 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Device Fine-Tuning via Backprop-Free Zeroth-Order Optimization
Nov 14, 2025On-device fine-tuning is a critical capability for edge AI systems, which must support adaptation to different agentic tasks under stringent memory constraints. Conventional backpropagation (BP)-based training requires storing layer activations and optimizer states, a demand that can be only partially alleviated through checkpointing. In edge deployments in which the model weights must reside entirely in device memory, this overhead severely limits the maximum model size that can be deployed. Memory-efficient zeroth-order optimization (MeZO) alleviates this bottleneck by estimating gradients using forward evaluations alone, eliminating the need for storing intermediate activations or optimizer states. This enables significantly larger models to fit within on-chip memory, albeit at the cost of potentially longer fine-tuning wall-clock time. This paper first provides a theoretical estimate of the relative model sizes that can be accommodated under BP and MeZO training. We then numerically validate the analysis, demonstrating that MeZO exhibits accuracy advantages under on-device memory constraints, provided sufficient wall-clock time is available for fine-tuning.
Stochastic Quantum Spiking Neural Networks with Quantum Memory and Local Learning
Jun 26, 2025Neuromorphic and quantum computing have recently emerged as promising paradigms for advancing artificial intelligence, each offering complementary strengths. Neuromorphic systems built on spiking neurons excel at processing time-series data efficiently through sparse, event-driven computation, consuming energy only upon input events. Quantum computing, on the other hand, leverages superposition and entanglement to explore feature spaces that are exponentially large in the number of qubits. Hybrid approaches combining these paradigms have begun to show potential, but existing quantum spiking models have important limitations. Notably, prior quantum spiking neuron implementations rely on classical memory mechanisms on single qubits, requiring repeated measurements to estimate firing probabilities, and they use conventional backpropagation on classical simulators for training. Here we propose a stochastic quantum spiking (SQS) neuron model that addresses these challenges. The SQS neuron uses multi-qubit quantum circuits to realize a spiking unit with internal quantum memory, enabling event-driven probabilistic spike generation in a single shot. Furthermore, we outline how networks of SQS neurons -- dubbed SQS neural networks (SQSNNs) -- can be trained via a hardware-friendly local learning rule, eliminating the need for global classical backpropagation. The proposed SQSNN model fuses the time-series efficiency of neuromorphic computing with the exponentially large inner state space of quantum computing, paving the way for quantum spiking neural networks that are modular, scalable, and trainable on quantum hardware.
Turbo-ICL: In-Context Learning-Based Turbo Equalization
May 09, 2025This paper introduces a novel in-context learning (ICL) framework, inspired by large language models (LLMs), for soft-input soft-output channel equalization in coded multiple-input multiple-output (MIMO) systems. The proposed approach learns to infer posterior symbol distributions directly from a prompt of pilot signals and decoder feedback. A key innovation is the use of prompt augmentation to incorporate extrinsic information from the decoder output as additional context, enabling the ICL model to refine its symbol estimates iteratively across turbo decoding iterations. Two model variants, based on Transformer and state-space architectures, are developed and evaluated. Extensive simulations demonstrate that, when traditional linear assumptions break down, e.g., in the presence of low-resolution quantization, ICL equalizers consistently outperform conventional model-based baselines, even when the latter are provided with perfect channel state information. Results also highlight the advantage of Transformer-based models under limited training diversity, as well as the efficiency of state-space models in resource-constrained scenarios.
