 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Performance of Analog Training for Transfer Learning
May 16, 2025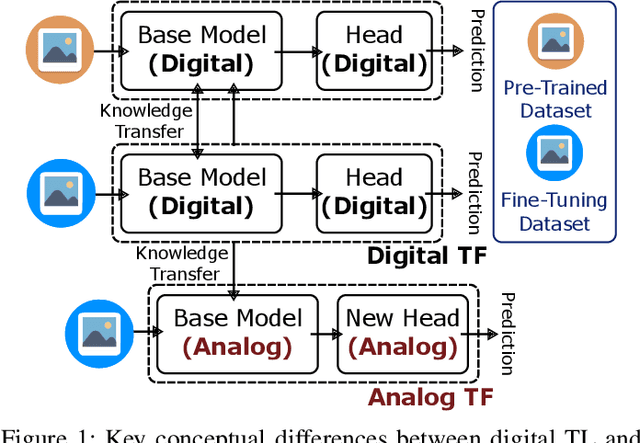
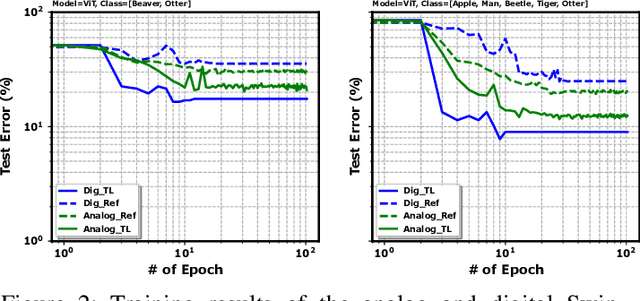
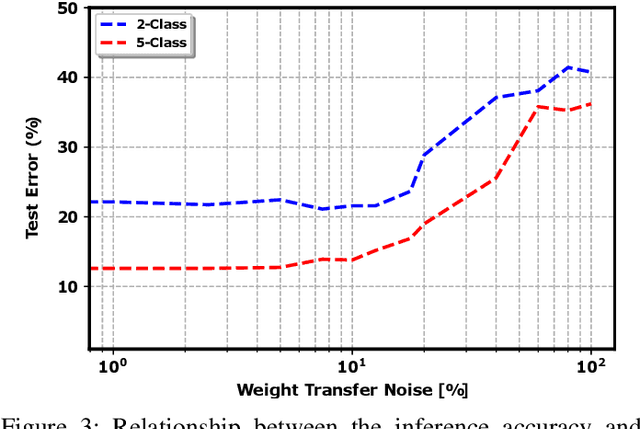
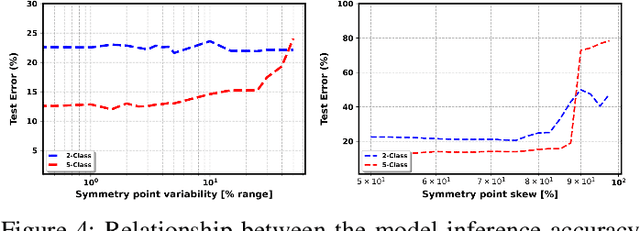
Analog in-memory computing is a next-generation computing paradigm that promises fast, parallel, and energy-efficient deep learning training and transfer learning (TL). However, achieving this promise has remained elusive due to a lack of suitable training algorithms. Analog memory devices exhibit asymmetric and non-linear switching behavior in addition to device-to-device variation, meaning that most, if not all, of the current off-the-shelf training algorithms cannot achieve good training outcomes. Also, recently introduced algorithms have enjoyed limited attention, as they require bi-directionally switching devices of unrealistically high symmetry and precision and are highly sensitive. A new algorithm chopped TTv2 (c-TTv2), has been introduced, which leverages the chopped technique to address many of the challenges mentioned above. In this paper, we assess the performance of the c-TTv2 algorithm for analog TL using a Swin-ViT model on a subset of the CIFAR100 dataset. We also investigate the robustness of our algorithm to changes in some device specifications, including weight transfer noise, symmetry point skew, and symmetry point variability
Efficient Deployment of Transformer Models in Analog In-Memory Computing Hardware
Nov 26, 2024



Analog in-memory computing (AIMC) has emerged as a promising solution to overcome the von Neumann bottleneck, accelerating neural network computations and improving computational efficiency. While AIMC has demonstrated success with architectures such as CNNs, MLPs, and RNNs, deploying transformer-based models using AIMC presents unique challenges. Transformers are expected to handle diverse downstream tasks and adapt to new user data or instructions after deployment, which requires more flexible approaches to suit AIMC constraints. In this paper, we propose a novel method for deploying pre-trained transformer models onto AIMC hardware. Unlike traditional approaches requiring hardware-aware training, our technique allows direct deployment without the need for retraining the original model. Instead, we utilize lightweight, low-rank adapters -- compact modules stored in digital cores -- to adapt the model to hardware constraints. We validate our approach on MobileBERT, demonstrating accuracy on par with, or even exceeding, a traditional hardware-aware training approach. Our method is particularly appealing in multi-task scenarios, as it enables a single analog model to be reused across multiple tasks. Moreover, it supports on-chip adaptation to new hardware constraints and tasks without updating analog weights, providing a flexible and versatile solution for real-world AI applications. Code is available.
