Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Approach to Increase Classification Accuracy in Supervised Learning Algorithms
Sep 05, 2017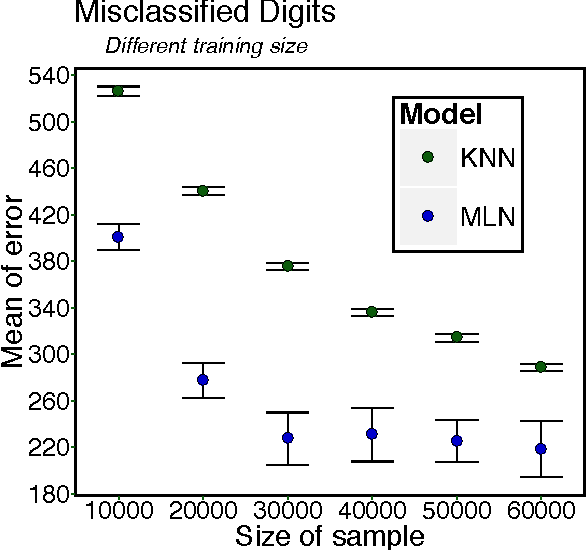
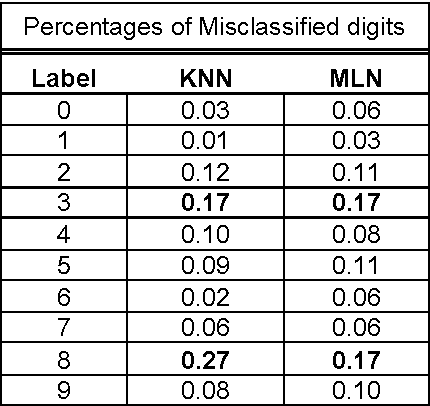
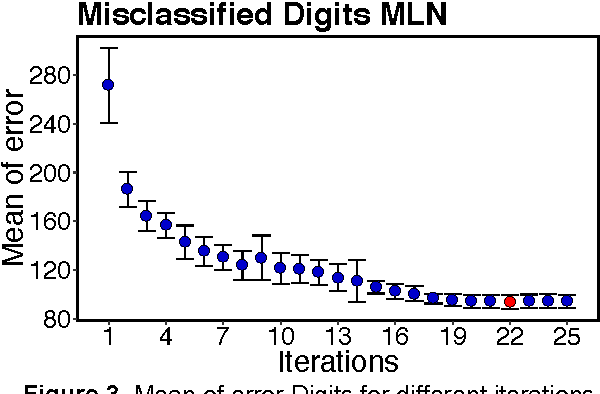
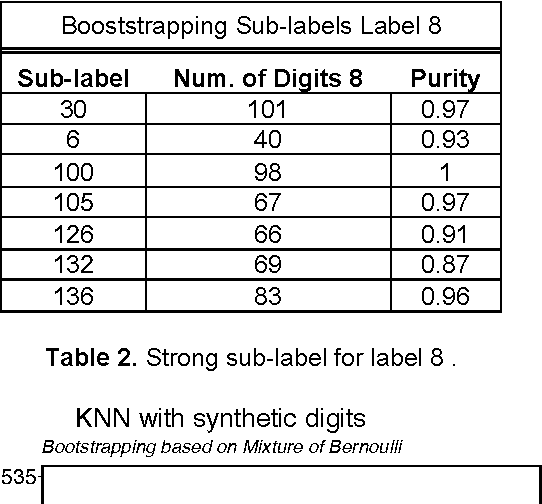
Probabilistic mixture models have been widely used for different machine learning and pattern recognition tasks such as clustering, dimensionality reduction, and classification. In this paper, we focus on trying to solve the most common challenges related to supervised learning algorithms by using mixture probability distribution functions. With this modeling strategy, we identify sub-labels and generate synthetic data in order to reach better classification accuracy. It means we focus on increasing the training data synthetically to increase the classification accuracy.
* PSI BGD TRANSACTIONS ON INTERNET RESEARCH 13.2 (2017)
* 7 pages, 9 figures, IPSI BgD Transactions
* 7 pages, 9 figures, IPSI BgD Transactions
Via