Closed-Form Feedback-Free Learning with Forward Projection
Jan 27, 2025State-of-the-art methods for backpropagation-free learning employ local error feedback to direct iterative optimisation via gradient descent. In this study, we examine the more restrictive setting where retrograde communication from neuronal outputs is unavailable for pre-synaptic weight optimisation. To address this challenge, we propose Forward Projection (FP). This novel randomised closed-form training method requires only a single forward pass over the entire dataset for model fitting, without retrograde communication. Target values for pre-activation membrane potentials are generated layer-wise via nonlinear projections of pre-synaptic inputs and the labels. Local loss functions are optimised over pre-synaptic inputs using closed-form regression, without feedback from neuronal outputs or downstream layers. Interpretability is a key advantage of FP training; membrane potentials of hidden neurons in FP-trained networks encode information which is interpretable layer-wise as label predictions. We demonstrate the effectiveness of FP across four biomedical datasets. In few-shot learning tasks, FP yielded more generalisable models than those optimised via backpropagation. In large-sample tasks, FP-based models achieve generalisation comparable to gradient descent-based local learning methods while requiring only a single forward propagation step, achieving significant speed up for training. Interpretation functions defined on local neuronal activity in FP-based models successfully identified clinically salient features for diagnosis in two biomedical datasets. Forward Projection is a computationally efficient machine learning approach that yields interpretable neural network models without retrograde communication of neuronal activity during training.
Efficient Deployment of Transformer Models in Analog In-Memory Computing Hardware
Nov 26, 2024



Analog in-memory computing (AIMC) has emerged as a promising solution to overcome the von Neumann bottleneck, accelerating neural network computations and improving computational efficiency. While AIMC has demonstrated success with architectures such as CNNs, MLPs, and RNNs, deploying transformer-based models using AIMC presents unique challenges. Transformers are expected to handle diverse downstream tasks and adapt to new user data or instructions after deployment, which requires more flexible approaches to suit AIMC constraints. In this paper, we propose a novel method for deploying pre-trained transformer models onto AIMC hardware. Unlike traditional approaches requiring hardware-aware training, our technique allows direct deployment without the need for retraining the original model. Instead, we utilize lightweight, low-rank adapters -- compact modules stored in digital cores -- to adapt the model to hardware constraints. We validate our approach on MobileBERT, demonstrating accuracy on par with, or even exceeding, a traditional hardware-aware training approach. Our method is particularly appealing in multi-task scenarios, as it enables a single analog model to be reused across multiple tasks. Moreover, it supports on-chip adaptation to new hardware constraints and tasks without updating analog weights, providing a flexible and versatile solution for real-world AI applications. Code is available.