Kernel Approximation using Analog In-Memory Computing
Nov 05, 2024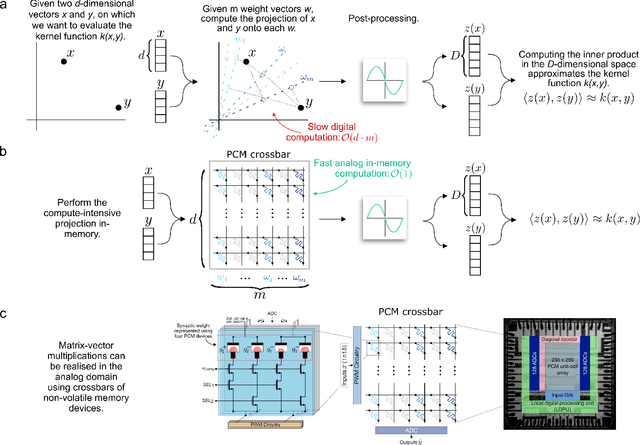
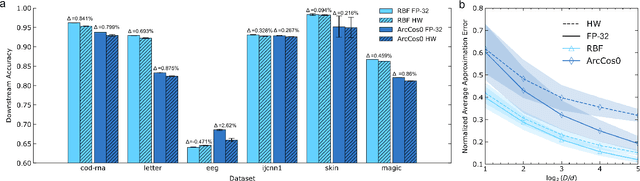
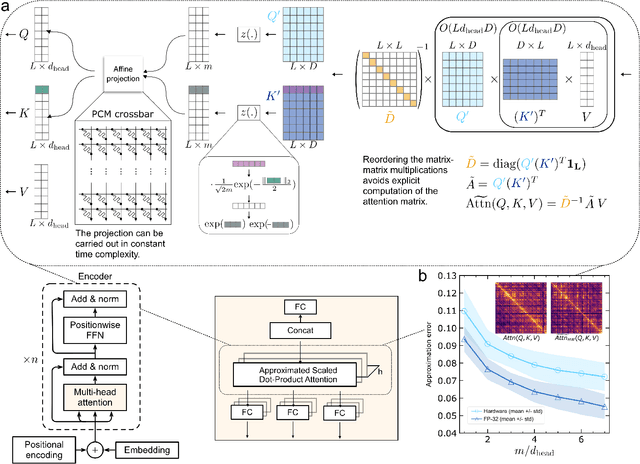
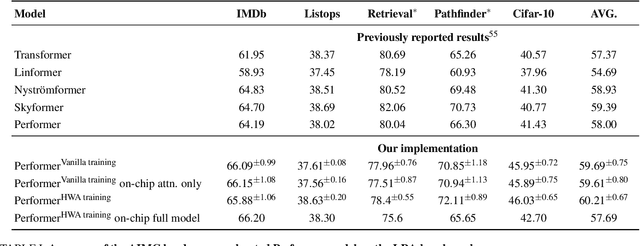
Kernel functions are vital ingredients of several machine learning algorithms, but often incur significant memory and computational costs. We introduce an approach to kernel approximation in machine learning algorithms suitable for mixed-signal Analog In-Memory Computing (AIMC) architectures. Analog In-Memory Kernel Approximation addresses the performance bottlenecks of conventional kernel-based methods by executing most operations in approximate kernel methods directly in memory. The IBM HERMES Project Chip, a state-of-the-art phase-change memory based AIMC chip, is utilized for the hardware demonstration of kernel approximation. Experimental results show that our method maintains high accuracy, with less than a 1% drop in kernel-based ridge classification benchmarks and within 1% accuracy on the Long Range Arena benchmark for kernelized attention in Transformer neural networks. Compared to traditional digital accelerators, our approach is estimated to deliver superior energy efficiency and lower power consumption. These findings highlight the potential of heterogeneous AIMC architectures to enhance the efficiency and scalability of machine learning applications.
