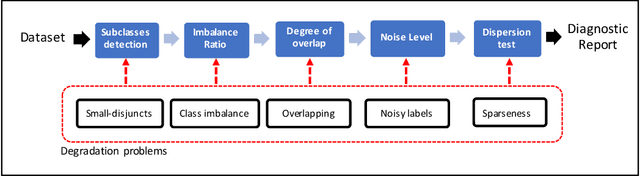
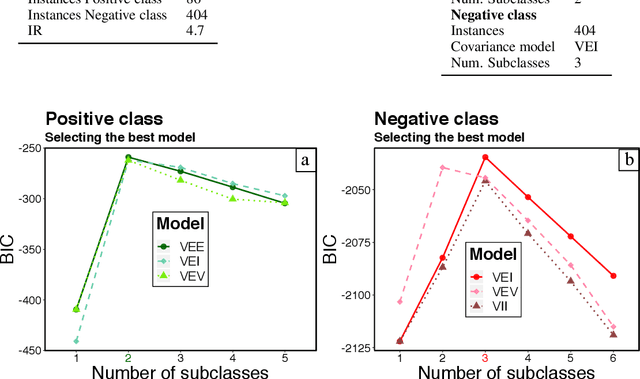
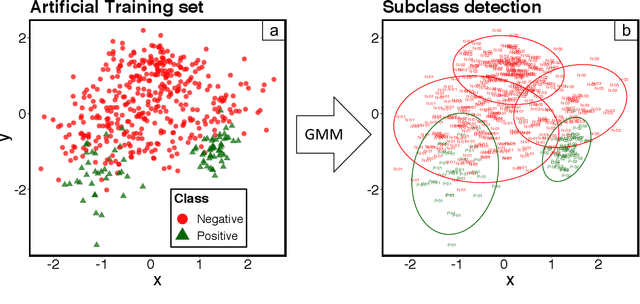
Several studies point out different causes of performance degradation in supervised machine learning. Problems such as class imbalance, overlapping, small-disjuncts, noisy labels, and sparseness limit accuracy in classification algorithms. Even though a number of approaches either in the form of a methodology or an algorithm try to minimize performance degradation, they have been isolated efforts with limited scope. Most of these approaches focus on remediation of one among many problems, with experimental results coming from few datasets and classification algorithms, insufficient measures of prediction power, and lack of statistical validation for testing the real benefit of the proposed approach. This paper consists of two main parts: In the first part, a novel probabilistic diagnostic model based on identifying signs and symptoms of each problem is presented. Thereby, early and correct diagnosis of these problems is to be achieved in order to select not only the most convenient remediation treatment but also unbiased performance metrics. Secondly, the behavior and performance of several supervised algorithms are studied when training sets have such problems. Therefore, prediction of success for treatments can be estimated across classifiers.
Ladder Networks for Semi-Supervised Hyperspectral Image Classification
Dec 04, 2018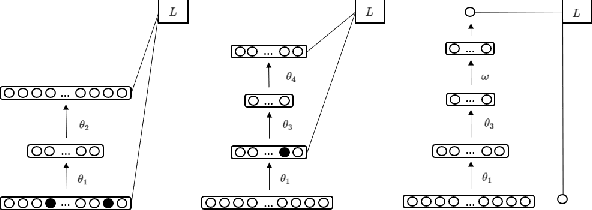
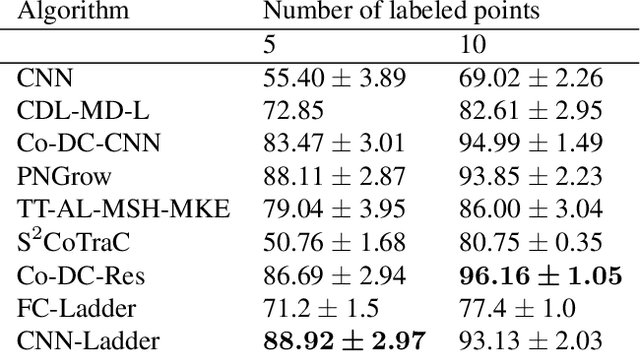
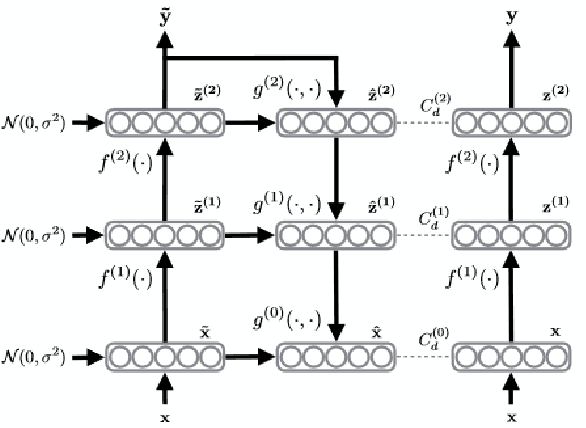
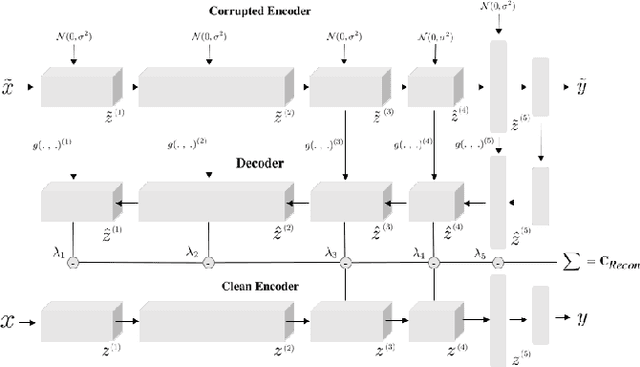
We used the Ladder Network [Rasmus et al. (2015)] to perform Hyperspectral Image Classification in a semi-supervised setting. The Ladder Network distinguishes itself from other semi-supervised methods by jointly optimizing a supervised and unsupervised cost. In many settings this has proven to be more successful than other semi-supervised techniques, such as pretraining using unlabeled data. We furthermore show that the convolutional Ladder Network outperforms most of the current techniques used in hyperspectral image classification and achieves new state-of-the-art performance on the Pavia University dataset given only 5 labeled data points per class.