Neuromorphic Wireless Split Computing with Multi-Level Spikes
Nov 07, 2024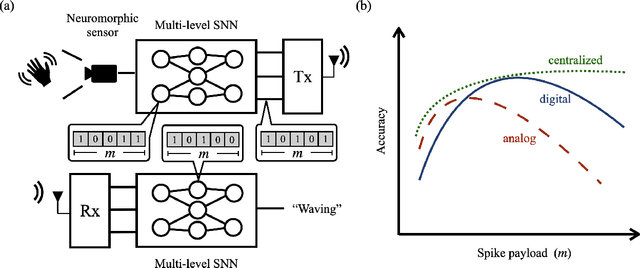
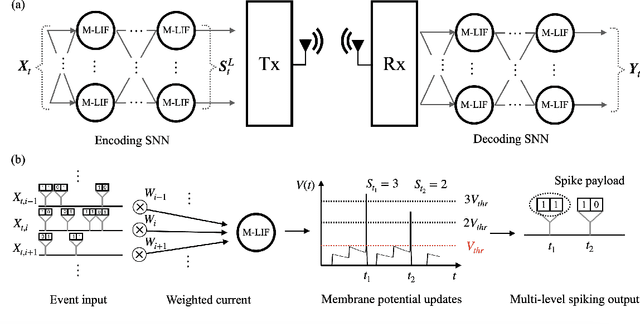
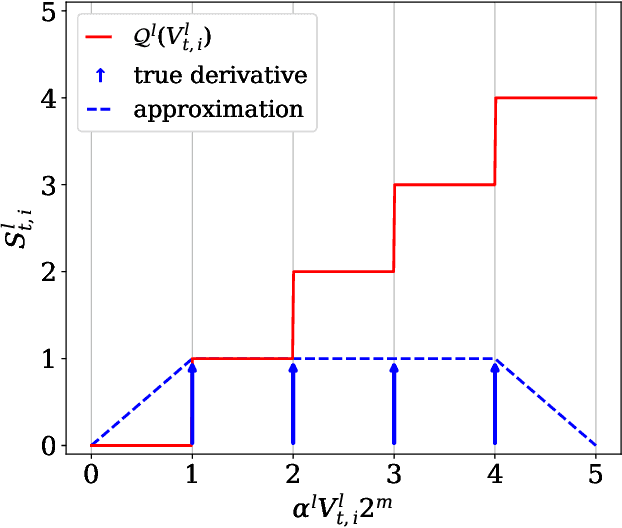
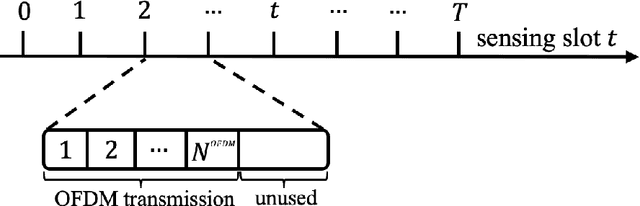
Inspired by biological processes, neuromorphic computing utilizes spiking neural networks (SNNs) to perform inference tasks, offering significant efficiency gains for workloads involving sequential data. Recent advances in hardware and software have demonstrated that embedding a few bits of payload in each spike exchanged between the spiking neurons can further enhance inference accuracy. In a split computing architecture, where the SNN is divided across two separate devices, the device storing the first layers must share information about the spikes generated by the local output neurons with the other device. Consequently, the advantages of multi-level spikes must be balanced against the challenges of transmitting additional bits between the two devices. This paper addresses these challenges by investigating a wireless neuromorphic split computing architecture employing multi-level SNNs. For this system, we present the design of digital and analog modulation schemes optimized for an orthogonal frequency division multiplexing (OFDM) radio interface. Simulation and experimental results using software-defined radios provide insights into the performance gains of multi-level SNN models and the optimal payload size as a function of the quality of the connection between a transmitter and receiver.
In-Context Learned Equalization in Cell-Free Massive MIMO via State-Space Models
Oct 31, 2024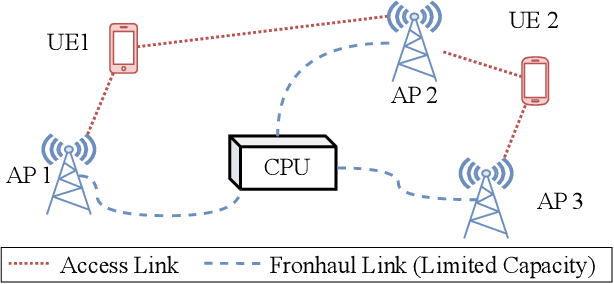
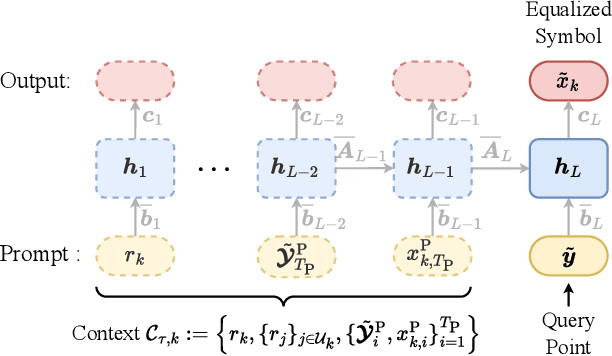
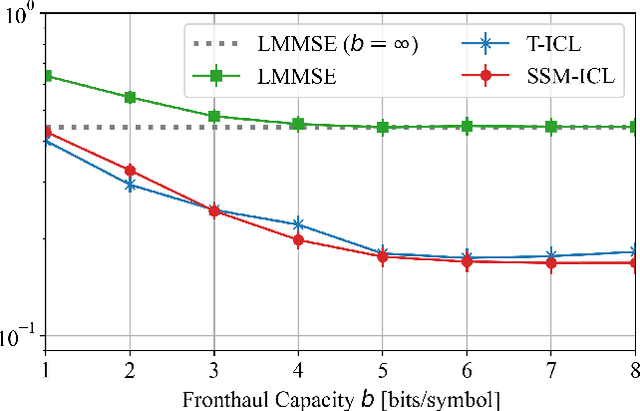
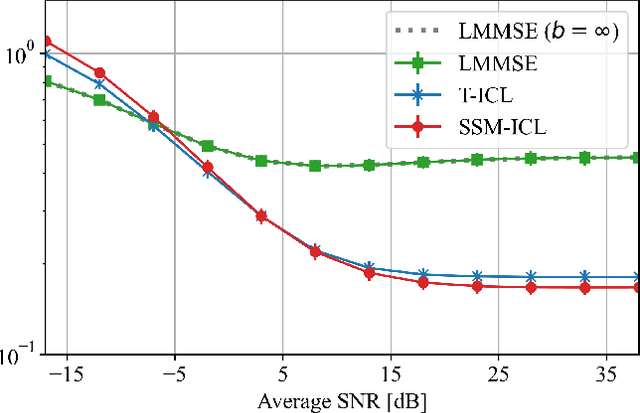
Sequence models have demonstrated the ability to perform tasks like channel equalization and symbol detection by automatically adapting to current channel conditions. This is done without requiring any explicit optimization and by leveraging not only short pilot sequences but also contextual information such as long-term channel statistics. The operating principle underlying automatic adaptation is in-context learning (ICL), an emerging property of sequence models. Prior art adopted transformer-based sequence models, which, however, have a computational complexity scaling quadratically with the context length due to batch processing. Recently, state-space models (SSMs) have emerged as a more efficient alternative, affording a linear inference complexity in the context size. This work explores the potential of SSMs for ICL-based equalization in cell-free massive MIMO systems. Results show that selective SSMs achieve comparable performance to transformer-based models while requiring approximately eight times fewer parameters and five times fewer floating-point operations.