A Precision-Optimized Fixed-Point Near-Memory Digital Processing Unit for Analog In-Memory Computing
Feb 12, 2024



Analog In-Memory Computing (AIMC) is an emerging technology for fast and energy-efficient Deep Learning (DL) inference. However, a certain amount of digital post-processing is required to deal with circuit mismatches and non-idealities associated with the memory devices. Efficient near-memory digital logic is critical to retain the high area/energy efficiency and low latency of AIMC. Existing systems adopt Floating Point 16 (FP16) arithmetic with limited parallelization capability and high latency. To overcome these limitations, we propose a Near-Memory digital Processing Unit (NMPU) based on fixed-point arithmetic. It achieves competitive accuracy and higher computing throughput than previous approaches while minimizing the area overhead. Moreover, the NMPU supports standard DL activation steps, such as ReLU and Batch Normalization. We perform a physical implementation of the NMPU design in a 14 nm CMOS technology and provide detailed performance, power, and area assessments. We validate the efficacy of the NMPU by using data from an AIMC chip and demonstrate that a simulated AIMC system with the proposed NMPU outperforms existing FP16-based implementations, providing 139$\times$ speed-up, 7.8$\times$ smaller area, and a competitive power consumption. Additionally, our approach achieves an inference accuracy of 86.65 %/65.06 %, with an accuracy drop of just 0.12 %/0.4 % compared to the FP16 baseline when benchmarked with ResNet9/ResNet32 networks trained on the CIFAR10/CIFAR100 datasets, respectively.
Using the IBM Analog In-Memory Hardware Acceleration Kit for Neural Network Training and Inference
Jul 18, 2023Analog In-Memory Computing (AIMC) is a promising approach to reduce the latency and energy consumption of Deep Neural Network (DNN) inference and training. However, the noisy and non-linear device characteristics, and the non-ideal peripheral circuitry in AIMC chips, require adapting DNNs to be deployed on such hardware to achieve equivalent accuracy to digital computing. In this tutorial, we provide a deep dive into how such adaptations can be achieved and evaluated using the recently released IBM Analog Hardware Acceleration Kit (AIHWKit), freely available at https://github.com/IBM/aihwkit. The AIHWKit is a Python library that simulates inference and training of DNNs using AIMC. We present an in-depth description of the AIHWKit design, functionality, and best practices to properly perform inference and training. We also present an overview of the Analog AI Cloud Composer, that provides the benefits of using the AIHWKit simulation platform in a fully managed cloud setting. Finally, we show examples on how users can expand and customize AIHWKit for their own needs. This tutorial is accompanied by comprehensive Jupyter Notebook code examples that can be run using AIHWKit, which can be downloaded from https://github.com/IBM/aihwkit/tree/master/notebooks/tutorial.
AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
May 17, 2023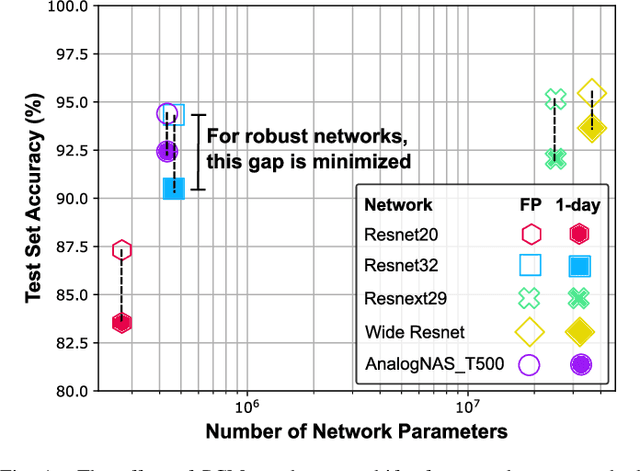
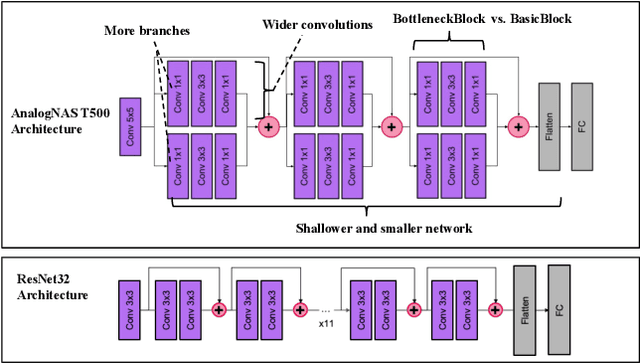
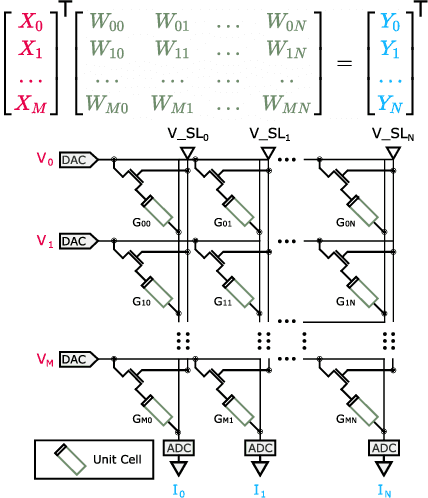
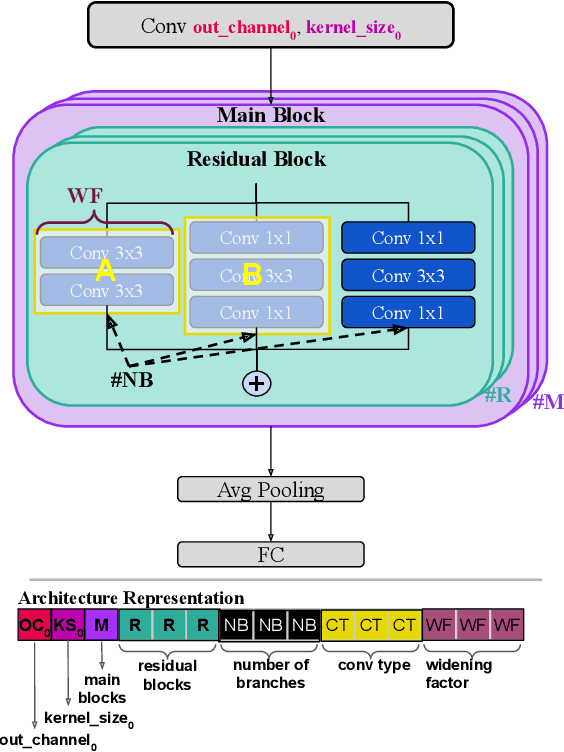
The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixed signal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased area and power efficiency, which are paramount in edge resource-constrained environments. In this paper, we propose AnalogNAS, a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released: https://github.com/IBM/analog-nas
Seizure Detection and Prediction by Parallel Memristive Convolutional Neural Networks
Jun 20, 2022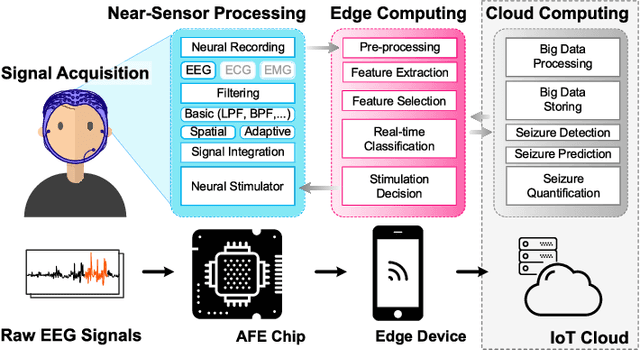
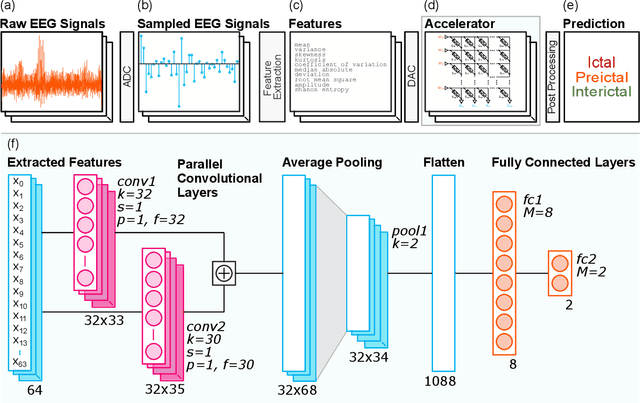
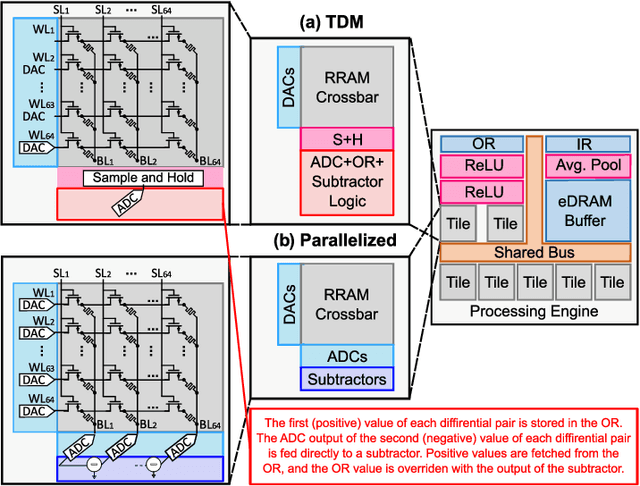
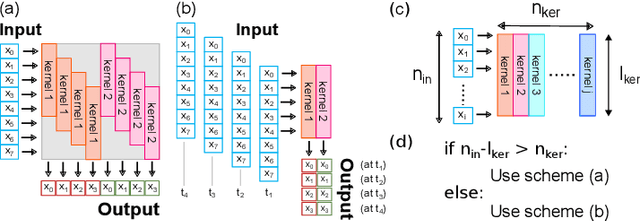
During the past two decades, epileptic seizure detection and prediction algorithms have evolved rapidly. However, despite significant performance improvements, their hardware implementation using conventional technologies, such as Complementary Metal-Oxide-Semiconductor (CMOS), in power and area-constrained settings remains a challenging task; especially when many recording channels are used. In this paper, we propose a novel low-latency parallel Convolutional Neural Network (CNN) architecture that has between 2-2,800x fewer network parameters compared to SOTA CNN architectures and achieves 5-fold cross validation accuracy of 99.84% for epileptic seizure detection, and 99.01% and 97.54% for epileptic seizure prediction, when evaluated using the University of Bonn Electroencephalogram (EEG), CHB-MIT and SWEC-ETHZ seizure datasets, respectively. We subsequently implement our network onto analog crossbar arrays comprising Resistive Random-Access Memory (RRAM) devices, and provide a comprehensive benchmark by simulating, laying out, and determining hardware requirements of the CNN component of our system. To the best of our knowledge, we are the first to parallelize the execution of convolution layer kernels on separate analog crossbars to enable 2 orders of magnitude reduction in latency compared to SOTA hybrid Memristive-CMOS DL accelerators. Furthermore, we investigate the effects of non-idealities on our system and investigate Quantization Aware Training (QAT) to mitigate the performance degradation due to low ADC/DAC resolution. Finally, we propose a stuck weight offsetting methodology to mitigate performance degradation due to stuck RON/ROFF memristor weights, recovering up to 32% accuracy, without requiring retraining. The CNN component of our platform is estimated to consume approximately 2.791W of power while occupying an area of 31.255mm$^2$ in a 22nm FDSOI CMOS process.