A Statistical Approach to Increase Classification Accuracy in Supervised Learning Algorithms
Sep 05, 2017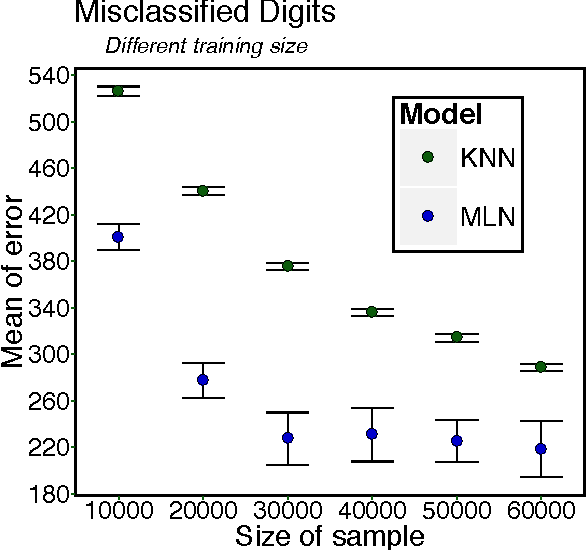
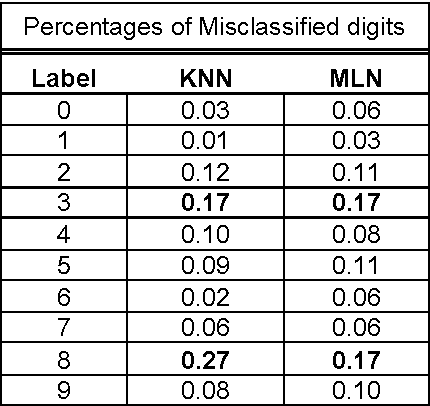
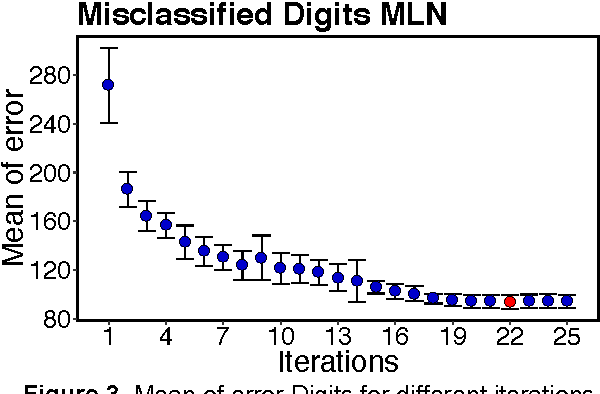
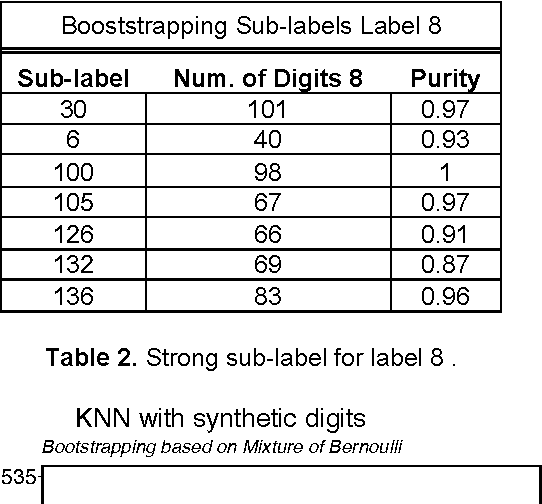
Probabilistic mixture models have been widely used for different machine learning and pattern recognition tasks such as clustering, dimensionality reduction, and classification. In this paper, we focus on trying to solve the most common challenges related to supervised learning algorithms by using mixture probability distribution functions. With this modeling strategy, we identify sub-labels and generate synthetic data in order to reach better classification accuracy. It means we focus on increasing the training data synthetically to increase the classification accuracy.
* 7 pages, 9 figures, IPSI BgD Transactions