Baseline Drift Tolerant Signal Encoding for ECG Classification with Deep Learning
Apr 26, 2024



Common artefacts such as baseline drift, rescaling, and noise critically limit the performance of machine learningbased automated ECG analysis and interpretation. This study proposes Derived Peak (DP) encoding, a non-parametric method that generates signed spikes corresponding to zero crossings of the signals first and second-order time derivatives. Notably, DP encoding is invariant to shift and scaling artefacts, and its implementation is further simplified by the absence of userdefined parameters. DP encoding was used to encode the 12-lead ECG data from the PTB-XL dataset (n=18,869 participants) and was fed to 1D-ResNet-18 models trained to identify myocardial infarction, conductive deficits and ST-segment abnormalities. Robustness to artefacts was assessed by corrupting ECG data with sinusoidal baseline drift, shift, rescaling and noise, before encoding. The addition of these artefacts resulted in a significant drop in accuracy for seven other methods from prior art, while DP encoding maintained a baseline AUC of 0.88 under drift, shift and rescaling. DP achieved superior performance to unencoded inputs in the presence of shift (AUC under 1mV shift: 0.91 vs 0.62), and rescaling artefacts (AUC 0.91 vs 0.79). Thus, DP encoding is a simple method by which robustness to common ECG artefacts may be improved for automated ECG analysis and interpretation.
Neuromorphic In-Context Learning for Energy-Efficient MIMO Symbol Detection
Apr 09, 2024


In-context learning (ICL), a property demonstrated by transformer-based sequence models, refers to the automatic inference of an input-output mapping based on examples of the mapping provided as context. ICL requires no explicit learning, i.e., no explicit updates of model weights, directly mapping context and new input to the new output. Prior work has proved the usefulness of ICL for detection in MIMO channels. In this setting, the context is given by pilot symbols, and ICL automatically adapts a detector, or equalizer, to apply to newly received signals. However, the implementation tested in prior art was based on conventional artificial neural networks (ANNs), which may prove too energy-demanding to be run on mobile devices. This paper evaluates a neuromorphic implementation of the transformer for ICL-based MIMO detection. This approach replaces ANNs with spiking neural networks (SNNs), and implements the attention mechanism via stochastic computing, requiring no multiplications, but only logical AND operations and counting. When using conventional digital CMOS hardware, the proposed implementation is shown to preserve accuracy, with a reduction in power consumption ranging from $5.4\times$ to $26.8\times$, depending on the model sizes, as compared to ANN-based implementations.