* Accepted by IEEE Transactions on Biomedical Circuits and Systems
Toward A Formalized Approach for Spike Sorting Algorithms and Hardware Evaluation
May 13, 2022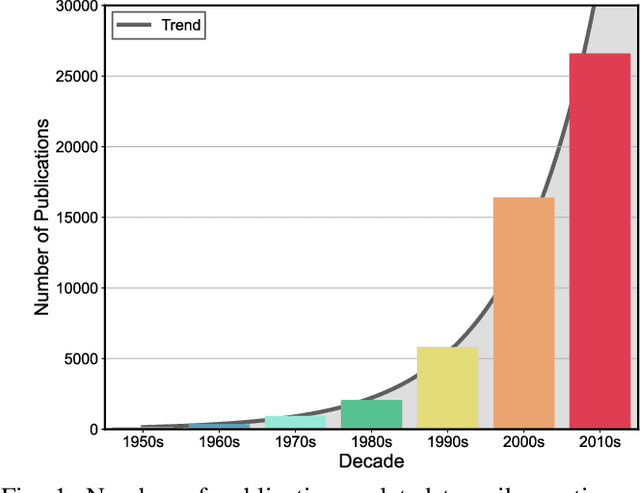
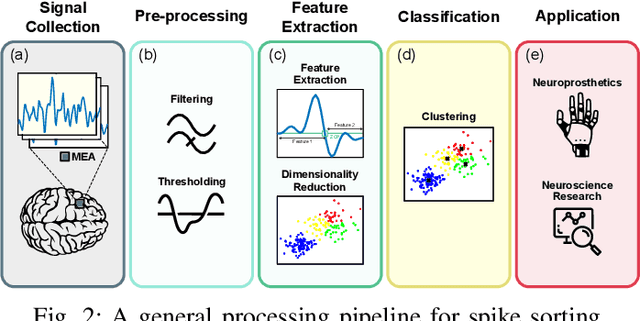
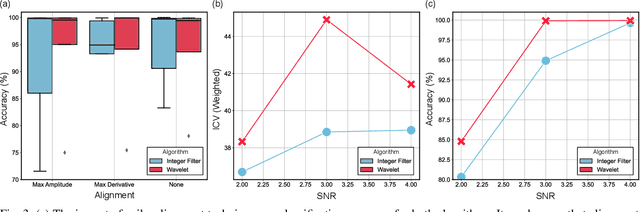
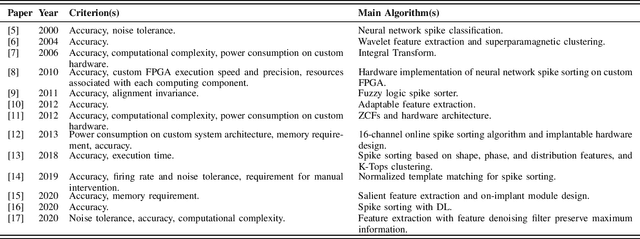
Spike sorting algorithms are used to separate extracellular recordings of neuronal populations into single-unit spike activities. The development of customized hardware implementing spike sorting algorithms is burgeoning. However, there is a lack of a systematic approach and a set of standardized evaluation criteria to facilitate direct comparison of both software and hardware implementations. In this paper, we formalize a set of standardized criteria and a publicly available synthetic dataset entitled Synthetic Simulations Of Extracellular Recordings (SSOER), which was constructed by aggregating existing synthetic datasets with varying Signal-To-Noise Ratios (SNRs). Furthermore, we present a benchmark for future comparison, and use our criteria to evaluate a simulated Resistive Random-Access Memory (RRAM) In-Memory Computing (IMC) system using the Discrete Wavelet Transform (DWT) for feature extraction. Our system consumes approximately (per channel) 10.72mW and occupies an area of 0.66mm$^2$ in a 22nm FDSOI Complementary Metal-Oxide-Semiconductor (CMOS) process.
Navigating Local Minima in Quantized Spiking Neural Networks
Feb 15, 2022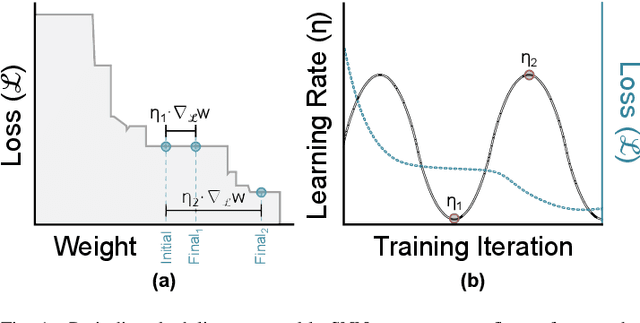
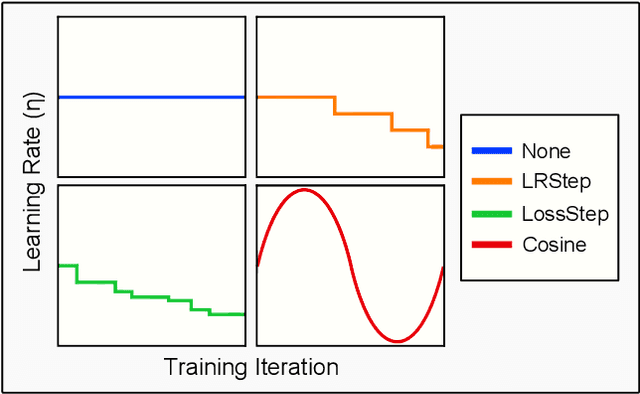
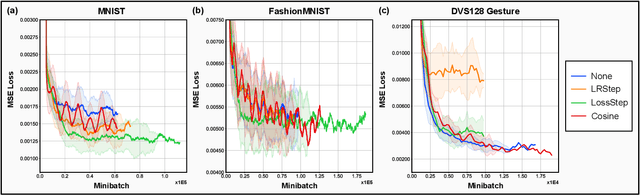
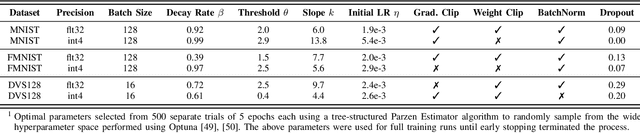
Spiking and Quantized Neural Networks (NNs) are becoming exceedingly important for hyper-efficient implementations of Deep Learning (DL) algorithms. However, these networks face challenges when trained using error backpropagation, due to the absence of gradient signals when applying hard thresholds. The broadly accepted trick to overcoming this is through the use of biased gradient estimators: surrogate gradients which approximate thresholding in Spiking Neural Networks (SNNs), and Straight-Through Estimators (STEs), which completely bypass thresholding in Quantized Neural Networks (QNNs). While noisy gradient feedback has enabled reasonable performance on simple supervised learning tasks, it is thought that such noise increases the difficulty of finding optima in loss landscapes, especially during the later stages of optimization. By periodically boosting the Learning Rate (LR) during training, we expect the network can navigate unexplored solution spaces that would otherwise be difficult to reach due to local minima, barriers, or flat surfaces. This paper presents a systematic evaluation of a cosine-annealed LR schedule coupled with weight-independent adaptive moment estimation as applied to Quantized SNNs (QSNNs). We provide a rigorous empirical evaluation of this technique on high precision and 4-bit quantized SNNs across three datasets, demonstrating (close to) state-of-the-art performance on the more complex datasets. Our source code is available at this link: https://github.com/jeshraghian/QSNNs.
Design Space Exploration of Dense and Sparse Mapping Schemes for RRAM Architectures
Jan 25, 2022The impact of device and circuit-level effects in mixed-signal Resistive Random Access Memory (RRAM) accelerators typically manifest as performance degradation of Deep Learning (DL) algorithms, but the degree of impact varies based on algorithmic features. These include network architecture, capacity, weight distribution, and the type of inter-layer connections. Techniques are continuously emerging to efficiently train sparse neural networks, which may have activation sparsity, quantization, and memristive noise. In this paper, we present an extended Design Space Exploration (DSE) methodology to quantify the benefits and limitations of dense and sparse mapping schemes for a variety of network architectures. While sparsity of connectivity promotes less power consumption and is often optimized for extracting localized features, its performance on tiled RRAM arrays may be more susceptible to noise due to under-parameterization, when compared to dense mapping schemes. Moreover, we present a case study quantifying and formalizing the trade-offs of typical non-idealities introduced into 1-Transistor-1-Resistor (1T1R) tiled memristive architectures and the size of modular crossbar tiles using the CIFAR-10 dataset.