Stochastic Spiking Attention: Accelerating Attention with Stochastic Computing in Spiking Networks
Feb 14, 2024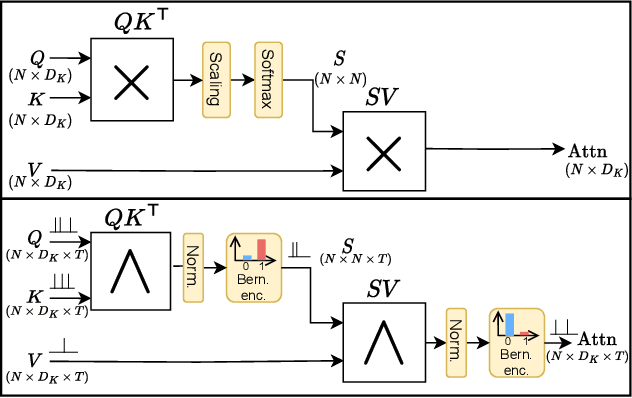
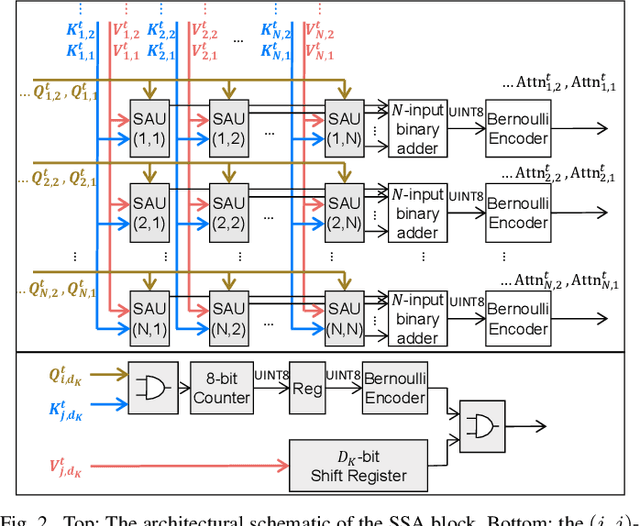

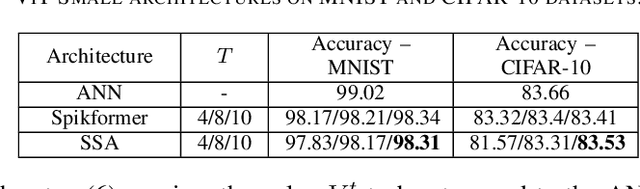
Spiking Neural Networks (SNNs) have been recently integrated into Transformer architectures due to their potential to reduce computational demands and to improve power efficiency. Yet, the implementation of the attention mechanism using spiking signals on general-purpose computing platforms remains inefficient. In this paper, we propose a novel framework leveraging stochastic computing (SC) to effectively execute the dot-product attention for SNN-based Transformers. We demonstrate that our approach can achieve high classification accuracy ($83.53\%$) on CIFAR-10 within 10 time steps, which is comparable to the performance of a baseline artificial neural network implementation ($83.66\%$). We estimate that the proposed SC approach can lead to over $6.3\times$ reduction in computing energy and $1.7\times$ reduction in memory access costs for a digital CMOS-based ASIC design. We experimentally validate our stochastic attention block design through an FPGA implementation, which is shown to achieve $48\times$ lower latency as compared to a GPU implementation, while consuming $15\times$ less power.